MySQLのパフォーマンス改善(パーティショニング)
MySQLでのパフォーマンス改善は大規模なデータではない場合は、通常インデックスを利用することで大体は改善が行えます。
ただし、データ量が大規模になる場合などはインデックスだけでは厳しい場合もあるのでなにか対応があるのか調べる必要性が発生しました。今回はパーティショニングというものを調べたので、技術メモとして記載していきます。
いままでSQLでパフォーマンス改善をするお仕事を数回してましたが、データ量が膨大なテーブルでインデックスだけでは厳しい部分がでてきたのでこの機会に検証をしました。
MySQLのパーティショニングとは
テーブル上のデータをルールを決めて分割し、そもそもデータアクセスが最小限で行えるようにするための機構です。
インデックスと異なる点は、インデックスはあくまで指定されたフィールドでの検索を効率よく行えるするように索引を作るような機能だが、パーティショニングはテーブルを分割し、そこにデータを振り分けます。
範囲データの参照時になど不要なデータが精査対象ではなくなるため、効率化が図れます。
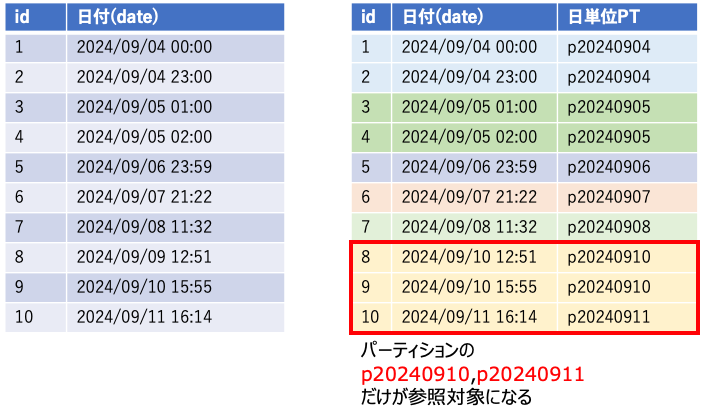
イメージ図
例えば以下のような日付データが格納されたログデータを参照する必要があるとき、日単位のパーティション{p日付}を作って置くことで、参照するデータは3件のみを対象とすることができ、インデックス以上に効率よくデータアクセスができることになります。
SQL
SELECT
count(*)
FROM
test_log_table_partition
WHERE
date between '2024-09-10 00:00:00' and '2024-09-11 23:59:59'
上記SQLの実行計画を取るとpartitionsに参照されたパーティションだけが対象となっていることがわかる。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | test_log_table_partition | p20240910,p20240911 | index | PRIMARY,idx_log_level,idx_customer | idx_log_level | 1 | 140011 | 11.11 | Using where; Using index |
メリット/デメリット
以下にパーティションを利用した場合のメリット・デメリットを整理します。
メリット
- データアクセスが全データを参照する必要がないため、高速化+負荷減少が図れる
- Where句で日付を指定するのではなく、パーティションをそのまま指定することもできる。更に高速化も可能
- ログデータなどで一定期間保持し削除する場合などもパーティションを指定して消すなども可能。Where句指定で消すより高速だと思われる
デメリット
- パーティショニングの設定を行うには対象のキーがPrimaryKeyに入っていないとできない。ここ大事…既存システムの場合、修正大変
- パーティションはデータを入れ込む前に作っておく必要がある。(日次バッチなどで作ることが必要)
- 管理が大変。(作成する処理がコケた場合なども検討しておかないと振り分けできないとかがある) パーティション作成時にルール外のデータをいれるパーティションを作って置くことで回避はできる
- 1TBLの最大パーティション数は8192まで、ルール決めが大事
実際にパーティショニングを試した速度調査
前提準備
想定として、ログデータを管理することを目的としたテーブルを作成します。
このテーブルはcustomer_id毎に参照される想定で、日付範囲を指定して検索することを想定しています。
以下、準備段階から手順を記載しています。
インデックスすら貼ってないテーブル
| フィールド | 型 | PKey |
|---|---|---|
| id | INT AUTO_INCREMENT | ★ |
| customer_id | INT | |
| date | DATETIME | |
| log_level | ENUM | |
| log_data | TEXT |
CREATE TABLE test_log_table (
id int NOT NULL AUTO_INCREMENT,
customer_id INT NOT NULL, -- 顧客ID
date DATETIME NOT NULL, -- 日付
log_level ENUM('DEBUG','INFO', 'WARN', 'ERROR') NOT NULL, -- ログレベル(ENUM型で指定)
log_data TEXT, -- ログデータ
PRIMARY KEY (id) -- プライマリキー:ID
)
インデックスだけ貼ったテーブル
| フィールド | 型 | PKey | INDEX |
|---|---|---|---|
| id | INT AUTO_INCREMENT | ★ | |
| customer_id | INT | idx_customer_date | |
| date | DATETIME | idx_customer_date | |
| log_level | ENUM | ||
| log_data | TEXT |
CREATE TABLE test_log_table_index (
id int NOT NULL AUTO_INCREMENT,
customer_id INT NOT NULL, -- 顧客ID
date DATETIME NOT NULL, -- 日付
log_level ENUM('DEBUG','INFO', 'WARN', 'ERROR') NOT NULL, -- ログレベル(ENUM型で指定)
log_data TEXT, -- ログデータ
PRIMARY KEY (id), -- プライマリキー:ID
INDEX idx_customer_date (customer_id, date) -- 顧客IDと日付に対する複合インデックス
)
インデックスとパーティションニングしたテーブル
| フィールド | 型 | PKey | INDEX |
|---|---|---|---|
| id | INT AUTO_INCREMENT | ★ | |
| customer_id | INT | idx_customer_date | |
| date | DATETIME | ★ | idx_customer_date |
| log_level | ENUM | ||
| log_data | TEXT |
CREATE TABLE test_log_table_partition (
id int NOT NULL AUTO_INCREMENT,
customer_id INT NOT NULL, -- 顧客ID
date DATETIME NOT NULL, -- 日付
log_level ENUM('DEBUG','INFO', 'WARN', 'ERROR') NOT NULL, -- ログレベル(ENUM型で指定)
log_data TEXT, -- ログデータ
PRIMARY KEY (id,customer_id,date), -- プライマリキー:ID (パーティション)
INDEX idx_customer (customer_id) -- 顧客IDに対するインデックス
)
PARTITION BY RANGE (TO_DAYS(date)) ( -- 過去3ヶ月分のパーティション定義
PARTITION p20240629 VALUES LESS THAN (TO_DAYS('2024-06-30')),
PARTITION p20240630 VALUES LESS THAN (TO_DAYS('2024-07-01')),
〜省略〜
PARTITION p20240926 VALUES LESS THAN (TO_DAYS('2024-09-27'))
);
※PARTITION BY RANGE でdateフィールドを1日単位でパーティションを切るようにしています。また日付を1日単位で今回は区切っていますが、1週間とかの単位で区切ることも可能。
作ったテーブルにテストデータをいれる
以下の条件でランダムデータを作成。customer_id毎に3ヶ月分のログデータが入っているイメージでデータを投入します。
INSERT INTO test_log_table (customer_id, date,log_level, log_data)
SELECT
FLOOR(5 * RAND()) + 1, -- customer_idをランダムに生成(1〜5)
CURDATE() - INTERVAL FLOOR(90 * RAND()) DAY, -- 過去90日からランダムに日付を生成
CASE
WHEN RAND() < 0.25 THEN 'DEBUG'
WHEN RAND() < 0.5 THEN 'INFO'
WHEN RAND() < 0.75 THEN 'WARN'
ELSE 'ERROR'
END as log_level, -- ランダムにログレベルを選択
SUBSTRING(
REPEAT(
CHAR(FLOOR(65 + (RAND() * 26))),
FLOOR(300 + (RAND() * 701))
),
1,
FLOOR(300 + (RAND() * 701))
) AS log_data
上記を数回実行後、From句にtest_log_tableをつけて倍々方式でデータを投入。
INSERT INTO test_log_table (customer_id, date,log_level, log_data)
SELECT
FLOOR(5 * RAND()) + 1, -- customer_idをランダムに生成(1〜5)
CURDATE() - INTERVAL FLOOR(90 * RAND()) DAY, -- 過去90日からランダムに日付を生成
CASE
WHEN RAND() < 0.25 THEN 'DEBUG'
WHEN RAND() < 0.5 THEN 'INFO'
WHEN RAND() < 0.75 THEN 'WARN'
ELSE 'ERROR'
END as log_level, -- ランダムにログレベルを選択
SUBSTRING(
REPEAT(
CHAR(FLOOR(65 + (RAND() * 26))),
FLOOR(300 + (RAND() * 701))
),
1,
FLOOR(300 + (RAND() * 701))
) AS log_data
From
test_log_table
test_log_table_indexに同じデータを丸ごと投入
INSERT INTO test_log_table_index (id,customer_id, date,log_level, log_data)
select * FROM test_log_table
同じく、test_log_table_partitionに同じデータを丸ごと投入
INSERT INTO test_log_table_partition (id,customer_id, date,log_level, log_data)
select * FROM test_log_table
※作業PCのストレージが悲鳴を上げ始める…(´;ω;`)
やっとこさ本題の速度測定
実際にいくつかSQLを打って速度を見てみます。test_log_table と書いているテーブルは各種使い分けて速度を測定しています。
全件のカウント取得
これは差分が発生しない想定。
select count(*) from test_log_table
count(*):6,553,600
| テーブル | 結果 |
|---|---|
| test_log_table | 7s !? |
| test_log_table_index | 1s |
| test_log_table_partition | 1s |
変わらない想定だったがtest_log_tableは最初に手動でデータ入れたから遅くなっているのかな?ということでOPTIMIZEを実行して整理
OPTIMIZE TABLE test_log_table;
再度測定してみたところ、想定どおりとなった。
| テーブル | 結果 |
|---|---|
| test_log_table | 1s |
| test_log_table_index | 1s |
| test_log_table_partition | 1s |
customer_id毎に分割してグループ化して取得
これは想定ではインデックスが入っているindexとpartitionテーブルが早いと想像。
select customer_id, count(*) from test_log_table
group by customer_id
order by customer_id;
-------------------
1 1,309,662
2 1,310,663
3 1,309,883
4 1,312,255
5 1,311,137
| テーブル | 結果 |
|---|---|
| test_log_table | 4s |
| test_log_table_index | 3s |
| test_log_table_partition | 9s !? |
が、これはパーティションを分けている分インデックスはあっても逆にアクセス遅くなったみたいです。 盲点。
実際の使用想定で条件絞っての取得(customerでだけ絞り込み)
customer_id =1 の全ログを取得。これはインデックスを使っている、indexとpartitionが優勢になる想定。
select count(*) from test_log_table
where customer_id = 1
count(*):1,309,662
| テーブル | 結果 |
|---|---|
| test_log_table | 3s |
| test_log_table_index | 0.275s |
| test_log_table_partition | 0.275s |
ここは想定どおり、驚くところはなかった。indexだけでも優秀。
実際の使用想定で条件絞っての取得(customer+日付で絞り込み)
customer_id =3 かつ、日付を2024-09-19〜2024-09-26のデータを取得
ここらへんからパーティションが本領発揮してくれないかな?
select count(*) from test_log_table
where customer_id = 3
and date between '2024-09-19 00:00:00' and '2024-09-26 23:59:59'
count(*):116,250
| テーブル | 結果 |
|---|---|
| test_log_table | 4s |
| test_log_table_index | 0.081s |
| test_log_table_partition | 0.065s |
結果は上記の通りで、indexより早いけど大差はありませんでした。
テストデータ600万件くらいじゃ差がでないorz
もっとデータを入れたら大きい差がでるんじゃないかなと思います。
今回のパーティションテーブルは日付毎なので、以下のパーティションを指定して
取得することも可能です。
select count(*) from test_log_table_partition
PARTITION (p20240919, p20240920,p20240921,p20240922,p20240923,
p20240924,p20240925,p20240926)
where customer_id = 3
count(*):116,250
| テーブル | 結果 |
|---|---|
| test_log_table | ー |
| test_log_table_index | ー |
| test_log_table_partition | 0.025s |
うん。最速!
システム実装時は使いづらいかもだけど!
当たり前ですが、Where句で更に and date between '2024-09-19 10:00:00' and '2024-09-30 12:00:00'
などを指定して更に条件づけして絞ることもできます。
最後にデータ削除速度
日次バッチで3ヶ月以上前のデータを削除していくイメージ(呼び出す側で日付範囲は計算する想定)
delete from test_log_table
where date between '2024-06-29 00:00:00' and '2024-06-29 23:59:59'
delete row:72,606
| テーブル | 結果 |
|---|---|
| test_log_table | 12s |
| test_log_table_index | 18s !? |
| test_log_table_partition | 4s |
インデックスあるほうが遅くなるのね、ちょっと想定外。確かに索引データを消すのにも時間がその分かかるのかな?
そしてパーティションは最速。だがこれだと枠が残ったままなのでそもそも
パーティション毎削除するのを実行。
消したデータを戻してから、以下実行
ALTER TABLE test_log_table_partition DROP PARTITION p20240629;
| テーブル | 結果 |
|---|---|
| test_log_table | ー |
| test_log_table_index | ー |
| test_log_table_partition | 0s |
※使ってたUIがDBeaverで、ALTER分だと細かい時間とれなかったので詳細ミリ秒測れず。
メモ:
そして一番古いのをDropすると古い範囲ルールについてADD PARTITIONで追加はできないみたい。Partitionは昇順である必要があるとのこと。 ここらへんは気をつけるべき内容でした。
ALTER TABLE test_log_table_partition
ADD PARTITION (
PARTITION p20240629 VALUES LESS THAN (TO_DAYS('2024-06-30')
);
これはエラーになる。
未来の日付を追加は可能
ALTER TABLE test_log_table_partition
ADD PARTITION (
PARTITION p20240927 VALUES LESS THAN (TO_DAYS('2024-09-28'))
);
新しい日付範囲を増やす分には怒られません。
総括
- パーティションをまたがって参照するユースケースが少なければだいぶ有効
- ログじゃないテーブルだったらcustomerみたいなシステム内で大きくデータが分布されそうなフィールドで区切ってみるのも良さそうだなと感じた。今後試してみたい。インデックスでも事足りる気がするけど…
- ログデータを格納するテーブルだったら最適解な気がする。不要データ削除も負荷がすくない
- ゴミデータもDelete文で消すよりDROP PARTITIONで消す方が効率性に優れそう
- 検証データはもっと作りましょう(泣)作業PCの容量がなくてこれ今回は以上できなかった。次回ストレージ調整してからまた検証してみたい気もする