この記事で行うこと
こんにちは。日頃の開発でMQTTを使用して音声をやりとりしたのち、その音声の文字起こしをするという機能を実装することになりました。音声のやりとりが確実に行われているかを確認するために、音声ファイルを一度MQTTでPublish and Subscribeし、再度復元して、聞き取れる形式であることを確認することにしました。本記事は、その時の記録および勉強の内容を記したものになります。なお、参考文献に関しては記事の最後に載せてあります。
本記事に掲載されているプログラムの流れは以下のとおり。
- wav音声ファイルをPythonで読み込み
- 読み込んだ音声データをNumpy配列として格納
- 全ての音声データを一度に送ることはできないのでチャンキング
- MQTTを使用してPublish(音声を送信)
- 別スレッドでSubscribe(音声を受信)
- wavファイルに復元し元の音声が同じであることを確認
この記事では、上記のプログラムを試しに作ってみることで以下の内容を学習。
- wavファイルの形式、音声データの取り扱い
- Python でMQTTを使用する時の基礎
- MQTTを活用したデータの送受信
音声データについての学習
音声データの形式については、いくつかのものが存在する。今回はwavファイルを作成して、それを音声データとして扱う。なお、ソニーのサイトに音声形式に関する一覧表があったので、そちらを参照する。
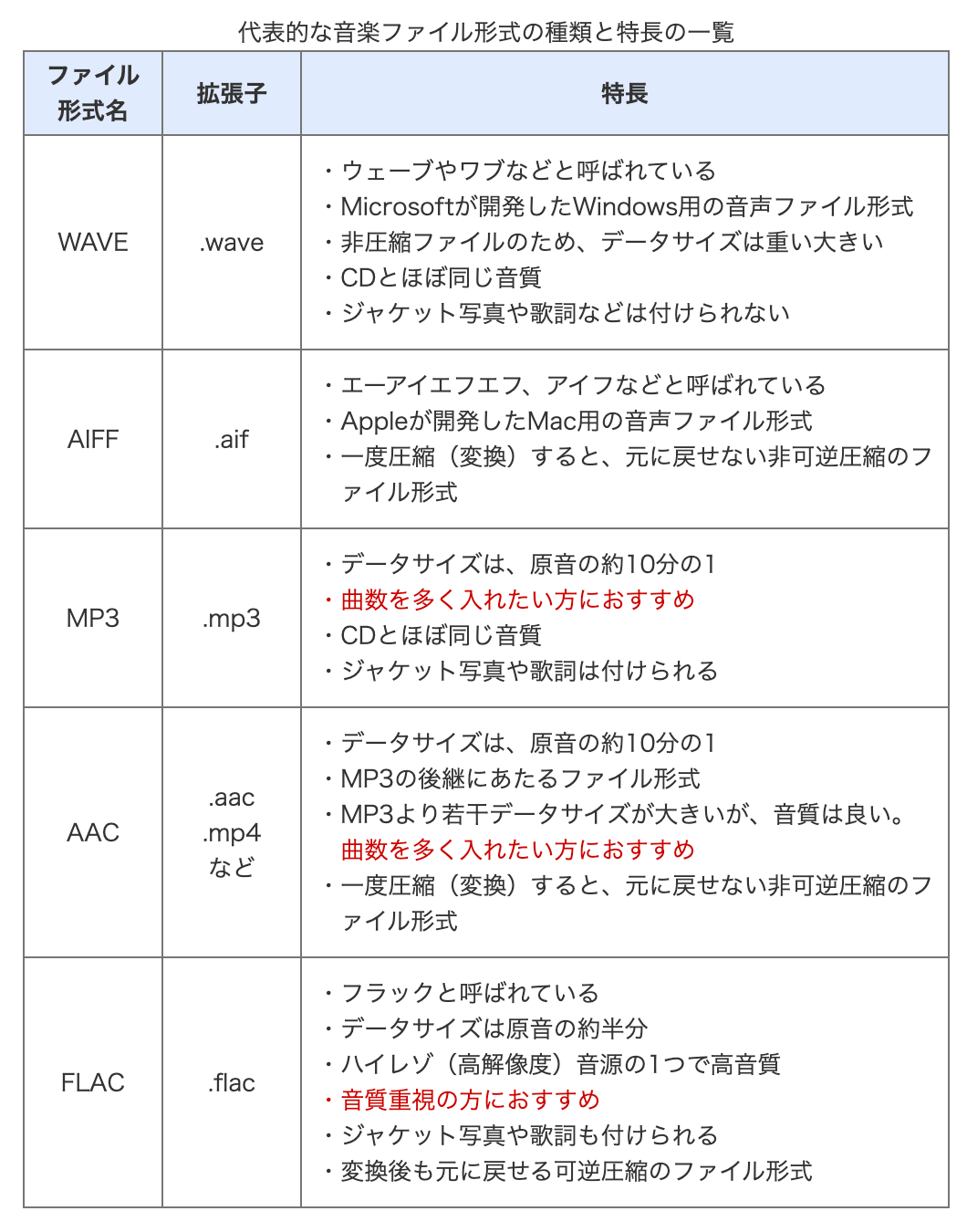
もしかしたら他の圧縮形式でも問題ないのかもしれないが、今回は音声認識モデルの仕様を前提としているので、なるべく音質を落とさないようにWAVE形式のデータを使用する。
wavファイルがどのようになっているのかについては、以下のようになっているらしい。
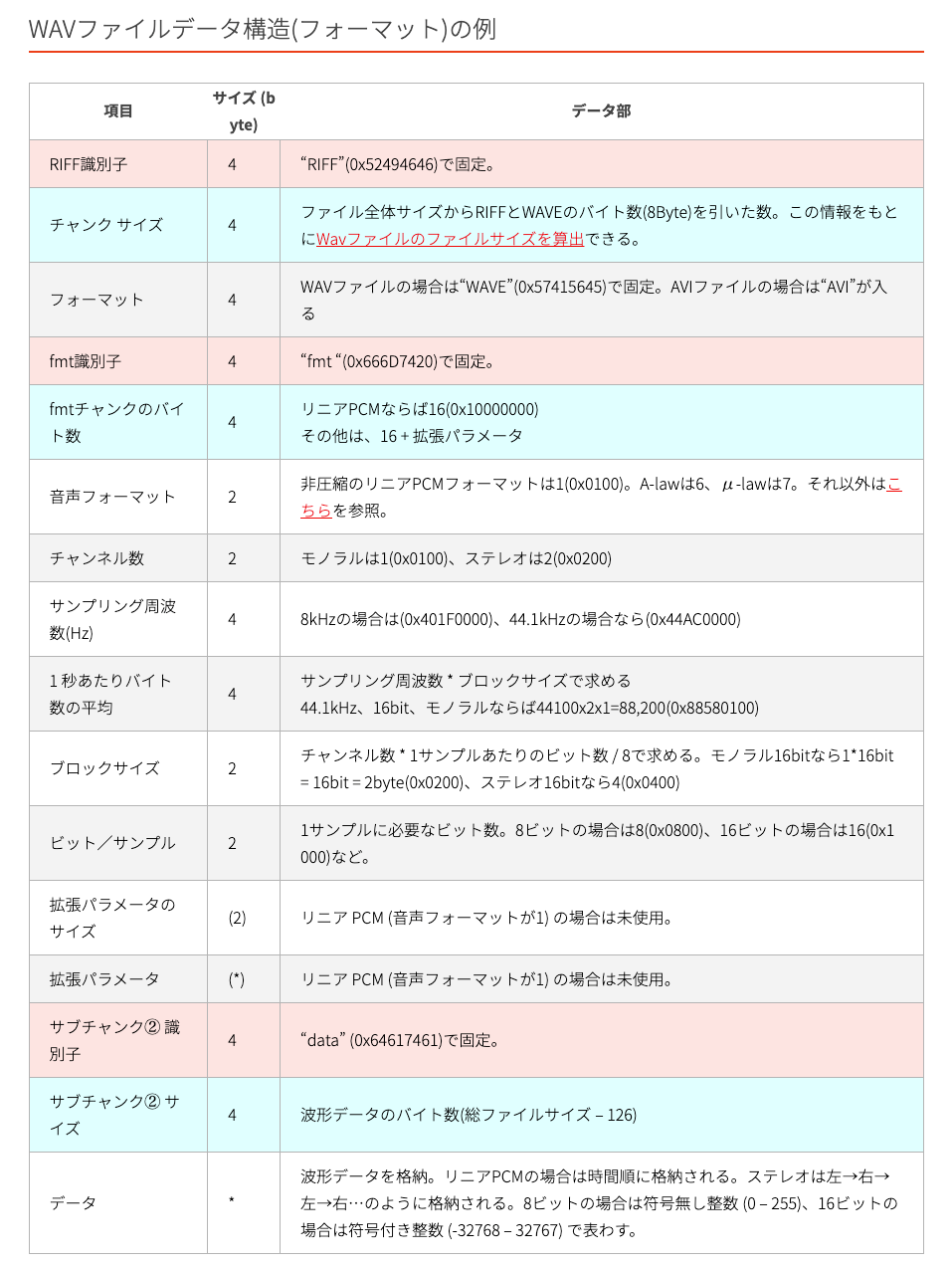
このようにヘッダーファイルには、サンプリング周波数やwavファイルのサイズなど様々な情報が含まれている。これらの情報は、pythonのwaveライブラリを使用して読み込むことで簡単に取得することができる。
import wave
wf = wave.open('test.wav','rb')
print('type: ', type(wf))
print('チャンネル数:', wf.getnchannels()) # モノラル: 1,ステレオ: 2
print('サンプル幅:', wf.getsampwidth()) # バイト数 (1byte=8bit)
print('サンプリング周波数:', wf.getframerate())
print('フレーム数:', wf.getnframes()) # フレームの数
print('パラメータ:', wf.getparams()) # 残りのパラメータをタプルに
とくにステレオの音声データだった場合は、データフィールドの値が左→右→左というように交互になるので、データとして取り出す際には注意が必要である。
MQTTについて
MQTT(Message Queueing Telemetry Transport)は、IoTの開発によく使用される通信プロトコルである。MQTTは、あらゆるデバイス間で、短いメッセージを頻繁に送受信するのに向いている。例えば農場でトラクター、センサー、ドローンなど、さまざまなデバイス間でデータをリアルタイムで共有する場合などに利用できる。
- IBM社とEurotech社のメンバーにより考案
- パブリッシュ/サブスクライブモデルの原則に基づいて機能
- データの送信側(パブリッシャー)は受信側(サブスクライバー)には直接データ送信せず、ブローカーを仲介。その結果、違いの場所の把握(IPアドレス)、送受信タイミングの調整など時間や場所を互いに分離可能
- Message Queueing: 送信側が送るデータをデータ領域に保持しながら、受信側の処理の完了を待たずに次の処理に移る → 高速
- HTTPのヘッダサイズが50バイト以上なのに対して、MQTTは2バイトほどで軽量。モバイル向けの通信に適する
MQTTの詳しい仕様に関しては、今回はあまり触れないが、
Pythonでは、pahoというMQTTのライブラリが公開されており、以下の公式チュートリアルの基本的なサンプルを使用して使い方を確認する。
また、詳しいクラスや関数のドキュメントは以下にある。今回は、この中から代表的なものだけをピックアップしてまとめる。
Publisher
Publisher全体のコードは以下のように示されている。
import time
import paho.mqtt.client as mqtt
def on_publish(client, userdata, mid, reason_code, properties):
# reason_code and properties will only be present in MQTTv5. It's always unset in MQTTv3
try:
userdata.remove(mid)
except KeyError:
print("on_publish() is called with a mid not present in unacked_publish")
print("This is due to an unavoidable race-condition:")
print("* publish() return the mid of the message sent.")
print("* mid from publish() is added to unacked_publish by the main thread")
print("* on_publish() is called by the loop_start thread")
print("While unlikely (because on_publish() will be called after a network round-trip),")
print(" this is a race-condition that COULD happen")
print("")
print("The best solution to avoid race-condition is using the msg_info from publish()")
print("We could also try using a list of acknowledged mid rather than removing from pending list,")
print("but remember that mid could be re-used !")
unacked_publish = set() # ACKがまだ帰ってきていないメッセージを管理するためのsetオブジェクト
mqttc = mqtt.Client(mqtt.CallbackAPIVersion.VERSION2)
mqttc.on_publish = on_publish
mqttc.user_data_set(unacked_publish)
mqttc.connect("mqtt.eclipseprojects.io")
mqttc.loop_start()
# 2つのメッセージを送信
msg_info = mqttc.publish("paho/test/topic", "my message", qos=1)
unacked_publish.add(msg_info.mid) # メッセージを送信したのでACKが帰ってくるまでmid(message id)を追加
msg_info2 = mqttc.publish("paho/test/topic", "my message2", qos=1)
unacked_publish.add(msg_info2.mid) # メッセージを送信したのでACKが帰ってくるまでmid(message id)を追加
# 全てのメッセージに対するACKがブローカーから帰ってくるまでは処理を終了しない
while len(unacked_publish):
time.sleep(0.1)
# 全てpublishするまで処理を止める
msg_info.wait_for_publish()
msg_info2.wait_for_publish()
mqttc.disconnect()
mqttc.loop_stop()
一つずつ読み解いていく。
Clientクラス
mqttc = mqtt.Client(mqtt.CallbackAPIVersion.VERSION2)
Mqtt clientモジュールは、MQTTの仕組みを簡単にするためのものである。ここでは、mqtt.CallbackAPIVersion.VERSION2というものが引数として渡されているが、これはAPIのバージョンを指定するためのものである。このバージョンによって各メソッドの想定される引数が変わるが、特に指定しない場合は、2024年10月現在は最新のバージョン2になるらしい。
想定されている使用の流れは以下のとおり。
-
connect()を使用してブローカーに接続 - 以下の3種類のメソッドのうち一つを使用しループ処理を開始
-
loop(): 現在は使用が推奨されていないが基本となるメソッド。クライアントがブローカーと接続を維持するために定期的に呼び出される必要がある。呼び出されるとネットワークソケット(通信の窓口)をチェックし、メッセージが到達していないか、まだブローカーに送信していないメッセージがないかをチェック。
GUIアプリケーションによる他のループと並行して使用するシチュエーションなどでもそこに組み込むことで使用可能 -
loop_forever():loop()を定期的に呼び出す操作をメインスレッドで行うコール関数。つまり、loop_forever()のあとに書かれたコードは、この関数が終了するまで実行されない -
loop_start():loop()を複数回呼び出す操作をバックグラウンドスレッドで実行するためのコール関数。メインスレッドで並列して他の処理を行う必要がある場合はこれを使用
-
- 送信側クライアントはループが実行されるたびに
publish()でデータを送信 - 受信側クライアントはループが実行されるたびに
subscribe()でデータを受信 -
disconnect()でブローカーから切断し終了
on_publish
def on_publish(client, userdata, mid, reason_code, properties):
# reason_code and properties will only be present in MQTTv5. It's always unset in MQTTv3
try:
userdata.remove(mid)
except KeyError:
print("on_publish() is called with a mid not present in unacked_publish")
print("This is due to an unavoidable race-condition:")
print("* publish() return the mid of the message sent.")
print("* mid from publish() is added to unacked_publish by the main thread")
print("* on_publish() is called by the loop_start thread")
print("While unlikely (because on_publish() will be called after a network round-trip),")
print(" this is a race-condition that COULD happen")
print("")
print("The best solution to avoid race-condition is using the msg_info from publish()")
print("We could also try using a list of acknowledged mid rather than removing from pending list,")
print("but remember that mid could be re-used !")
mqttc.on_publish = on_publish
clientがデータをpublishした際の挙動を設定するためのプロパティ(オブジェクトの属性に対してどうアクセスするかを提供する仕組み)がon_publishである。つまり、clientがデータをpublishした際に呼び出されるコールバック関数を上記のように指定できる。呼ばれるタイミングはQoSレベルに依存する。
QoSレベルとは、通信の品質の段階のことである。
- QoS0: Publisherはブローカーにデータが届いたかどうかを気にせず次のメッセージを送る
- QoS1: Publisherは少なくとも1回以上全てのデータが送られていることを確認しながらメッセージを送る。つまり、1度送ってPUBACK応答が返ってこなければデータを再送する。タイミングによってはデータを重複送信してしまう可能性がある
- QoS2: Publisherは必ず1回ブローカーにデータを届ける。PUBCOMPをブローカーから受け取ることで一つのメッセージの送信が完了する
on_publish()はpublishが成功(したと送信側が判断)した際に呼ばれる関数なので、QoSレベルによって呼ばれるタイミングが異なる。
また、Pythonでコールバック関数を定義する際は、on_publish()のように、client、userdataなどの使用されていない引数もちゃんと記載するという慣習が存在する。これは、ライブラリがコールバック関数を呼び出す際のシグネチャ(引数の順序や数)を固定している場合、タイプエラーや引数不足などのエラーが生じうるためである。
user_data_set
mqttc.user_data_set(unacked_publish)
コールバック関数に渡されるユーザーデータ変数をセットする。引数はどんなデータ型でも良い。
connect
mqttc.connect("mqtt.eclipseprojects.io")
クライアントとリモートブローカーを接続するための関数。よく指定する引数は以下のとおり。
- host(str):リモートブローカーのホストネームもしくはIPアドレス。
test.mosquitto.orgを渡すと無料で公開されているテスト用のブローカーを使用することができる - port (int):接続するサーバーのポート番号。デフォルトは1883であるが、SSL/TLSを使用している場合のデフォルトポートは8883であり異なるため、これを使用している場合は
tls_set()を使用する必要があるらしい - keepalive (int): keepaliveとは、クライアントがブローカーに対して「接続が維持されている」ことを示すための「ping」メッセージを送信する最大間隔(秒数)である。デフォルトは60秒なので、60秒間接続がなければpingメッセージで接続を確認
loop_start
先ほども説明したように、loop_start(): loop()を複数回呼び出す操作をバックグラウンドスレッドで実行するためのコール関数。呼び出されてもバックグラウンドで処理が進むので次の行の処理は実行される。
publish
# 2つのメッセージを送信
msg_info = mqttc.publish("paho/test/topic", "my message", qos=1)
unacked_publish.add(msg_info.mid) # メッセージを送信したのでACKが帰ってくるまでmid(message id)を追加
msg_info2 = mqttc.publish("paho/test/topic", "my message2", qos=1)
unacked_publish.add(msg_info2.mid) # メッセージを送信したのでACKが帰ってくるまでmid(message id)を追加
publish()メソッドを使用することで、ブローカーへデータを送信することができる。なお、publishメソッドのメイン引数は以下のとおり。
-
topic(str): トピック名をstr型で指定。paho/test/topicのように階層を/で区切ったトピック名にするのが通例 -
payload(str|bytes|int|float): payload(ペイロード)というのは、通信プロトコルやネットワークの分野で データの本体 を表す言葉。つまり、この引数与えたデータがpublishされる。ただしintやfloatのデータはstrに変換され送信される -
qos(int): 通信の品質(QoS)を指定するためのパラメータ。0, 1, 2のどれかを指定可能。QoSについてはon_publishの説明を参照
publish()はMQTTMessageInfoオブジェクトを返す。これは、メッセージに関する情報を保持している。今回のサンプルコードで関係しているのは以下のもの。
-
mid: int型のメッセージID -
is_published()-> bool: メッセージがpublishされていればTrueを返すメソッド -
wait_for_publish(timeout:float | None):is_published()の結果がTrueになるまで(もしくはタイムアウトになるまで)実行をブロック
上記のpublish()の下のコードでは、wait_for_publish()を呼び出して、publishが終わるまで待機する。
msg_info.wait_for_publish()
msg_info2.wait_for_publish()
その後、ブローカーから切断 and loopを終了している。
Subscriber
Subscribe側では、4種類のコールバック関数を定義している。
import paho.mqtt.client as mqtt
def on_subscribe(client, userdata, mid, reason_code_list, properties):
# subscribeリクエストに対してブローカーがレスポンスした際のコールバック
if reason_code_list[0].is_failure:
print(f"Broker rejected you subscription: {reason_code_list[0]}")
else:
print(f"Broker granted the following QoS: {reason_code_list[0].value}")
def on_unsubscribe(client, userdata, mid, reason_code_list, properties):
# reason_code_list はMQTTv5にのみ存在することに注意
if len(reason_code_list) == 0 or not reason_code_list[0].is_failure:
print("unsubscribe succeeded (if SUBACK is received in MQTTv3 it success)")
else:
print(f"Broker replied with failure: {reason_code_list[0]}")
client.disconnect()
def on_message(client, userdata, message):
# userdataは、好きなデータ構造で指定できる。今回はlist
# メッセージを受信したらリストに溜めていく
userdata.append(message.payload)
# We only want to process 10 messages
if len(userdata) >= 10:
client.unsubscribe("$SYS/#")
def on_connect(client, userdata, flags, reason_code, properties):
if reason_code.is_failure:
print(f"Failed to connect: {reason_code}. loop_forever() will retry connection")
else:
# サブスクライブはon_connectの中で呼び出すようにすると再接続の際に確実に呼び出される
client.subscribe("$SYS/#")
mqttc = mqtt.Client(mqtt.CallbackAPIVersion.VERSION2)
mqttc.on_connect = on_connect
mqttc.on_message = on_message
mqttc.on_subscribe = on_subscribe
mqttc.on_unsubscribe = on_unsubscribe
mqttc.user_data_set([])
mqttc.connect("mqtt.eclipseprojects.io")
mqttc.loop_forever()
print(f"Received the following message: {mqttc.user_data_get()}")
on_subscribe
クライアントがサブスクライブのリクエストをブローカーに送り、ブローカーが応答した際のコールバック。使用している変数は以下のとおり。
def on_subscribe(client, userdata, mid, reason_code_list, properties):
# subscribeリクエストに対してブローカーがレスポンスした際のコールバック
if reason_code_list[0].is_failure:
print(f"Broker rejected you subscription: {reason_code_list[0]}")
else:
print(f"Broker granted the following QoS: {reason_code_list[0].value}")
reason_code_listは、ReasonCodeインスタンスのリストである。ReasonCodeインスタンスは、is_failureというプロパティを持ち、サブスクライブの開始が成功したかどうかを確認することができる。
on_unsabscribe
クライアントがサブスクライブの解除をブローカーにリクエストし、その応答が返ってきた際に呼び出されるコールバックである。
def on_unsubscribe(client, userdata, mid, reason_code_list, properties):
# reason_code_list はMQTTv5にのみ存在することに注意
if len(reason_code_list) == 0 or not reason_code_list[0].is_failure:
print("unsubscribe succeeded (if SUBACK is received in MQTTv3 it success)")
else:
print(f"Broker replied with failure: {reason_code_list[0]}")
client.disconnect()
reason_code_listは、MQTT v3では常に空のリストであるため、サブスクライブの解除は成功したと見なされる。また、reason_code_list[0].is_failureはMQTTv5用の記載であり、成功したかどうかがboolでわかる。もし、失敗していたらそのReasonCodeオブジェクトを出力する。
on_message
クライアントがブローカーからメッセージを受信した際に呼び出されるコールバック。userdataは任意の型のデータで良いため、今回はリストを後で指定している。
def on_message(client, userdata, message):
# userdataは、好きなデータ構造で指定できる。今回はlist
# メッセージを受信したらリストに溜めていく
userdata.append(message.payload)
# We only want to process 10 messages
if len(userdata) >= 10:
client.unsubscribe("$SYS/#")
messageを引数として受け取り、message.payloadとすることで、publishしたデータにアクセスすることができる。
on_connect
on_connectは、クライアントがブローカーに接続のリクエストを行い、その応答が返ってきた際に使用するコールバックである。
def on_connect(client, userdata, flags, reason_code, properties):
if reason_code.is_failure:
print(f"Failed to connect: {reason_code}. loop_forever() will retry connection")
else:
# サブスクライブはon_connectの中で呼び出すようにすると再接続の際に確実に呼び出される
client.subscribe("$SYS/#")
もし、接続に失敗したらその旨を出力し、成功したらsubscribe()を開始する。on_connect()の中でサブスクライブを開始することで、ブローカーへの際接続が必要になった際に、その都度サブスクライブまで再度やり直してくれるためである。
実行部分
これまでのSubscibeのための関数を実行する部分は以下の部分である。
mqttc = mqtt.Client(mqtt.CallbackAPIVersion.VERSION2)
mqttc.on_connect = on_connect
mqttc.on_message = on_message
mqttc.on_subscribe = on_subscribe
mqttc.on_unsubscribe = on_unsubscribe
mqttc.user_data_set([])
mqttc.connect("mqtt.eclipseprojects.io")
mqttc.loop_forever()
print(f"Received the following message: {mqttc.user_data_get()}")
新たに説明するべき部分は以下の部分である。
-
mqttc.user_data_set([]): コールバックの引数userdataに対して空のリストを使用することを設定。ここにsubscribeされたデータなどが溜められていくように今回はon_messageの定義で指定した -
loop_forever(): クライアントとブローカーの接続やサブスクライブなどをメインスレッドで行うが、もし接続が失敗したり、切れたとしても接続するまで永遠にリクエストし続ける
MQTTを使用した音声の送受信
ここから、MQTTを使用したwavファイルの送信、受信、復元を行う。ディレクトリ構成は以下のとおり。test.wavには、録音した自身の音声が入っている。
.
├── audio_publish.py
├── audio_subscribe.py
└── test.wav
またすでに各関数などの説明は行なっているので、まだ説明がない部分やこのコード特有の部分についてのみ説明する。
audio_publish.py
import wave
import numpy as np
import paho.mqtt.client as mqtt
from scipy.signal import resample
import time
import dataclasses
import pickle
@dataclasses.dataclass
class AudioChunk:
audio_start: int
wav_chunk: bytes
class wav_publisher(mqtt.Client):
def __init__(self, broker, port, topic, wav_path):
super().__init__()
self.broker = broker
self.port = port
self.topic = topic
self.connect(self.broker, self.port, 60)
wav_dict = self._wav_to_np(wav_path)
self.data = wav_dict["data"]
self.sample_rate = wav_dict["rate"]
self.n_channels = wav_dict["n_channels"]
# サンプリング周波数を人の音声に十分な16khzまで下げる
new_num_samples = int(len(self.data) * 16000 / self.sample_rate)
self.data = resample(self.data, new_num_samples)
self.data = self.data.astype(np.int16)
print(f"sampling rate: {self.sample_rate}")
print(f"n_channels: {self.n_channels}")
def publish_wav(self, np_length:int):
for i in range(0, len(self.data), np_length):
audio_chunk = AudioChunk(
audio_start=i,
wav_chunk=self.data[i:i+np_length].tobytes()
)
# pubslishできるbytes型に変換してpublish
pickle_data = pickle.dumps(audio_chunk)
self.publish(self.topic, pickle_data)
print(f"Published {i} to {i+np_length}")
time.sleep(1)
def _wav_to_np(self, wav_path:str):
with wave.open(wav_path, "rb") as wf:
rate = wf.getframerate() # サンプリング周波数
frames = wf.getnframes() # フレーム数を取得
data = wf.readframes(frames) # 音声データを取得
n_channels = wf.getnchannels() # チャンネル数を取得
return {
"rate": rate,
"data": np.frombuffer(data, dtype=np.int16),
"n_channels": n_channels
}
if __name__ == "__main__":
try:
client = wav_publisher("test.mosquitto.org", 1883, "test/audio", "test.wav")
client.publish_wav(np_length=5*16000) # 5秒を1セットで送信
except KeyboardInterrupt:
print("Interrupted by user")
client.disconnect()
ポイントはサンプリング周波数を減らすこと、wavデータをチャンクで区切ることである。
サンプリング周波数を減らす
# サンプリング周波数を人の音声に十分な16khzまで下げる
new_num_samples = int(len(self.data) * 16000 / self.sample_rate)
self.data = resample(self.data, new_num_samples)
self.data = self.data.astype(np.int16)
- 人間の声の周波数は最大4kHzとされており、その音声を復元するにはその倍の8kHzのデータが必要
- つまりその倍の16kHzのデータさえあれば音声の情報は十分に残る
- 今回使用したwavファイルは48kHz(映像業界の音の標準らしい)で録音されていたため、送信するデータ量を削減するために高周波帯を取り除く
wavデータをチャンクで区切る
def publish_wav(self, np_length:int):
for i in range(0, len(self.data), np_length):
audio_chunk = AudioChunk(
audio_start=i,
wav_chunk=self.data[i:i+np_length].tobytes()
)
# pubslishできるbytes型に変換してpublish
pickle_data = pickle.dumps(audio_chunk)
self.publish(self.topic, pickle_data)
print(f"Published {i} to {i+np_length}")
time.sleep(1)
もし16kHzで30秒のデータを送ったら、wavデータをnp配列に変換した際の要素数は 16000*30 になる。これを一度にpublishするのはデータが重すぎるため、ここでは、オーディオデータをnp_length要素ごとに区切り、AudioChunkとしてPublishしている。サンプルプログラムでは、5秒=1AudioChunkとしてデータを送信している。
また、データをpublishするには、形式がdictやbytesでなければならない。dictの場合は、要素の型が str, int, float である必要があるため、np.ndarrayはpublishできない。そこで、pickleを使用して、AudioChunk全体をbytes型のデータとしてしまっている。
ただし、このやり方は、pickleが使用できるPython同士の通信を前提にしており、他の言語で作成されたモジュールなどと通信する場合は、np.ndarray→bytes→Base64として、一度バイナリを経由してBase64で文字列にエンコードしつつ、JSONとして送る必要などが出てくるためややめんどくさい。
audio_subscribe.py
import paho.mqtt.client as mqtt
import pickle
from google.protobuf.message import DecodeError
import time
import numpy as np
from scipy.io.wavfile import write
class AudioSubscriber(mqtt.Client):
def __init__(self, broker, port, topic):
super().__init__()
self.broker = broker
self.port = port
self.topic = topic
self.connect(self.broker, self.port, 60)
self.audio_storate = []
def on_message(self, client, userdata, msg):
print(f"Received message on topic: {msg.topic}")
try:
pickle_data = msg.payload
audio_chunk = pickle.loads(pickle_data)
data = np.frombuffer(audio_chunk.wav_chunk, dtype=np.int16)
self.audio_storage.append(data)
print(f"Audiostart: {audio_chunk.audio_start}")
print(f"WAV Chunk Size: {len(audio_chunk.wav_chunk)} bytes")
print(f"AudioChunk: {data}")
except DecodeError as e:
print(f"Failed to decode AudioChunk: {e}")
def subscribe_audio(self):
try:
self.on_message = self.on_message
self.subscribe(self.topic)
self.loop_start()
print(f"Subscribed to topic: {self.topic}")
while True:
time.sleep(1)
except KeyboardInterrupt as e:
print("Subscription stopped.")
print(e)
self.loop_stop()
self.disconnect()
print("------")
self._save_audio_as_wave()
def _save_audio_as_wave(self, wave_path="reconstracted_audio.wav"):
audio_data = np.concatenate(self.audio_storage)
write(wave_path, 16000, audio_data)
print(f"Saved audio as {wave_path}")
if __name__ == "__main__":
broker = "test.mosquitto.org"
port = 1883
topic = "test/audio"
subscriber = AudioSubscriber(broker, port, topic)
subscriber.subscribe_audio()
ここでのポイントはpickleによるデコード、AudioChunkを再度音声データ全体に復元、変更されたサンである。
pickleによるデコード
try:
pickle_data = msg.payload
audio_chunk = pickle.loads(pickle_data)
データを送る際に一度バイナリにしたものを再度pickleで元に戻す必要がある。
AudioChunkを再度音声データ全体に復元
def _save_audio_as_wave(self, wave_path="reconstracted_audio.wav"):
audio_data = np.concatenate(self.audio_storate)
write(wave_path, 16000, audio_data)
print(f"Saved audio as {wave_path}")
このプログラム上では、サブスクライブしたAudioChunkをインスタンス変数self.audio_strageに貯めるようにしており、wavとして出力する際にそれらを1つのnp配列とするためにnp.concatenateしている。
また、書き出す際は、write(wave_path, 16000, audio_data)として、Publishする前に変更した周波数の16kHzを指定する。こうしないと、復元した音声データが早口になってしまう。
使い方
本サンプルプログラムは、別々のターミナルでaudio_processor.pyとaudio_publisher.pyを実行することで使用することができる。結果、reconstracted_audio.wavというファイルが同ディレクトリに生成される。
参考文献