1st Place Winning Solution - Hungry for Gold
概要
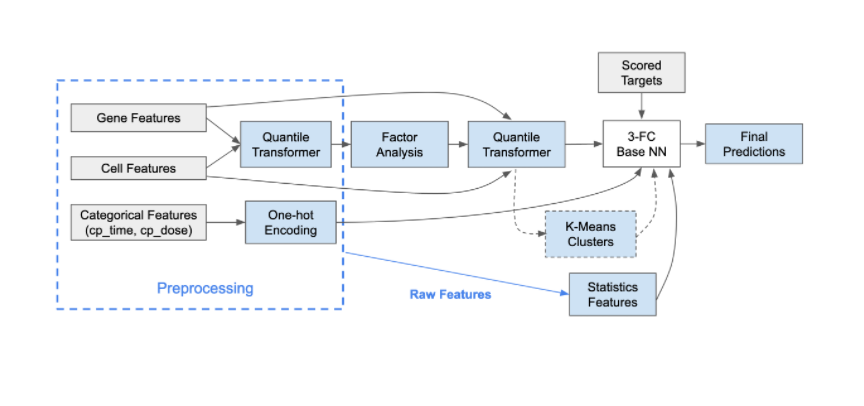
私たちが勝ち上がったブレンド (winning blend) には、7個のモデルが含まれている。
- 3-stage NN stacking by non-scored and scored meta-features
- 2-stage NN+TabNet stacking by non-scored meta-features
- SimpleNN with old CV
- SimpleNN with new CV
- 2-heads ResNet
- DeepInsight EfficientNet B3 NS
- DeepInsight ResNeSt
以下に、ブレンドの概略図を示す。
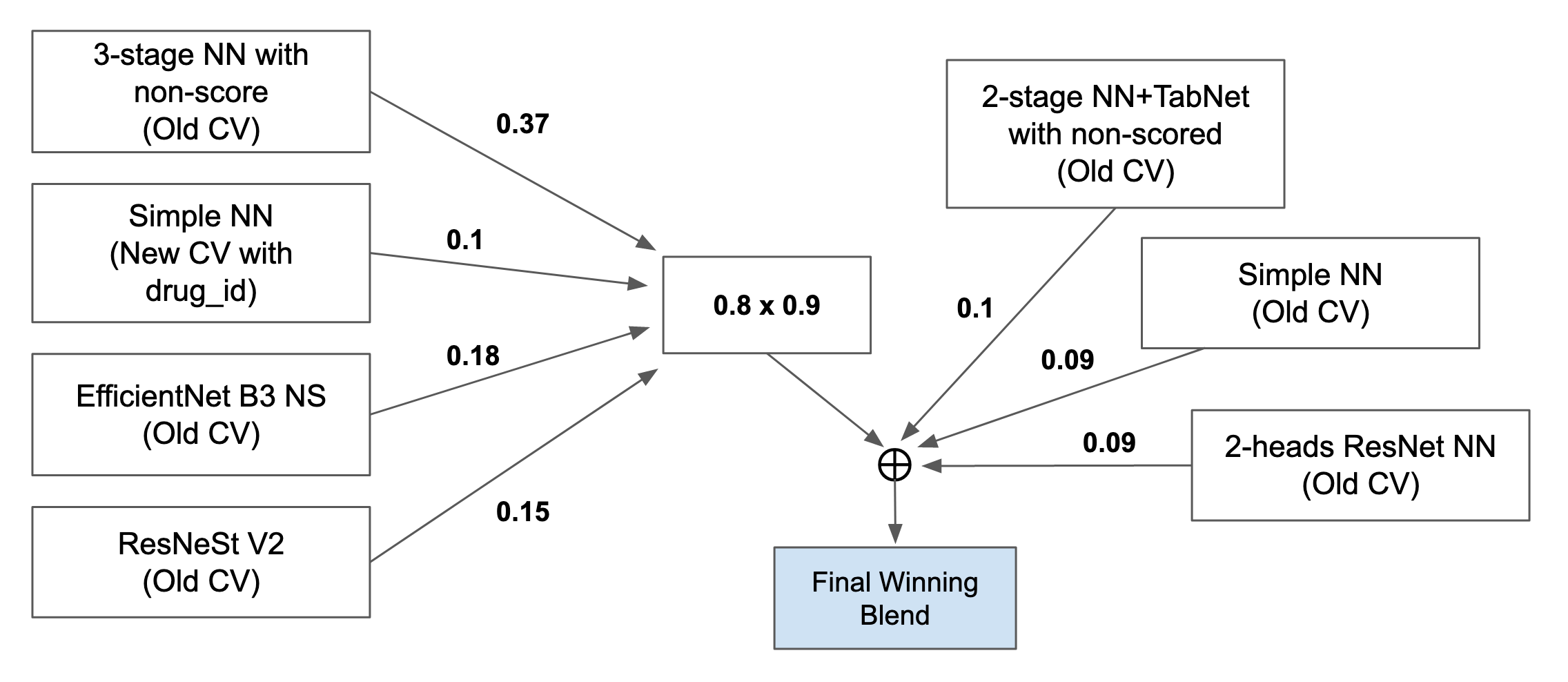
重み付け平均に基づいて、2つの最終サブミッションを決めた。winning blendが最もLBがよく、ベストCVを混ぜたブレンドはプライベートLBで5位だった。
ブレンド配合の決め方
ブレンドの配合は2つのファクターに基づいて決めた。1つはLBスコア。もう1つは個々のモデル間の相関だ。わかりやすくするために、コントロール群を抜きにして、各モデルと他のモデルとの相関を計算した。LBスコアが最大になるように、モデルは手動で選んだ。相関の平均が少ないモデルにはより大きい重みを与えた。また、いくつかの重みは、以前にサブミットしたブレンドのスコアから決めた。
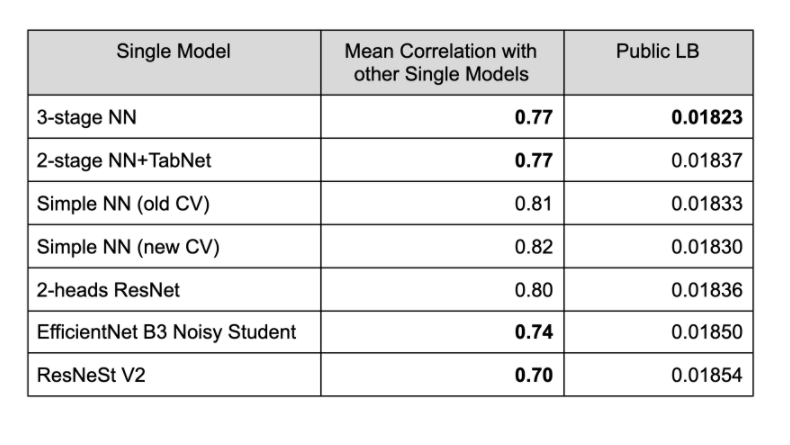
ベストCVのシングルモデルの選び方は、完全にOOF (Out-of-folds) に基づいて決めた。OptunaのTPE (Tree-structed-Parzen Estimator) と、ScipyのSLSQP (Sequential Least Squares Programming) メソッドを使って、CVを最適化するための重みを探索した。Optuna (3000 or 5000 trials) とSLSQP の結果はほとんど同じになった。
5モデルのベストCVのlog lossは**0.15107 (private LB: 0.01601)**だった。探索の結果として2-stage NN+TabNetとSimple NNモデルが除かれたのは、面白い結果だ (このことがwinning blendに貢献した)。
DeepInsight CNNsを追加したことが、最終ブレンドで重要な役割を果たした。他の"浅い"NNモデルたちと合わせて、多様性が高まったからだろう。CNNのあり/なしでlog lossを比べてみたら、DeepInsightあり版ではプライベートLBが0.00008も向上した!
Cross-Validation戦略
私達のモデルのほとんどは、MultilabelStratifiedKFold (old CV) にもとづいている。ただ、Simple NNモデルに関してはDrug and MultiLabel Stratification Codeを使った。CVの分割を変えるごとに違うシードを使った。CVのlog lossとLBのlog lossがなるべく連動するようなCV戦略を選択した。5-foldあるいは10foldを使い、varianceを小さくするためにいろんなシードを使って学習を行った。
とくに、old CVとnew CVのOOFファイルを組み合わせてCV配分を探索するのは難しかった。new CVモデルのlog lossスコアはoldと比べて非常に大きかったからだ。最終的には、old CVモデルをBest CVブレンドに使った (old CV: 0.015107, private LB: 0.01601)。
モデル詳細
訳すのがたいへんなので、おおまかな概要だけ書きます。
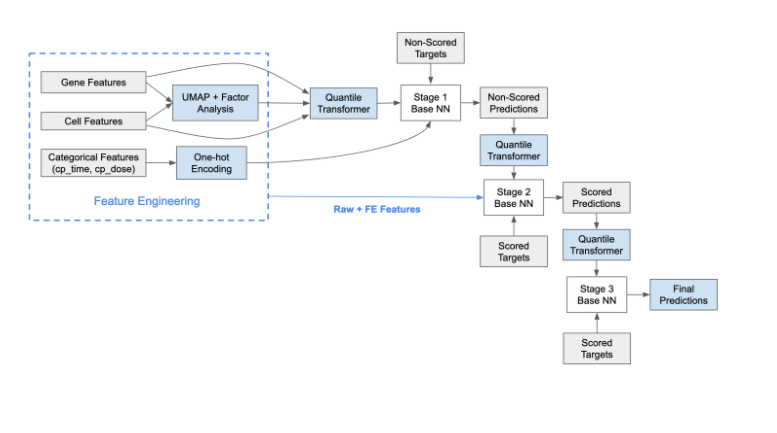
3-Stage NN
- シングルモデルでは一番性能がよかった
- stackingを積み重ねて予測
- 前stageの予測を次のstageのmeta-featureとして使う
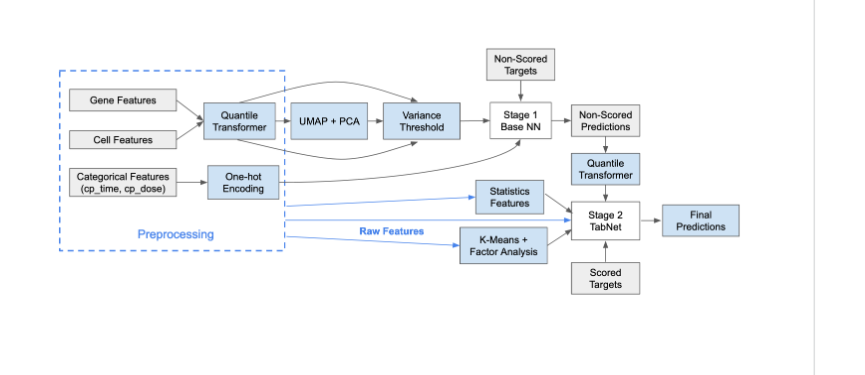
2-Stage NN+TabNet
- 大まかなところは3-Stage NNと同じ
- 2 stageで使うモデルをTabNetにした
Simple NN
- ふつうのNN
2-heads ResNet
- Fork of 2heads... looper super puper plateをフォーク
- 層の重み凍結/解凍とか、ちょい変更は加えた

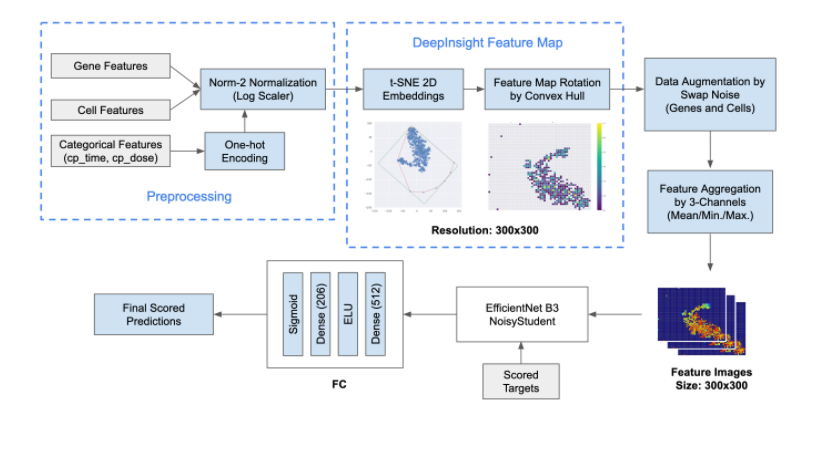
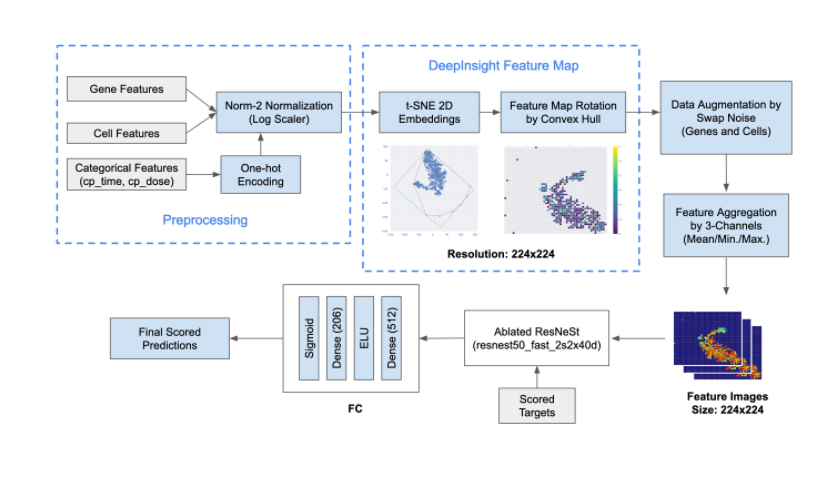
DeepInsight CNNs
これが一番オリジナリティのある部分だと思ってます(by 訳者)
-
genesとcellsの特徴量しか使ってない (特徴量エンジニアリングしてない!?)
-
これを加えたことでモデルの多様性が上がった
-
相関のある特徴量が近くなるようにに2次元領域にマッピング
-
事前学習モデルとしてEfficientNetとResNeStを使用
-
学習
- genes, cells, one-hot特徴量をLog Scalerで正規化
- Standard Scaler, Robust Scaler, Min/Max Scalerよりもロバストだった
- t-SNEを適用して2次元特徴量空間に埋め込み
- 過学習が怖かったので(このコンペはとてもimbalancedなデータセットだった) Swap Noiseの
アイデアでdata augmentationを行った- 各トレーニングサンプルはある確率(10%)で他のランダムなサンプルと全体の15%の特徴量を交換する
- さらに、特徴量は拡張した後に、特徴量マップイメージにマッピングされる
- genes, cells, one-hot特徴量をLog Scalerで正規化
モデルがどれだけばらついていたか
私達のモデルがどれだけばらついていたかを分かってもらうために、相関係数の平均のヒートマップ(best single model)を示そう。
LBが一番良かったモデルたちは、それらすべてがLBで非常に良いスコアを示したにもかかわらず、相関はとても低かった。とくに、DeepInsight CNNsでは、他のNNモデルとの相関係数は0.63-0.73しかなかった。これは、モデルの多様性がアンサンブルを大きく底上げすることを強く示している。
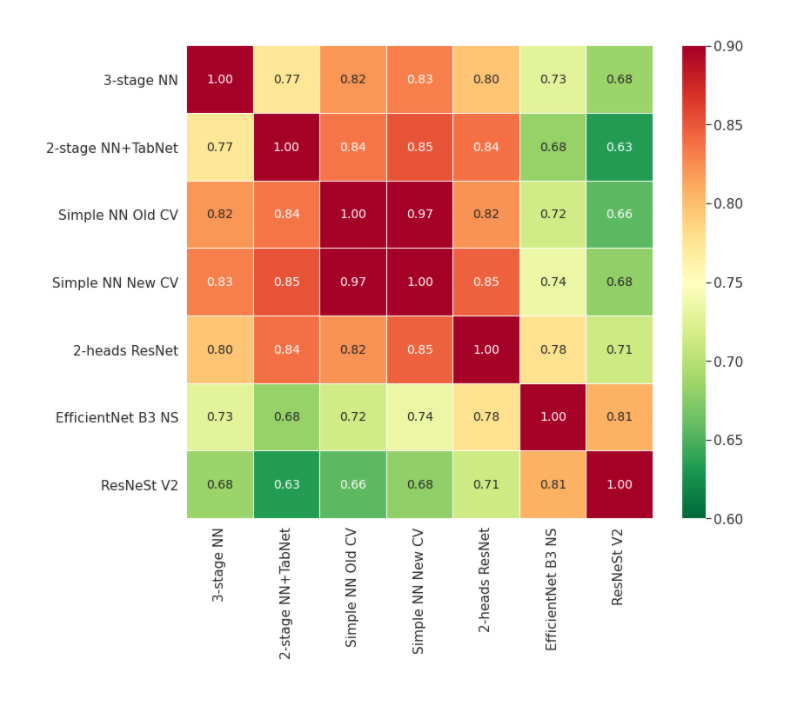
ベストCVモデルのOOFも似たような傾向を示していた。モデル同士の相関は低く、値にするとたったの0.52-0.70しかなかった!
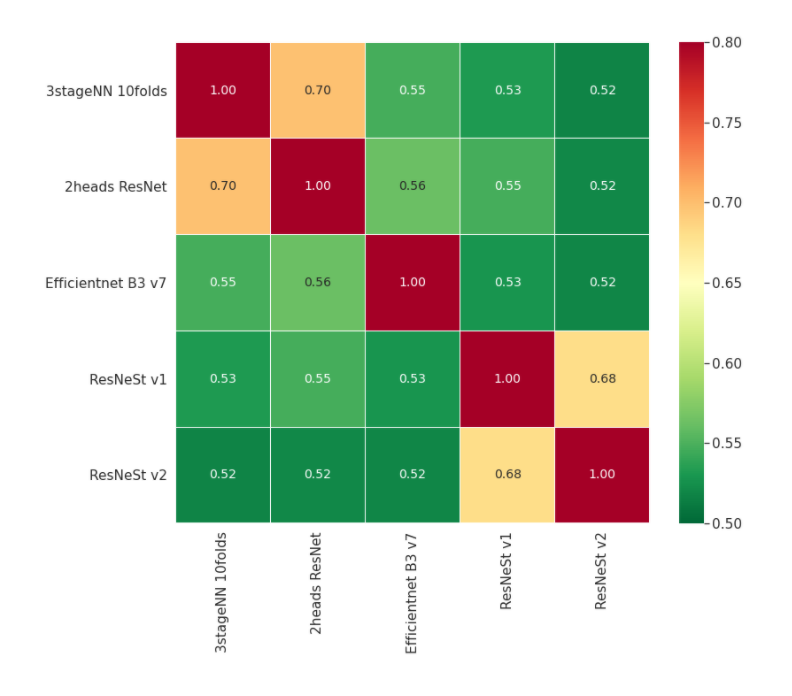
個人的な経験としては、0.85-0.95程度の相関が非常に良いアンサンブルになるのが常だと思っている。
今回のコンペティションでは、個々のベストモデルが強力なパフォーマンスを発揮したとともに、常識よりも大幅に低い相関を示した。
時間効率
最終のブレンドサブミッションを2時間の制限時間内に確実に終わらせるために、推論スクリプトを最適化した。scalerとtransformerはすべてpickleファイルから読むようにした。Kaggle GPU notebokkは
限られたスペック(2-cores CPU, 13GB Host RAM and 16GB GPU RAM)なので、workerの数とバッチサイズの最適解を探した。
バッチサイズに関して言えば、最も良かった設定はNNベースのモデルでは2048、CNNベースのモデル(めっちゃデカイしメモリは足りない)では512だった。数を大きくすれば良いというわけではなく、推論のスピードはCPU、GPU、I/Oリソースの兼ね合いに依存した。
最終サブミッションのトータル実行時間は、パブリックテストデータではBest LBとBest CVでそれぞれ1923秒と1829秒で、両方ともプライベートテストデータで2時間以内に完了した。
ソースコード
Githubにある。
https://github.com/guitarmind/kaggle_moa_winner_hungry_for_gold
まとめ
MoAの知識も医学的な知見もなかったが、このinbalancedなデータセットに機械学習/深層学習のテクニックを適用することでベストを尽くせた。この最終順位にはかなり驚いているし、汎用的なAI理論はほとんどどんな領域でもうまくいくことが分かった。
訳してみた感想
翻訳するために詳細に読んでいく中で、様々な発見があってよかったです。英語の文章で読むだけだとイマイチよく分からないところがありましたが、こうして自分の手で書いていく中で、内容がスッと入ってきました。
ブレンディングの強力さがものすごくわかりましたし、混ぜるモデルの選び方も非常に参考になりました。あと、コードコンペでサブミッションを時間内に終わらせる小技的なところもとてもおもしろかったです。