はじめに
payanottyです。
アドカレで何書こうか迷ったのですが、以前強化学習で少し遊んだことがあったので、それについて書こうかなと思います。
OpenAIGymとは
人工知能を研究する非営利企業OpenAIが作った、強化学習のシミュレーション用プラットフォームです。
様々なシミュレーション環境が用意されていて、強化学習を試すことができます。
具体的にどんな環境があるかは、以下のようにして確認できます。
from gym import envs
envids = [spec.id for spec in envs.registry.all()]
print(envids)
パックマンとかピンポンとか環境がありますが、基本的な動かし方は統一されています。
-
gym.make_env(env_name)- シミュレーション環境のインスタンスを生成する
-
gym.action_space.sample()- envごとに定義されたactionをランダムにとってくる
-
env.step(action)- あるactionを選択した後、envの状態を更新する
今回はMountainCarというゲームを題材にして、強化学習エージェントにゲームをクリアさせてみようと思います
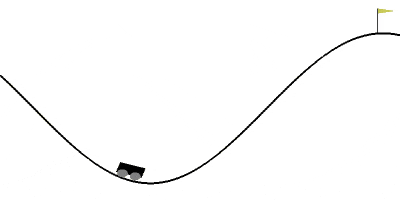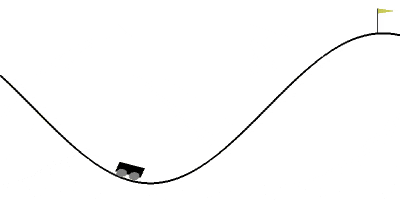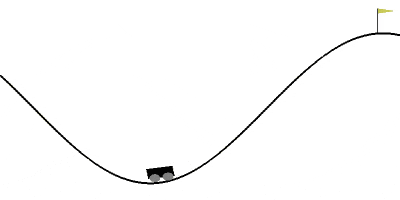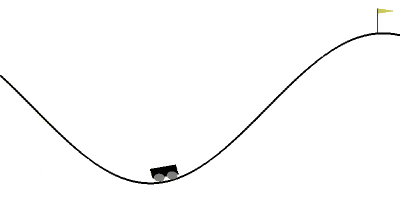
MountainCar
ルールはこんな感じです。
- なだらかな坂に車が置かれている
- 一回に取れる行動は、車を「右に押す」、「左に押す」、「何もしない」
- 何回か行動を繰り返して、最終的に車を坂の上に登らせればクリア
アプローチ
まず、車が持っている状態変数は、x座標と速度の2つです。
これらの変数から、報酬をどう決めるかによって強化学習で作ったAIの性能が変わってきそうです。
一応デフォルトで報酬関数が設定されているのですが、あまりにも疎すぎて使い物になりません(車がゴールにいたら+1、それ以外は-1)。
おおまかにx座標、速度がそれぞれ大きくなれば、大きな報酬を与えるという方針が考えられると思います。
実際、以下のような報酬関数$r$を考えれば、ゲームをクリアできるAIを作ることはできると思います。
$$
r(x) = kx
$$
$$
r(v) = kv
$$
ただこれではあまりにひねりがないので、もうひと工夫したいところです。
ここで現実世界の物理に目を向けてみたいのですが、座標と速度によって決まる量として、エネルギーがあったと思います。具体的には、y座標に比例して位置エネルギーが決まり、速度の2乗に比例して運動エネルギーが決まります。これらのエネルギーの和は、物体に外力が加わることにのみ変化します。MountainCarでいうと、車を押すという操作によって、車が持っているエネルギーが変化します。車の持っているエネルギーを増加させる方向に力を加えることを繰り返せば、やがて坂の一番上のゴールまで車を持っていくことができそうな気がします。
上のように考えて、最終的に以下の報酬関数を使ってMountainCarを解くことにしました。
$$
E(x, v) = c(g\mathrm{sin}(3x) + \frac{1}{2}v^2)
$$
$$
r(x, v) = \Delta E
$$
gは重力定数で、y座標がおよそサインカーブになっていると考えてこのような形になっています。
実際の報酬は、行動をとった後のエネルギー変化量として与えています。
実際どうだったか
報酬関数を位置エネルギー+運動エネルギーの形に設定して、20エピソード学習させてみた結果がこちらになります。
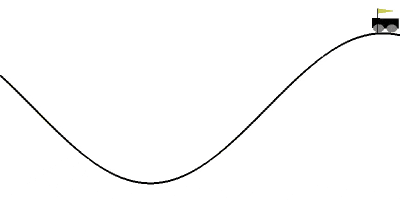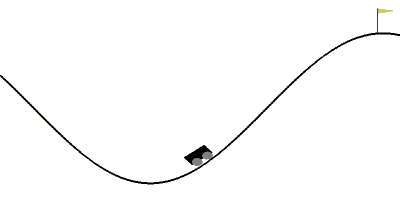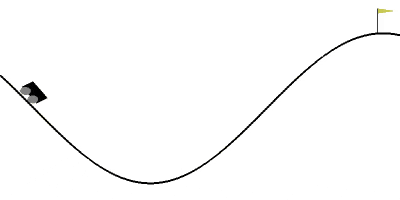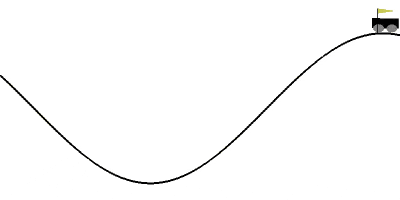
いちおう20エピソード使いましたが、学習のログを見ると6エピソード時点ですでにAIがゲームをクリアできていました。
自分が調べた範囲では10エピソード以内にクリアできた記事は見当たらなかったので、今の所これが一番早いと思います。
もしこれより早く解ける報酬関数を見つけた方がいれば、この記事のコメントで教えて下さい。
まとめ
報酬関数を変えるだけで学習効率が非常に大きく変わってくるので、よくよく検討しましょう。
実行コード
from tensorflow.keras import Input
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
import tensorflow.keras.backend as K
import tensorflow as tf
from collections import deque
# ミニバッチを選んでくるメモリの定義
class Memory:
def __init__(self, max_size=1000):
self.buffer = deque(maxlen=max_size)
def add(self, experience):
#各ステップの経験をタプル形式で格納する
#experience = (state, action, reward, next_state)
self.buffer.append(experience)
def sample(self, batch_size):
#バッファにある記憶からバッチサイズだけ抽出する
idx = np.random.choice(np.arange(len(self.buffer)), size=batch_size, replace=False)
return [self.buffer[ii] for ii in idx]
def len(self):
return len(self.buffer)
class Actor:
def get_action(self, state, episode, mainQN):
#ε-greedy法
epsilon = 0.001 + 0.9 / (1.0+episode)
if epsilon <= np.random.uniform(0, 1):
retTargetQs = mainQN.model.predict(state)[0]
action = np.argmax(retTargetQs)#最大の行動を返す
else:
action = np.random.choice([0, 1])
return action
# 損失関数を定義する
def huberloss(y_true, y_pred):
err = y_true - y_pred
cond = K.abs(err) < 1.0
L2 = 0.5 * K.square(err)
L1 = (K.abs(err) - 0.5)
loss = tf.where(cond, L2, L2)
return K.mean(loss)
class QNetwork:
def __init__(self, learning_rate=0.01, state_size=4, action_size=2,
hidden_size=10):
self.state_size = state_size
self.action_size = action_size
#インスタンス生成時にDNNを初期化する
inputs = Input(shape=(state_size, ))
dense1 = Dense(hidden_size, activation='relu')(inputs)
dense2 = Dense(hidden_size, activation='relu')(dense1)
outputs = Dense(action_size, activation='linear')(dense2)
self.model = Model(inputs=inputs, outputs=outputs)
self.model.compile(loss=huberloss, optimizer='adam')
def replay(self, memory, batch_size, gamma, targetQN):
#inputとtargetをそれぞれ0で初期化
inputs = np.zeros((batch_size, self.state_size))
targets = np.zeros((batch_size, self.action_size))
#メモリからミニバッチをサンプリングする
mini_batch = memory.sample(batch_size)
#ミニバッチの各状態に対して、行動を選択する
for i, (state_b, action_b, reward_b, next_state_b) in enumerate(mini_batch):
inputs[i:i+1] = state_b#inputのi番目に状態を代入
target = reward_b
#targetsのi番目に代入する教師信号を作っていく
if not (next_state_b==np.zeros(state_b.shape)).all(axis=1):#next_stateが存在するときに更新する
retmainQs = self.model.predict(next_state_b)[0]#価値計算
next_action = np.argmax(retmainQs)#最大の報酬を返す行動を選択する
#ベルマン方程式
target = reward_b + gamma * targetQN.model.predict(next_state_b)[0][next_action]
#targetsのi番目にmodelの出力(行動aごとのQ値の一覧)を代入する
targets[i] = self.model.predict(state_b)
#action_bをとったときのQの値を, 上で計算した値で上書きする
targets[i][action_b] = target
self.model.fit(inputs, targets, epochs=1, verbose=0)
class Environment:
def __init__(self, env, actor, memory,
mainQN, targetQN):
self.env = env
self.actor = actor
self.memory = memory
self.mainQN = mainQN
self.targetQN = targetQN
def run(self, num_episodes, max_number_of_steps,
gamma=0.99, batch_size=32):
rewards_hist = []
steps_hist = []
islearned = 0
for episode in range(num_episodes):
#環境の初期化と同時に初期状態を取得する
self.env.reset()
state, reward, done, _ = env.step(env.action_space.sample())#1step目は適当
state = np.reshape(state, (1, -1))#stateはlist型なのでnumpy_arrayに直しておく
episode_reward = 0
for t in tqdm(range(max_number_of_steps)):#1試行のループ
#if (islearned==1) and LENDER_MODE:
#env_render()
#time.sleep(0.1)
#agentにstateを与え, 行動させる
action = self.actor.get_action(state, episode, self.mainQN)
#行動に応じた次の状態と報酬を得る
next_state, reward, done, info = self.env.step(action)
next_state = np.reshape(next_state, (1, -1))
#エネルギー量の変化で報酬を定義する
reward = self.energy(next_state) - self.energy(state)
episode_reward += reward#合計報酬を更新
self.memory.add((state, action, reward, next_state))#メモリ更新
state = next_state #状態を更新
if (self.memory.len()>batch_size) and not islearned:
#mainQNのパラメータを更新する
self.mainQN.replay(self.memory, batch_size, gamma,
self.targetQN)
if done:
rewards_hist.append(episode_reward)
steps_hist.append(t+1)
print('%d episode finished after %f time steps / ep_reward %f' % (episode+1, t+1, episode_reward))
if episode%2==0:
#2エピソードに1回, ターゲットネットワークを更新する
#行動決定と価値計算のネットワークを同じにする
self.targetQN.model.set_weights(mainQN.model.get_weights())
break
return rewards_hist, steps_hist
#位置エネルギー+運動エネルギーが大きいほど報酬が高くなるように設定する
def energy(self, state):
x = state[0, 0]#位置(横方向)
g = 0.0025#重力定数
v = state[0, 1]#速度
c = 1 / (g*np.sin(3*0.5) + 0.5*0.07*0.07)#正規化定数
return c*(g*np.sin(3*x) + 0.5*v*v)
hidden_size = 200
learning_rate = 0.0001
mainQN = QNetwork(hidden_size=hidden_size, learning_rate=learning_rate,
state_size=2, action_size=3)
targetQN = QNetwork(hidden_size=hidden_size, learning_rate=learning_rate,
state_size=2, action_size=3)
memory = Memory(max_size=10000)
actor = Actor()
env = gym.make("MountainCar-v0")
Env = Environment(env, actor, memory, mainQN, targetQN)
rewards_hist, steps_hist = Env.run(num_episodes=20, max_number_of_steps=200)