はじめに
皆さんStep Functions使ってますか?
今回はStep Functionsがいかに簡単で可能性があるのか、を伝えるために入門記事を書いてみようと思います。
Step Functionsは基礎部分を理解すればある程度使いこなすことができるので、皆さんぜひ使ってみてください。
作るステートマシンの全体像
今回はサンプルとして複数のバケットを空にするようなステートマシンを作成します。
画面からバケットを空にするのはボタンを押すだけなので簡単ですが、自動化しようと思うとコードを書かないといけないので面倒です。
GUIを使ってステートマシンを作って、定期起動すれば自動化できるので、ノーコードで実現できるので便利ですよね?ね???
下準備
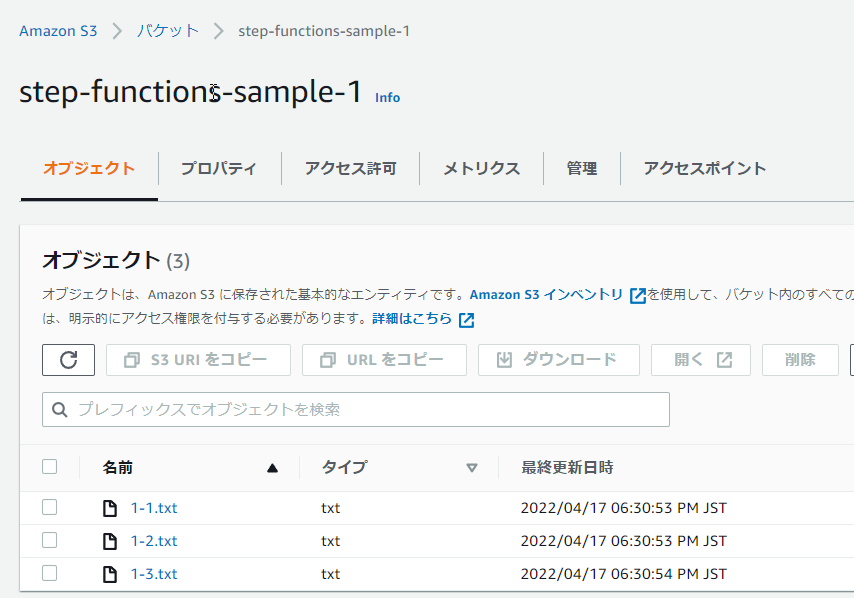
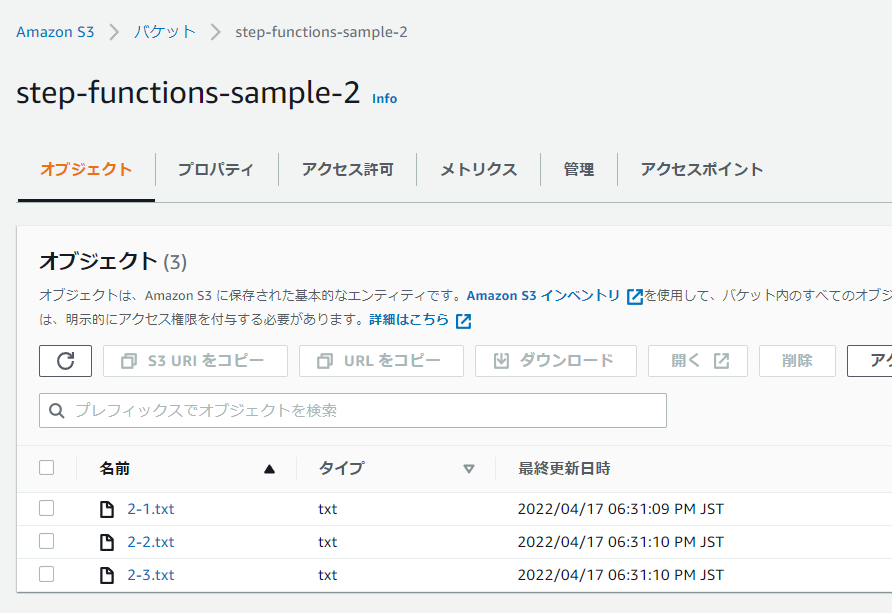
まず、名前は何でもいいのでバケットを2つ作成してください。
また、それぞれのバケットに適当なファイルを保存してください。
今回は以下2つのバケットを作成して、それぞれのバケットにファイルを3つ作成しました。
- step-functions-sample-1
- step-functions-sample-2
Step Funcctionsのベースを作成
「Step Functions」のページから「ステートマシンの作成」をクリックします
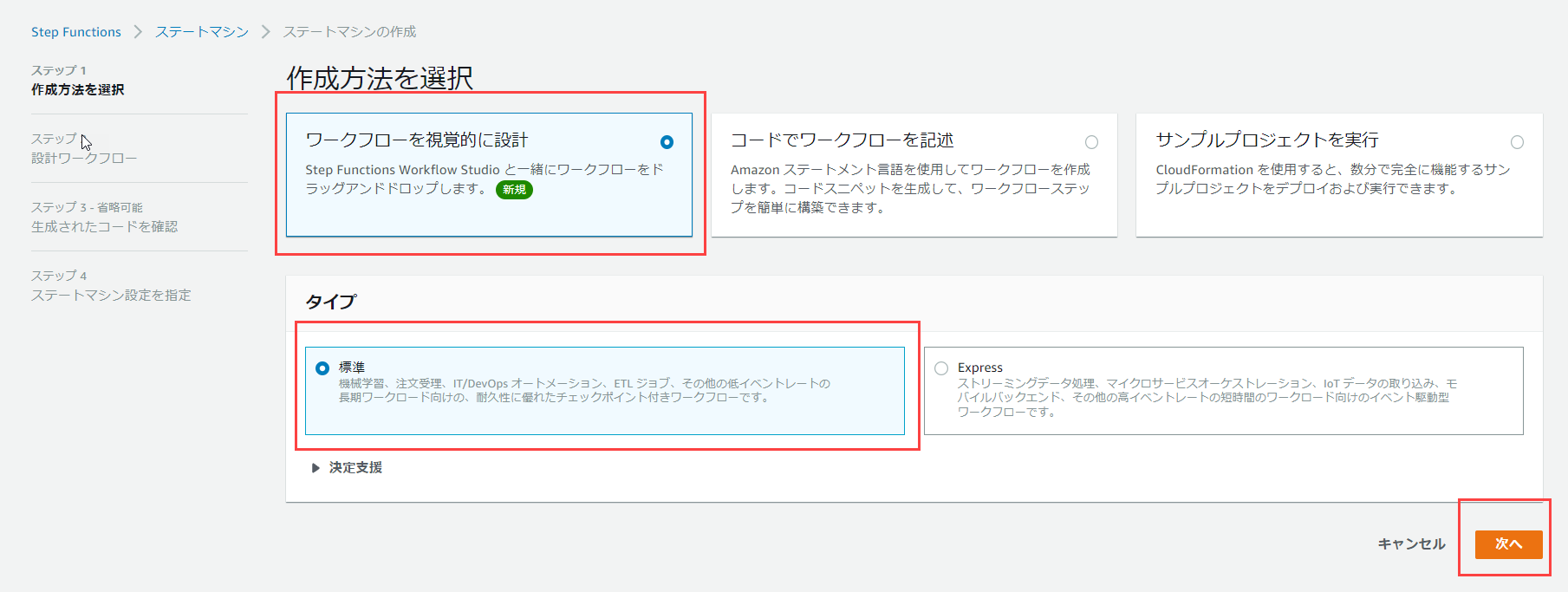
以下の画像の通りに選択して、「次へ」をクリックします。
左上の検索欄に「ListObject」と入力します。
すると絞り込まれた結果から「ListObjectsV2」をドラッグアンドドロップして、「最初の状態をここにドラッグ」の部分に移動させます。
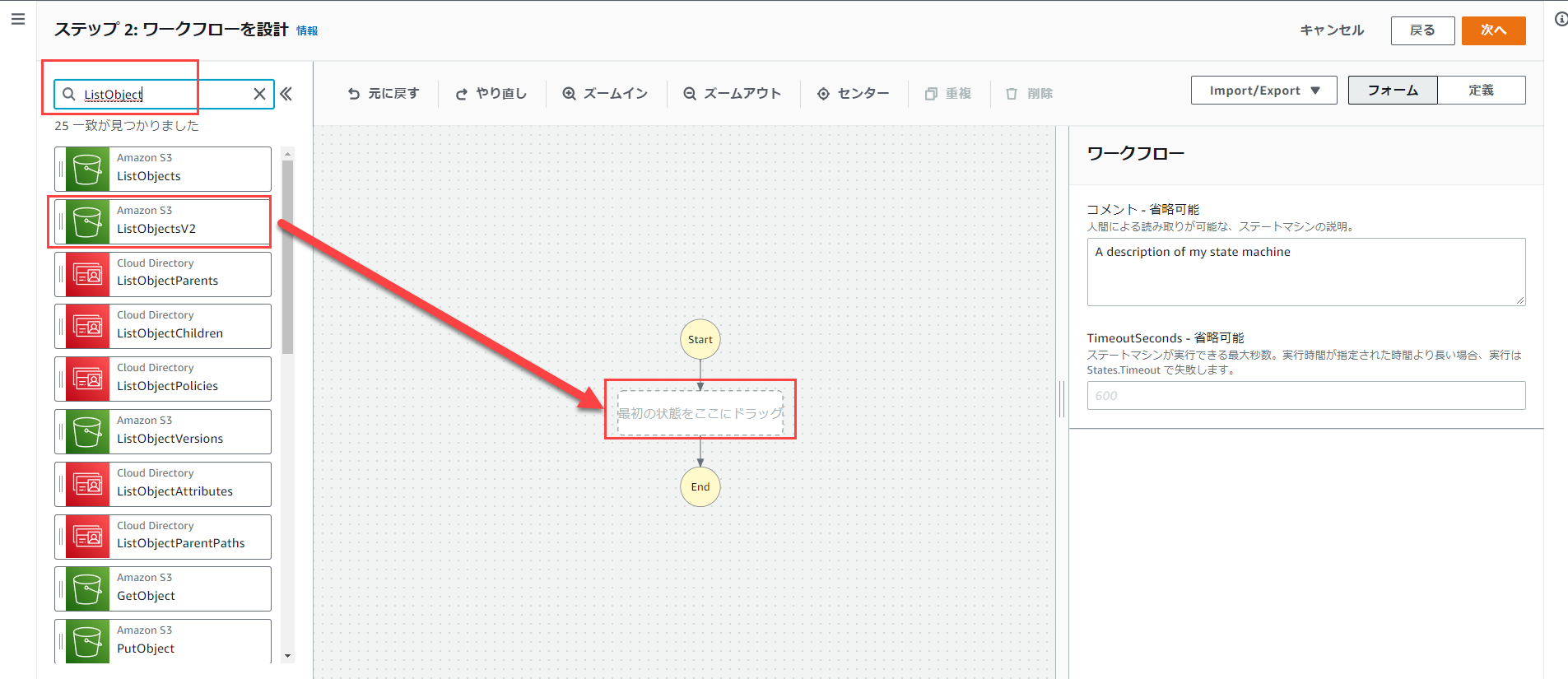
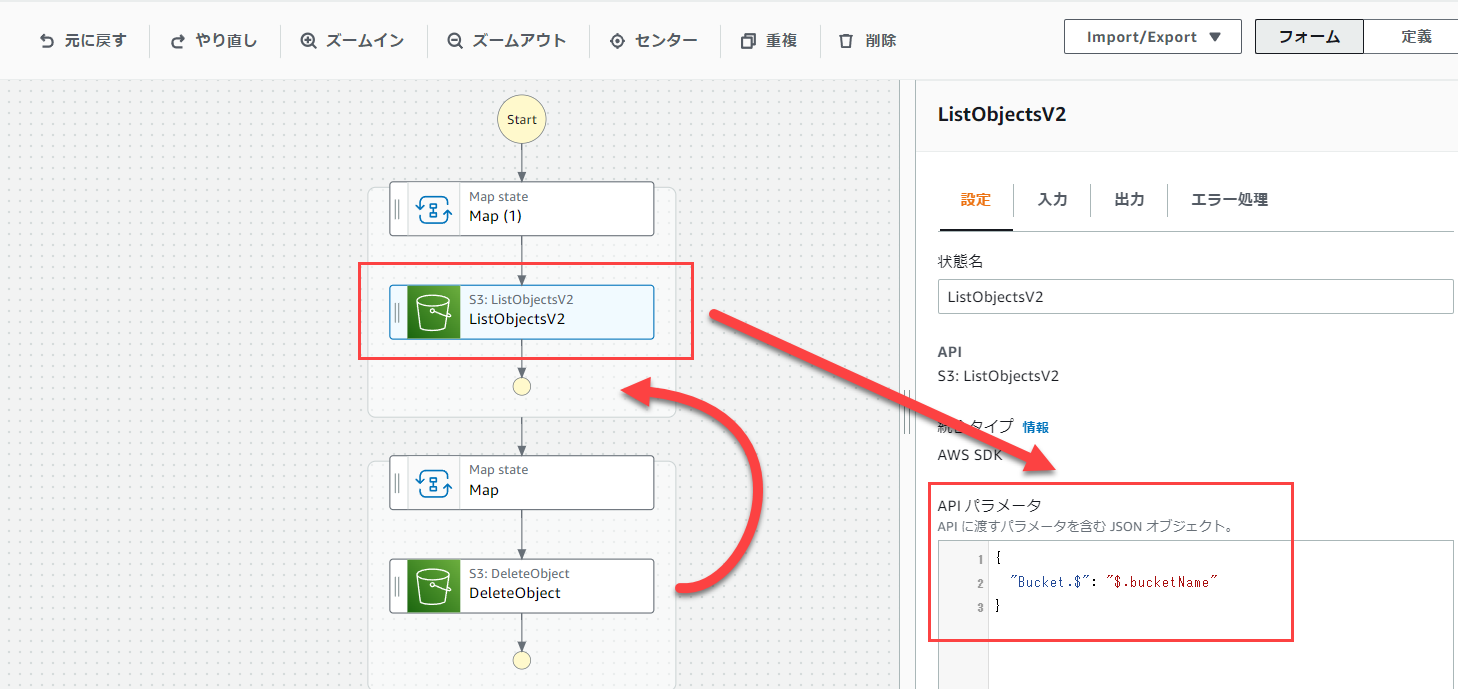
その後、右下の「APIパラメータ」の部分を修正し、作成したバケット名を入力します。
その後、右上の「次へ」をクリックします。
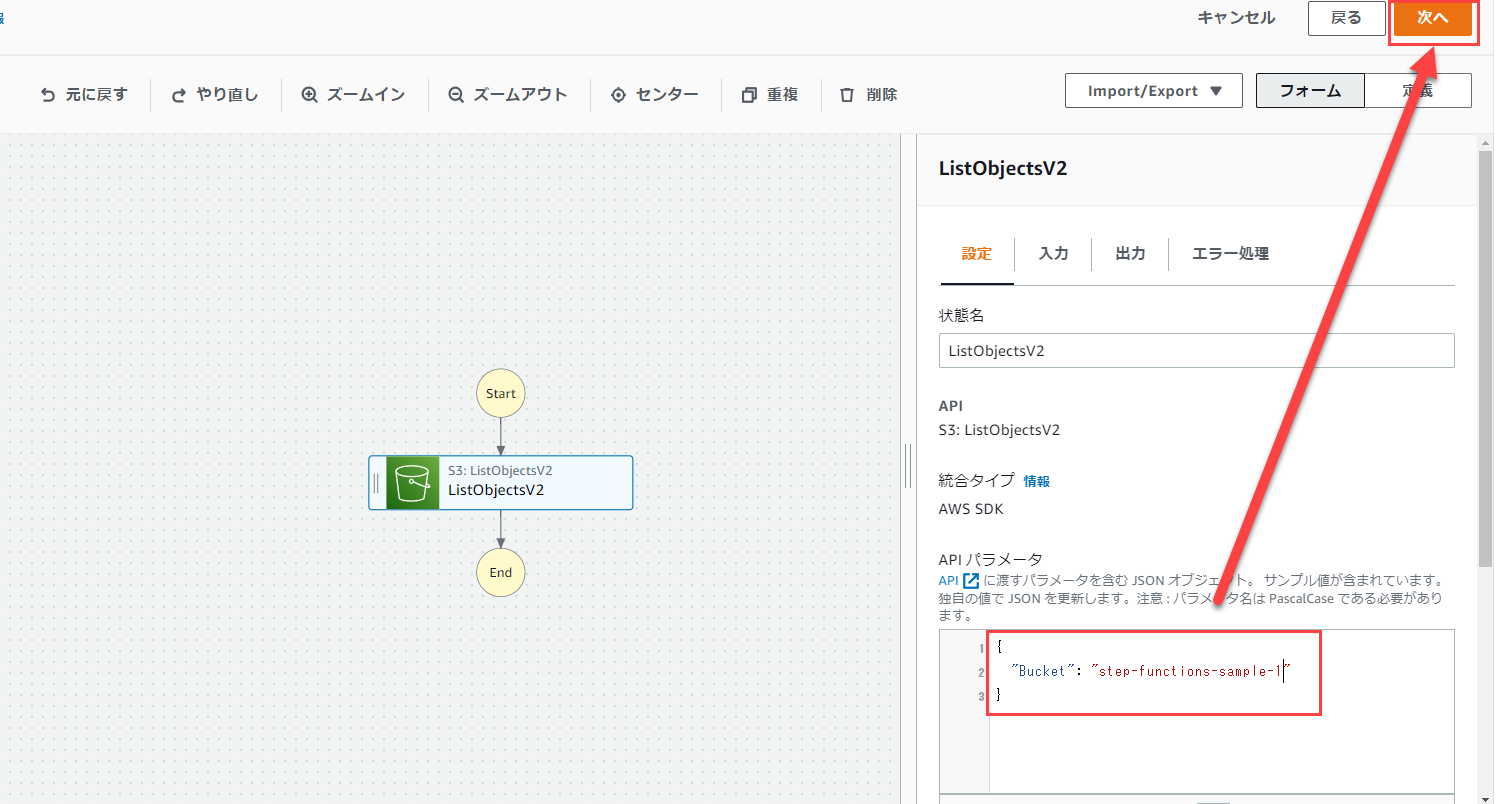
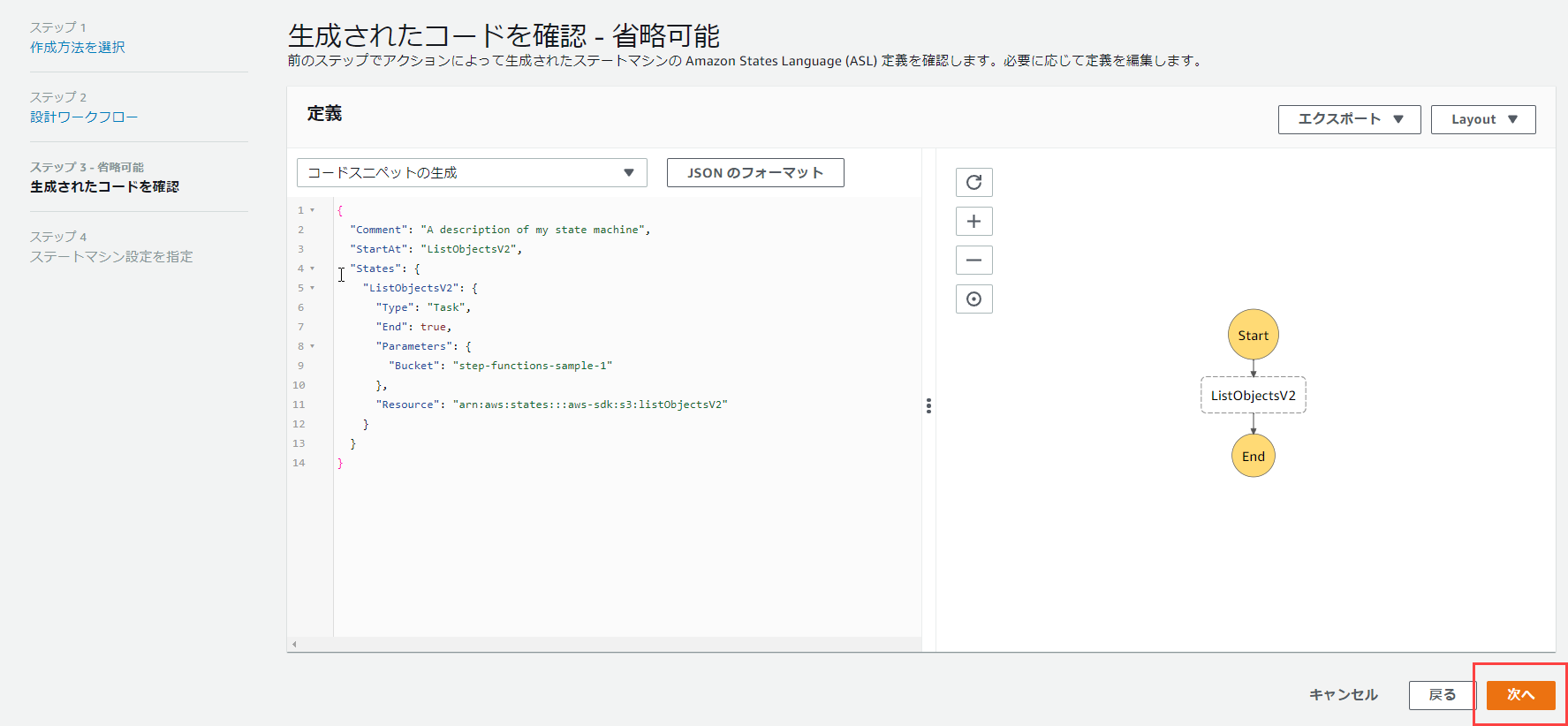
右下の「次へ」をクリックします。
名前を適宜変更し、ルールは新規作成を選択して右下の「ステートマシンの作成」をクリックします。
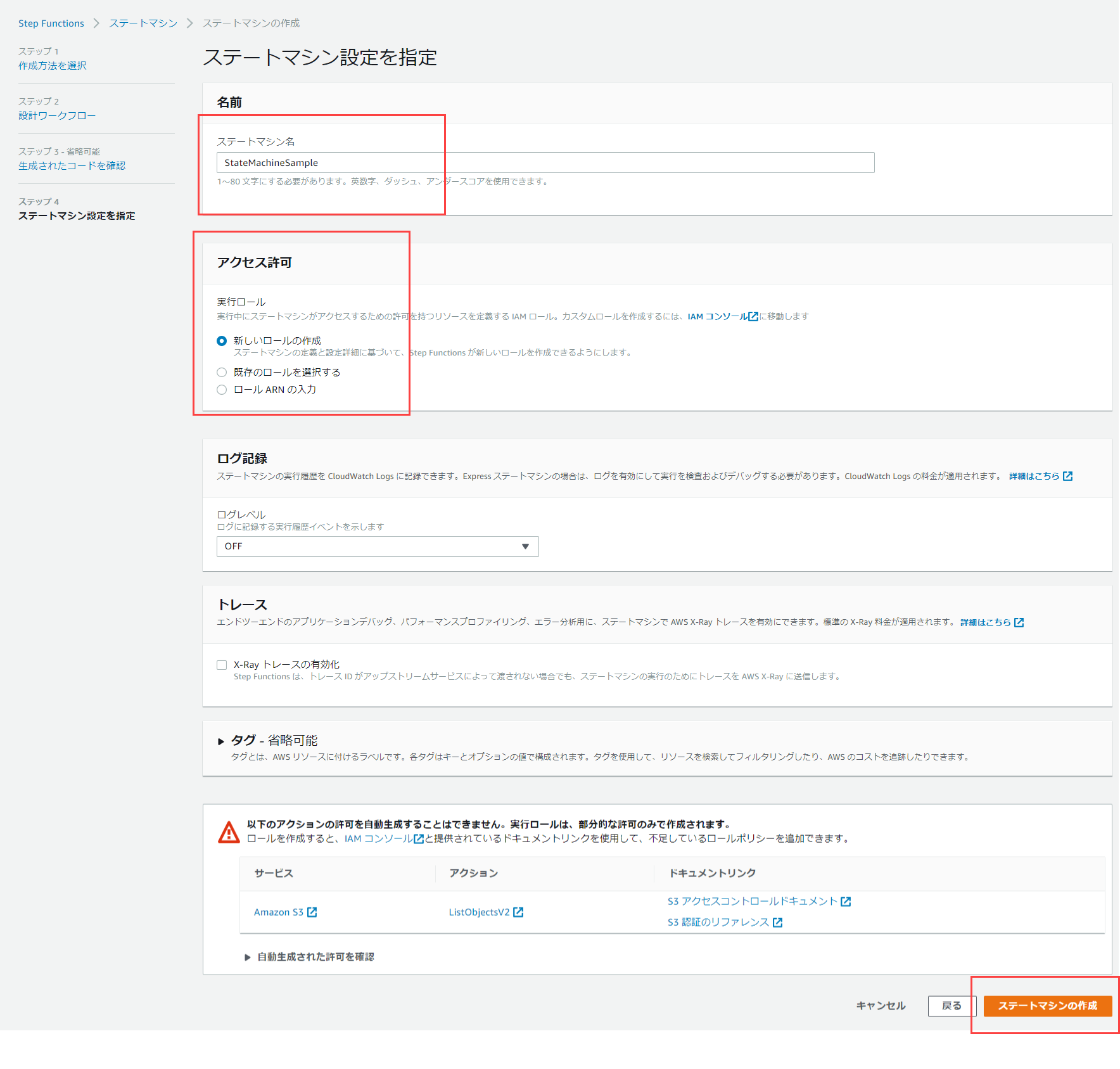
IAMロールのリンクをクリックし、該当のロールに「AmazonS3FullAccess」をアタッチしてください。
※今回はサンプルなので強い権限を当てていますが、本来は権限を制限する必要があるのでご注意ください。
Step Functionsの画面に戻り、「実行の開始」ボタンを押します。
表示される画面はデフォルトのまま、右下の「実行の開始」をクリックします。
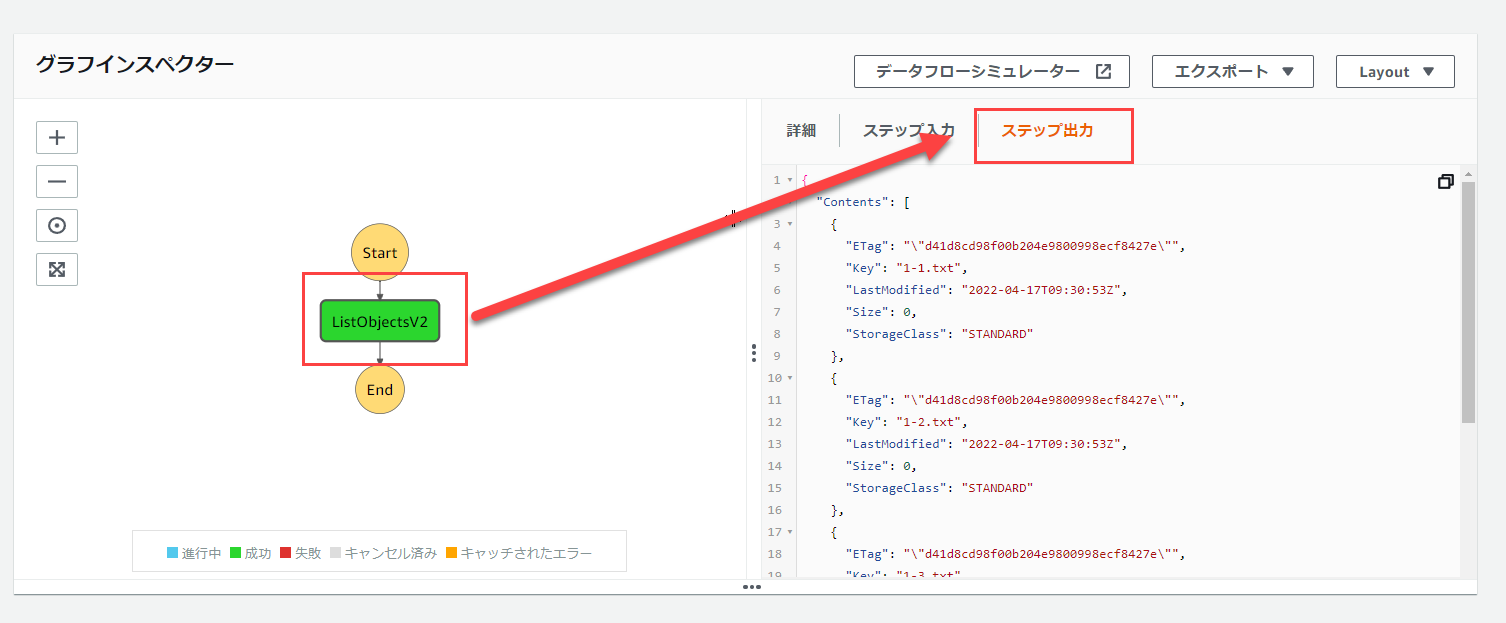
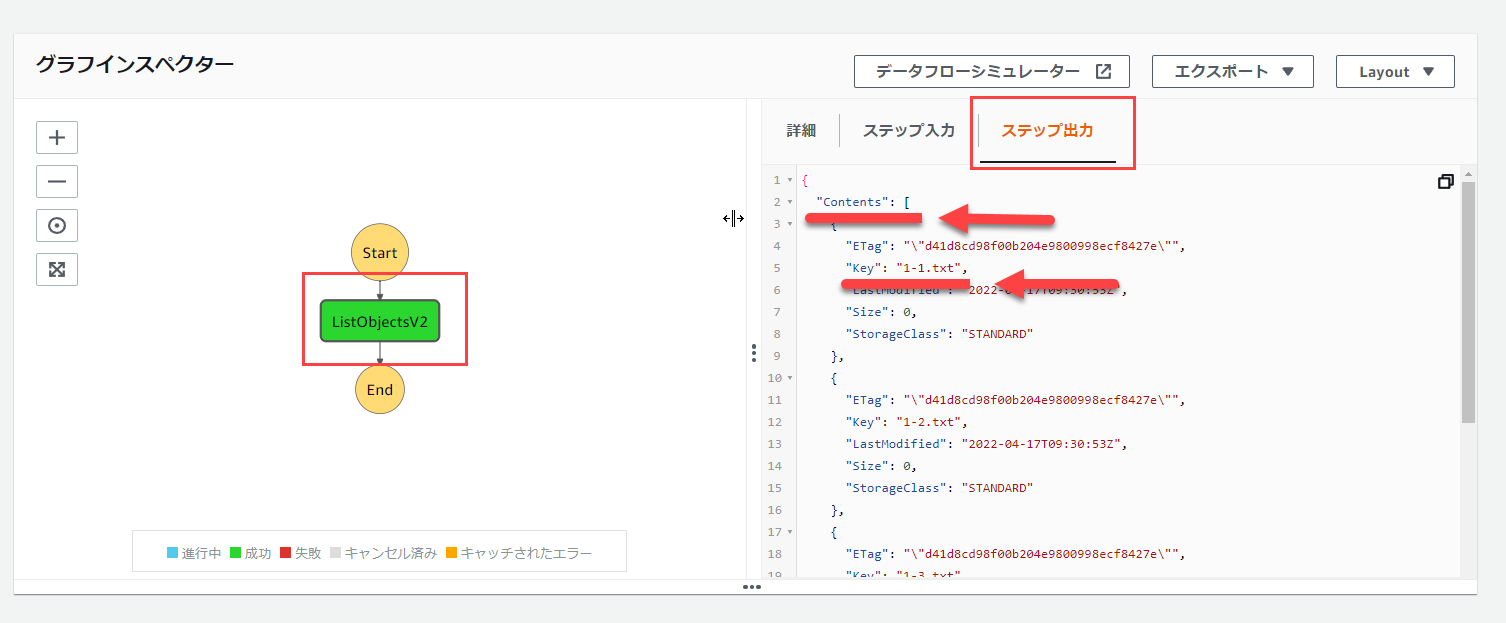
以下の画像の通り、グラフインスペクター内の「ListObjectsV2」の部分をクリックし、「ステップ出力」をクリックします。
すると、該当のS3バケットの中身が表示されます。
(Keyの部分がオブジェクト名になってます)
S3バケット内のオブジェクトを削除できるように編集する
では、このステートマシンを編集しましょう。
右上の「ステートマシンの編集」をクリックします。
「Workflow Studio」をクリックします。
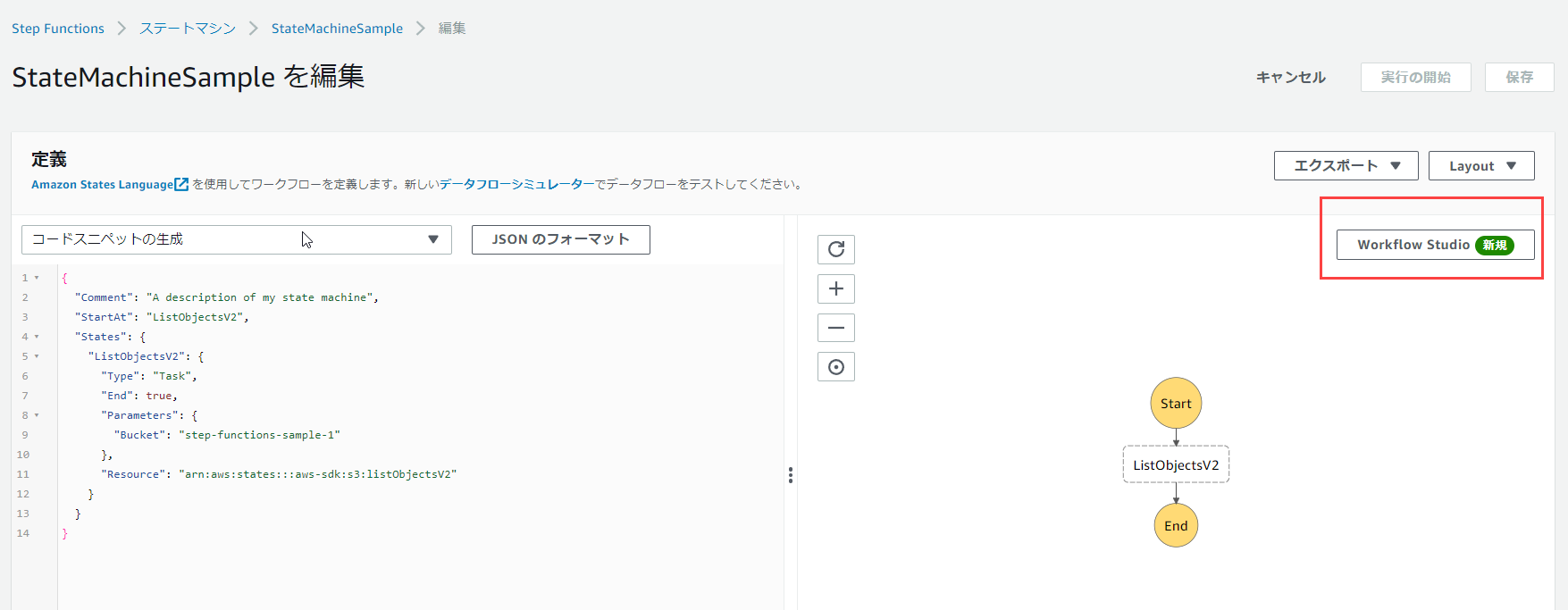
今回から念のため、タイムアウトを設定します。
ステートマシンの実行が想定を超えて実行されることを防ぐためです。
今回は600(10分)を入力します。
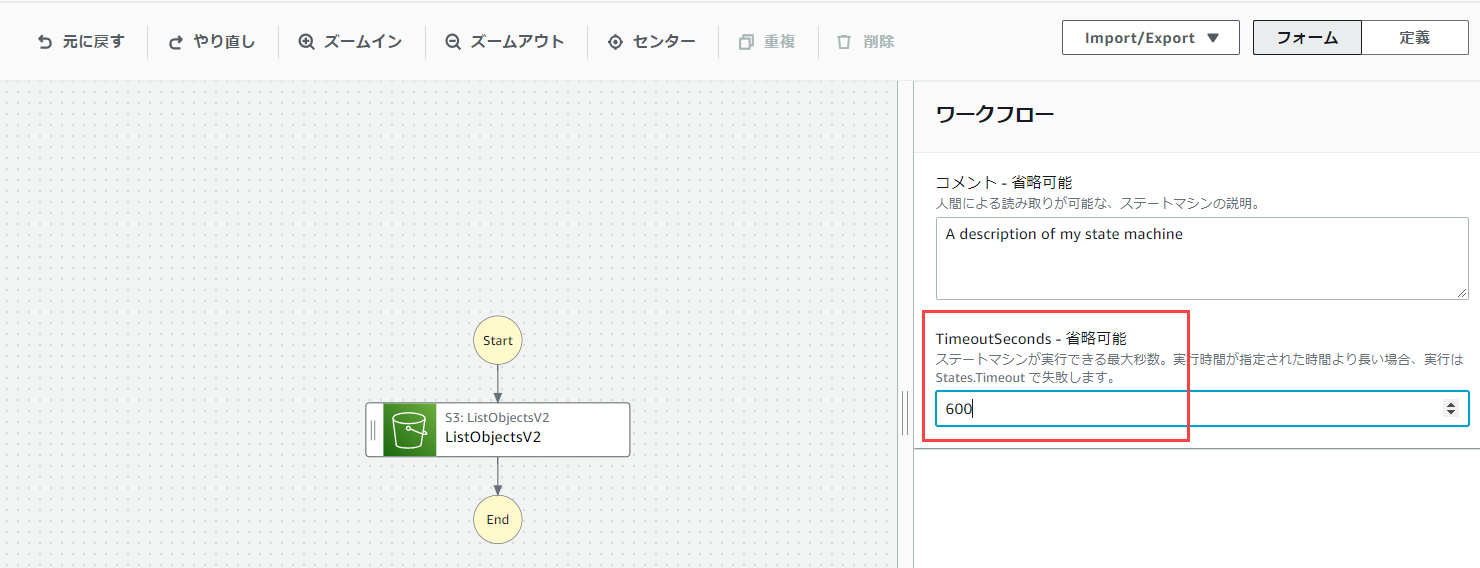
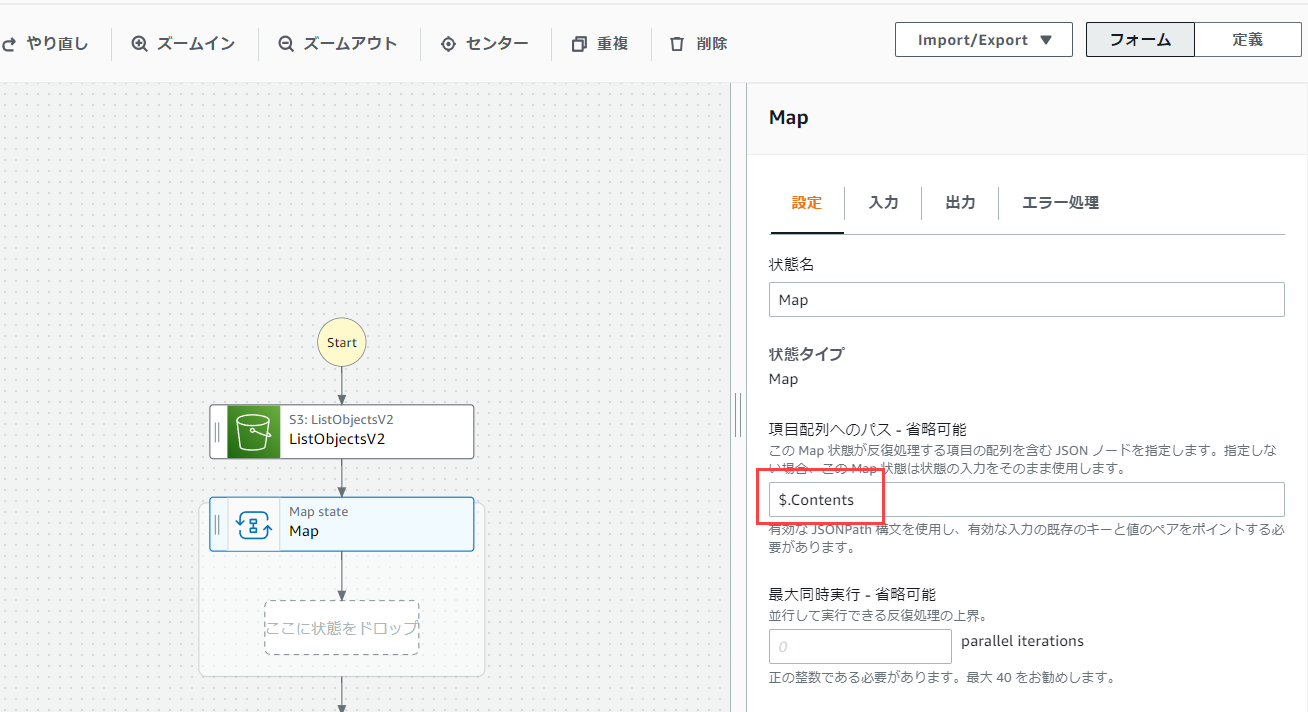
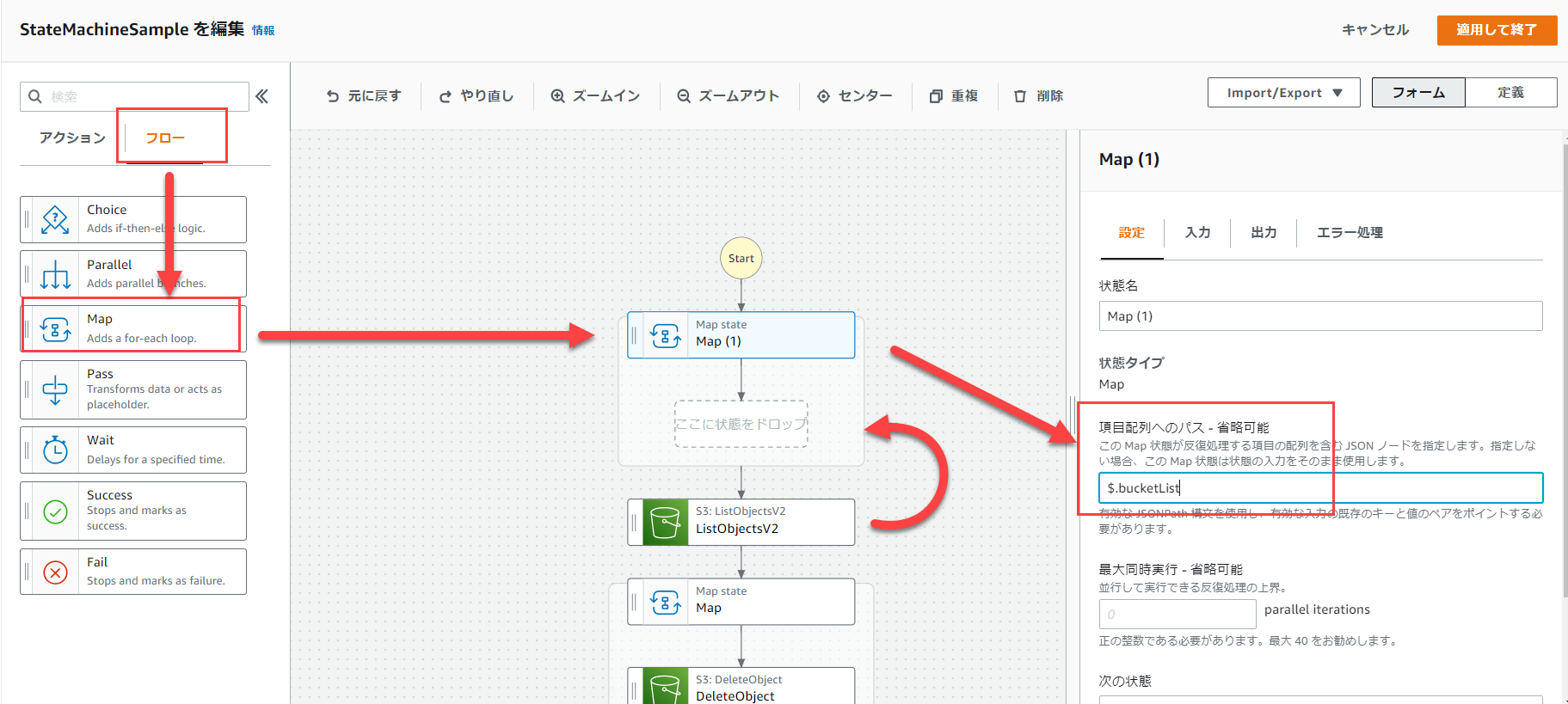
「フロー」から「Map」を選択します。
ListObjectsV2で取得したオブジェクトの一覧を削除するため、オブジェクト一覧に対してループ処理を実行したいからです。
※Mapはデフォルトでは原則処理が並列で実行されます。順次実行も設定で可能です。
マップ
先ほどListObjectsV2の出力を確認しましたよね。
出力としては「Contents」の中に配列が格納されており、その配列の「Key」がオブジェクト名でした。
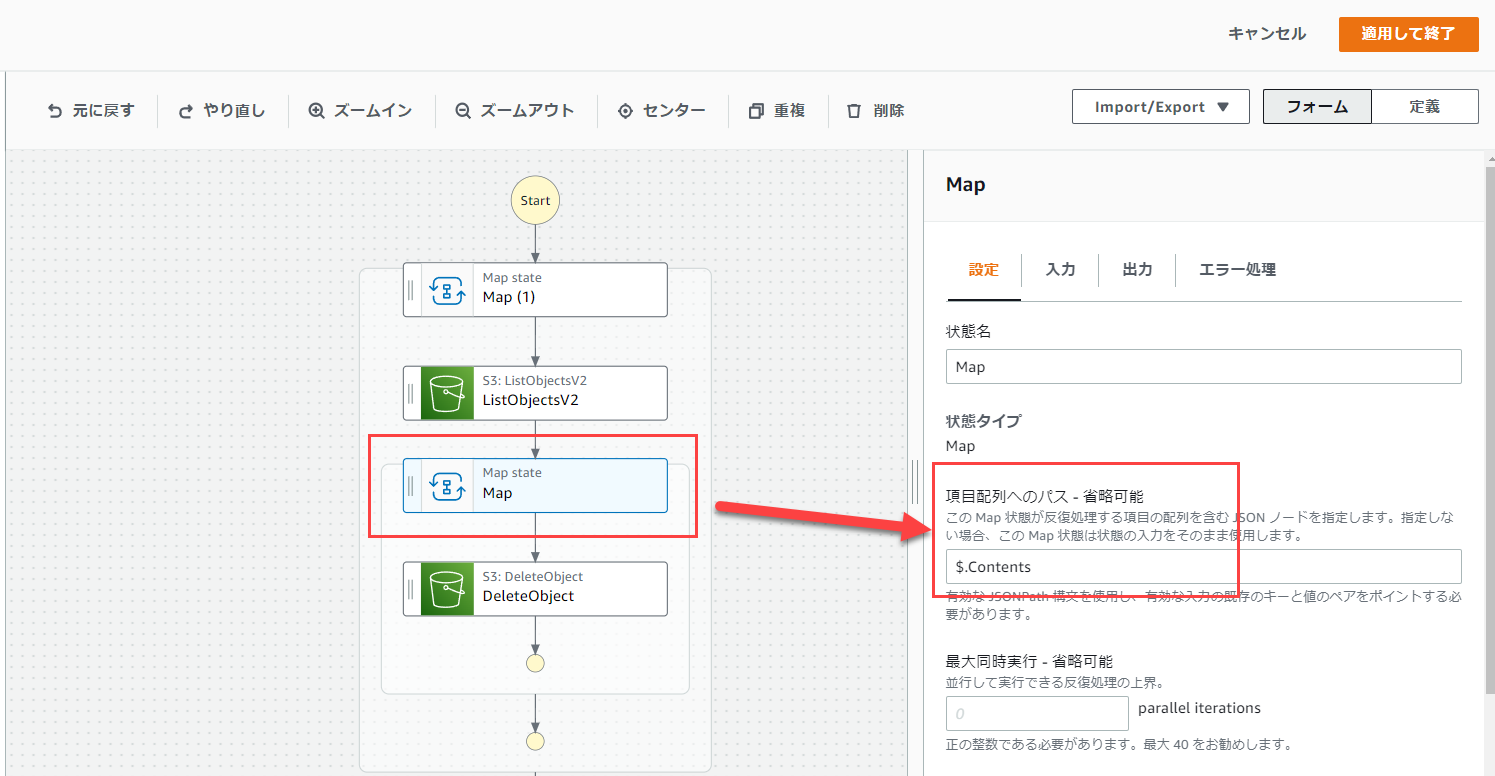
よって、配列項目へのパスに「$.Contents」と入力します。
次に、Map内の処理を追加します。
今回はオブジェクトを削除したいので、「DeleteObject」を選択して、ドラッグアンドドロップします。
APIパラメータにはバケット名は固定値を入力し、Keyの部分は下記画像のようにしてください。
その後、「適用して終了」をクリックします。
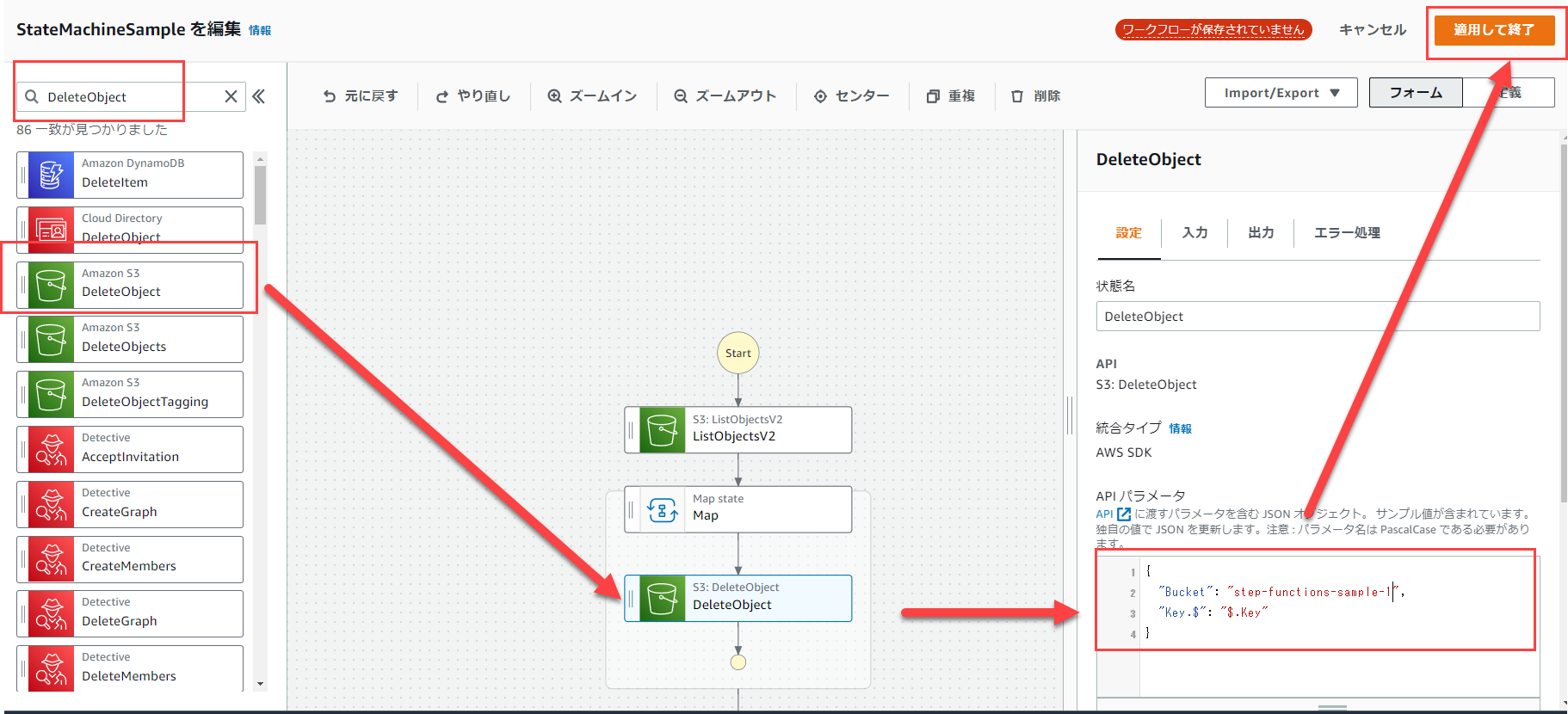
ここで、"Key.$": "$.Key"ってどこから来たのか、と思われるかもしれません。
簡単に説明すると、入力値を動的に参照させたい場合、その属性名の末尾に「.$」をつけ、属性値の先頭は「$.」で始めるJson Pathで指定する、ということになります。
今回は「Key」の部分を入力から動的に値を決めたかったので、"Key.$": "$.Key"のようにしています。
キーバリューペア
なお、値の「Key」については、以下の画像の通り配列の要素の「Key」の部分がオブジェクト名だとわかっているので、その値を入力しています。
右上の保存を押します。
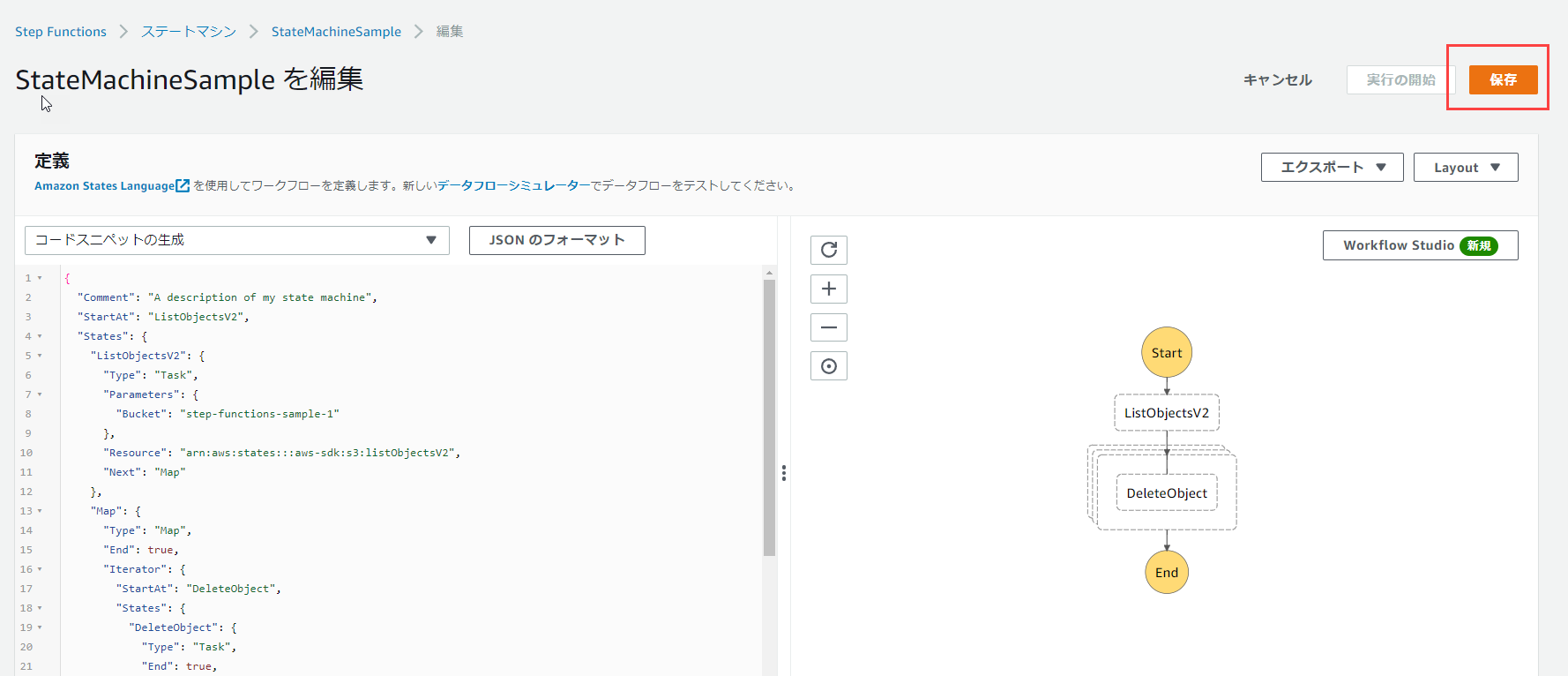
「保存を続行します」をクリックします。
では、もう一度ステートマシンを実行してみます。
実行結果のグラフインスペクターが以下のようになっていればOKです。
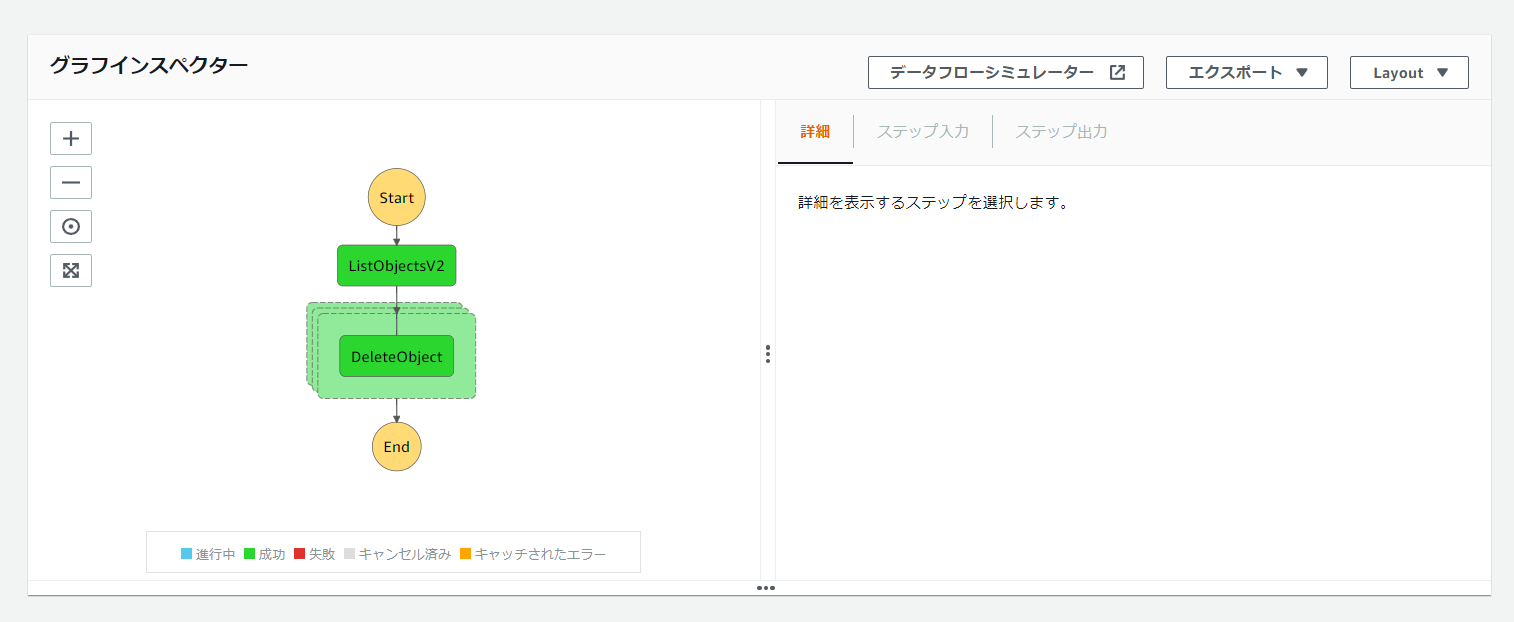
しっかり該当のバケットのデータが削除されていますね。
バケット名を動的に変えることができるように編集
先ほどまで、バケット名を固定で入れていましたが、バケット名を入力値として与えて、動的に変更できるように修正しましょう。
また、複数のバケットを指定できるようにもしてみましょう。
入力値のイメージは以下となります。
{
"bucketList": [
{"bucketName": "step-functions-sample-1"},
{"bucketName": "step-functions-sample-2"}
]
}
前回と同様の手順で「Workflow Studio」を開いてください。
フローからMapを選択し、ステートマシンの先頭に挿入します。
その後、項目配列へのパスは「$.bucketList」と入力します。
その後、下のListObjectsV2をMap内に入れます。
ListObjectsV2を選択し、APIパラメータを下記画像のように変更します。
また、二個目のMapを一つ目のMapの中に入れます。
二個目のMapを選択して、項目配列へのパスが「$.Contents」となっていることを確認します。
次に、Mapの入力欄を以下のように編集して下さい。
この部分の設定を変更することで、Mapへの入力データをカスタマイズすることができます。
ListObjectV2の配列内にはバケット名のデータがないので、Mapで処理した際に都合が悪いです。(理由はオブジェクトを削除する際にバケット名も必要なため)
よって、入力内容をカスタマイズして、バケット名とオブジェクトキーの両方を配列の処理に含めることができるように修正します。
{
"bucketName.$": "$.Name",
"ContextValue.$": "$$.Map.Item.Value"
}
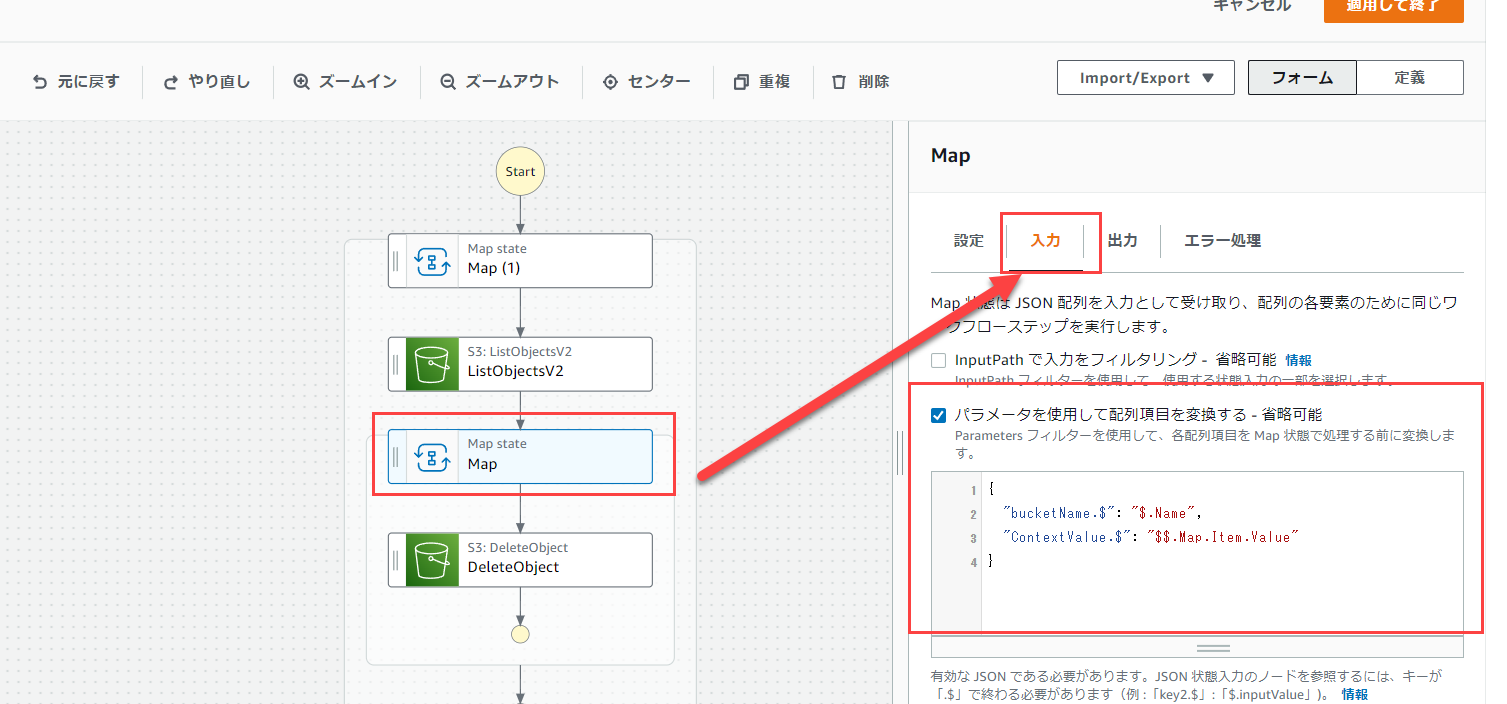
ここで、"bucketName.$": "$.Name",と"ContextValue.$": "$$.Map.Item.Value"がどこから出てきたのか、と疑問に思われるかもしれません。
順番に解説します。
まず、"bucketName.$": "$.Name",ですが、ListObjectsV2の出力結果は以下のようになっています。
{
"name": "ListObjectsV2",
"output": {
"Contents": [
{
"ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
"Key": "1-1.txt",
"LastModified": "2022-04-17T13:22:56Z",
"Size": 0,
"StorageClass": "STANDARD"
},
{
"ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
"Key": "1-2.txt",
"LastModified": "2022-04-17T13:22:57Z",
"Size": 0,
"StorageClass": "STANDARD"
},
{
"ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
"Key": "1-3.txt",
"LastModified": "2022-04-17T13:22:57Z",
"Size": 0,
"StorageClass": "STANDARD"
}
],
"IsTruncated": false,
"KeyCount": 3,
"MaxKeys": 1000,
"Name": "step-functions-sample-1",
"Prefix": ""
},
"outputDetails": {
"truncated": false
}
}
出力結果をどうやって確認するかというと、ステートマシンの実行結果から見ることができます。
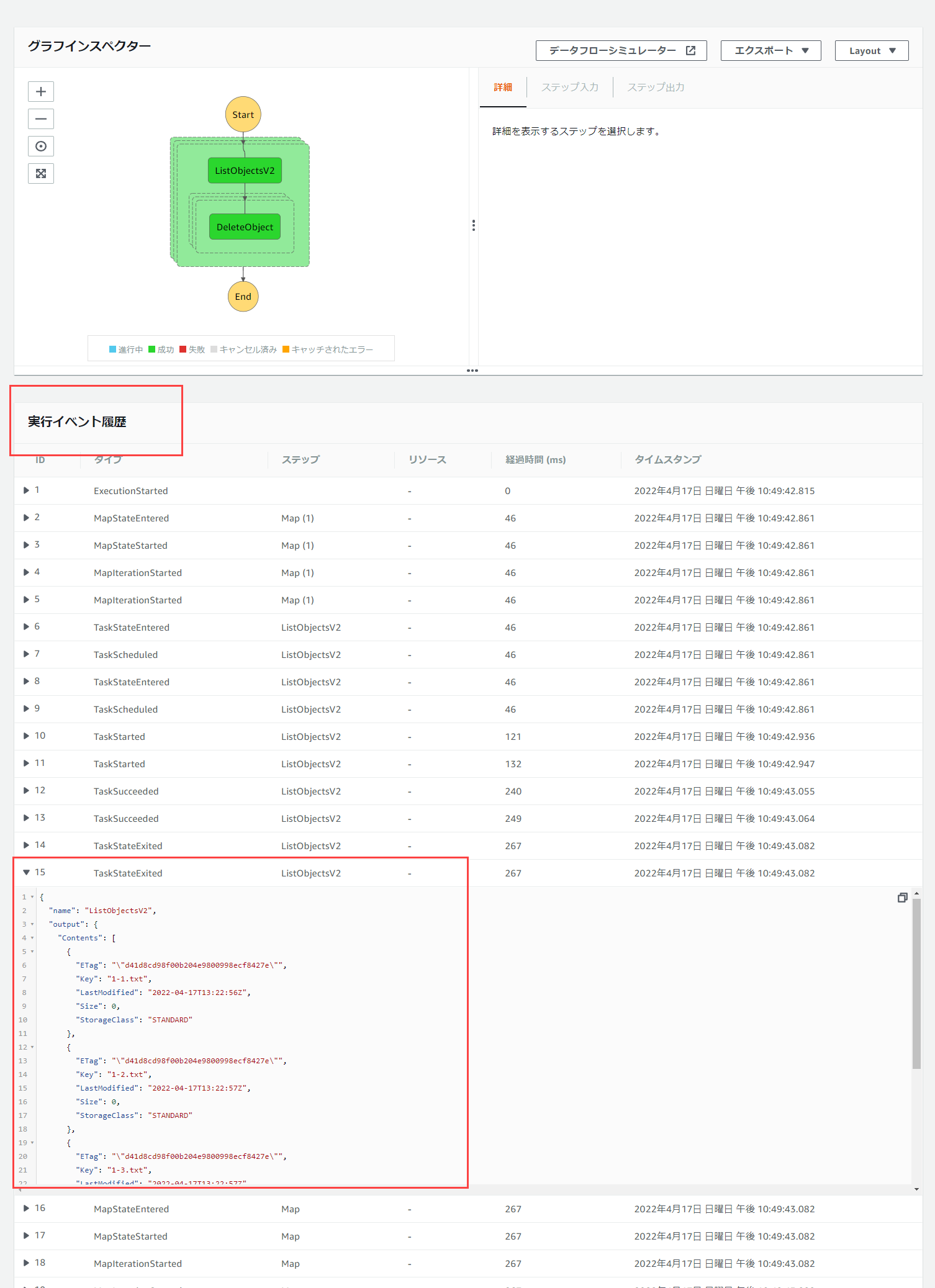
注目するのは「output」の部分で、この内容が次のinputになります。
なので、次のインプットであるMapにはこのoutputの内容が入るわけです。
そして、今回利用したいのはバケット名なので、outputの中のNameという部分がバケット名に当たります。
ということから、"bucketName.$": "$.Name",となっていたわけです。
次に"ContextValue.$": "$$.Map.Item.Value"の部分です。
詳細は以下のリファレンスを参照頂きたいのですが、今回のように書けば、入力値をContextValueの中に入れることができます。
マップ状態のコンテキストオブジェクトデータ
実質、入力値をマージすることができるというわけですね。
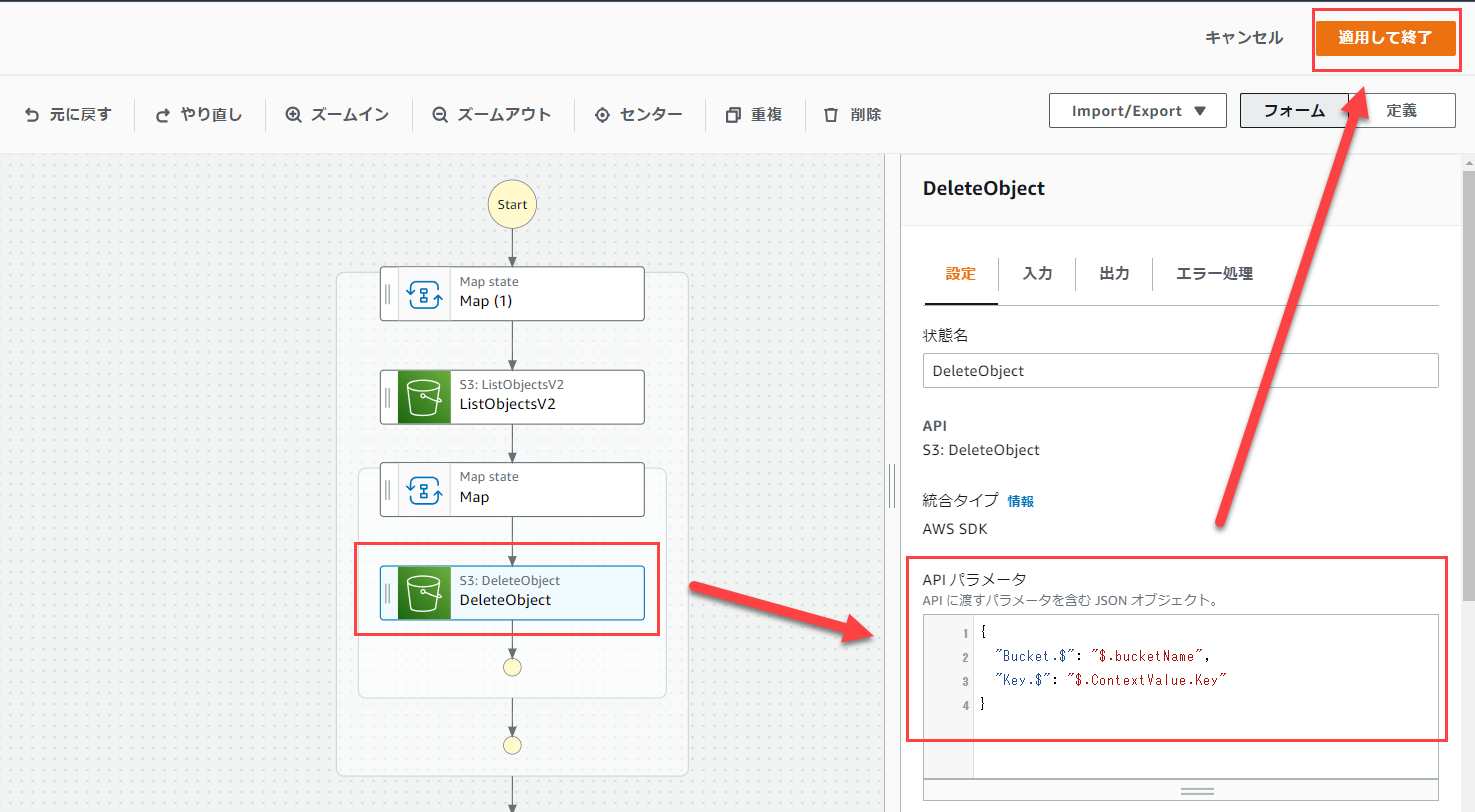
最後に、DeleteObjectの内容を以下のように修正します。
修正後、適用して終了、その後、保存してください。
{
"Bucket.$": "$.bucketName",
"Key.$": "$.ContextValue.Key"
}
再度入力値を以下のようにして実行します。
この際に、対象とするバケットに必ずオブジェクトが1つ以上存在するようにしてください。
バケット内にオブジェクトが存在しないとエラーになります。
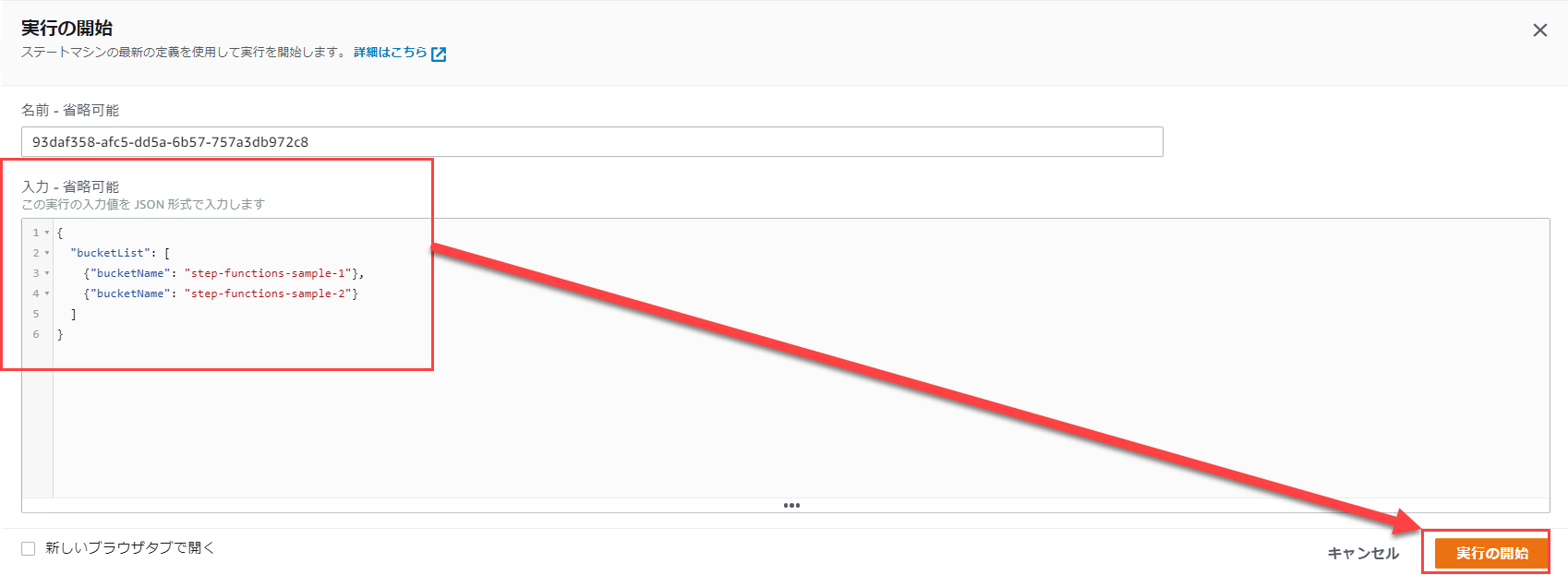
グラフインスペクターが以下のようになっていればOKです。
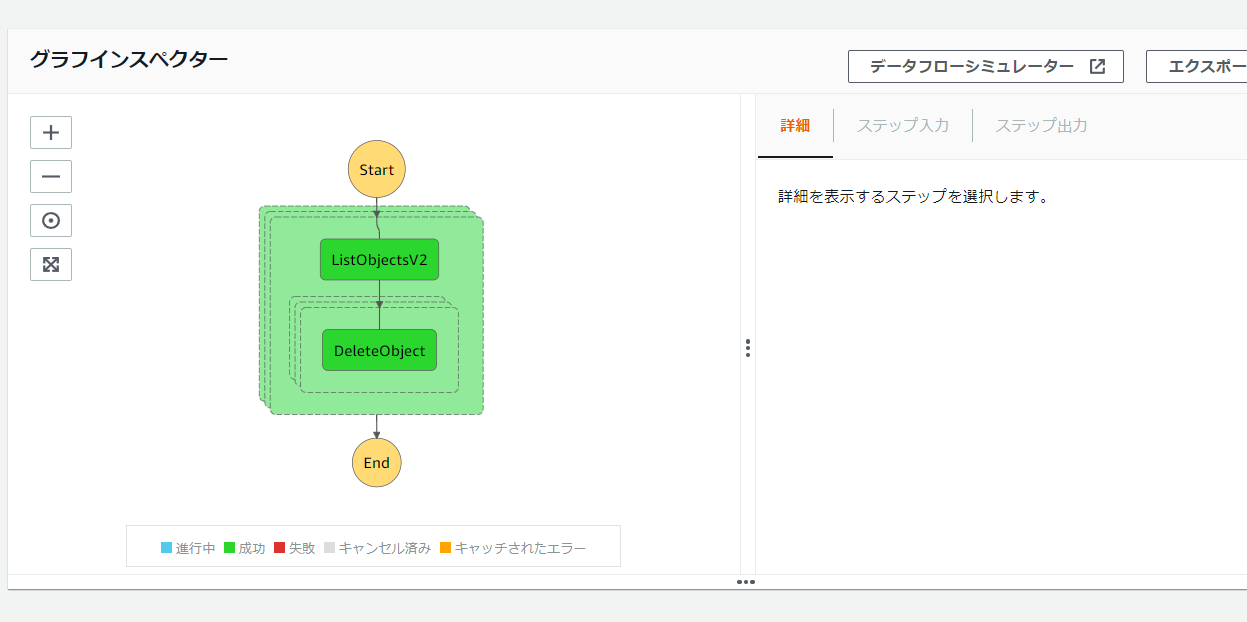
IF条件を追加する
先ほど、バケット内にオブジェクトが1件も存在しないとエラーとなる、と書きました。
実際に実行してみると、以下のようなエラーになります。
{
"error": "States.ReferencePathConflict",
"cause": "Unable to apply step \"Contents\" to input {\"IsTruncated\":false,\"KeyCount\":0,\"MaxKeys\":1000,\"Name\":\"step-functions-sample-1\",\"Prefix\":\"\"}"
}
バケット内にオブジェクトが1件もないとListObjectsV2のouptutにContentsが存在しなくなるので、参照エラーが起きている、ということです。
そこで、IF条件を追加してContentsが無ければ次の処理をスキップするような条件に変更してみます。
再度Workflow Studioを開いてください。
フローから「Choise」を選択し、ListObjectsV2の後に差し込みます。
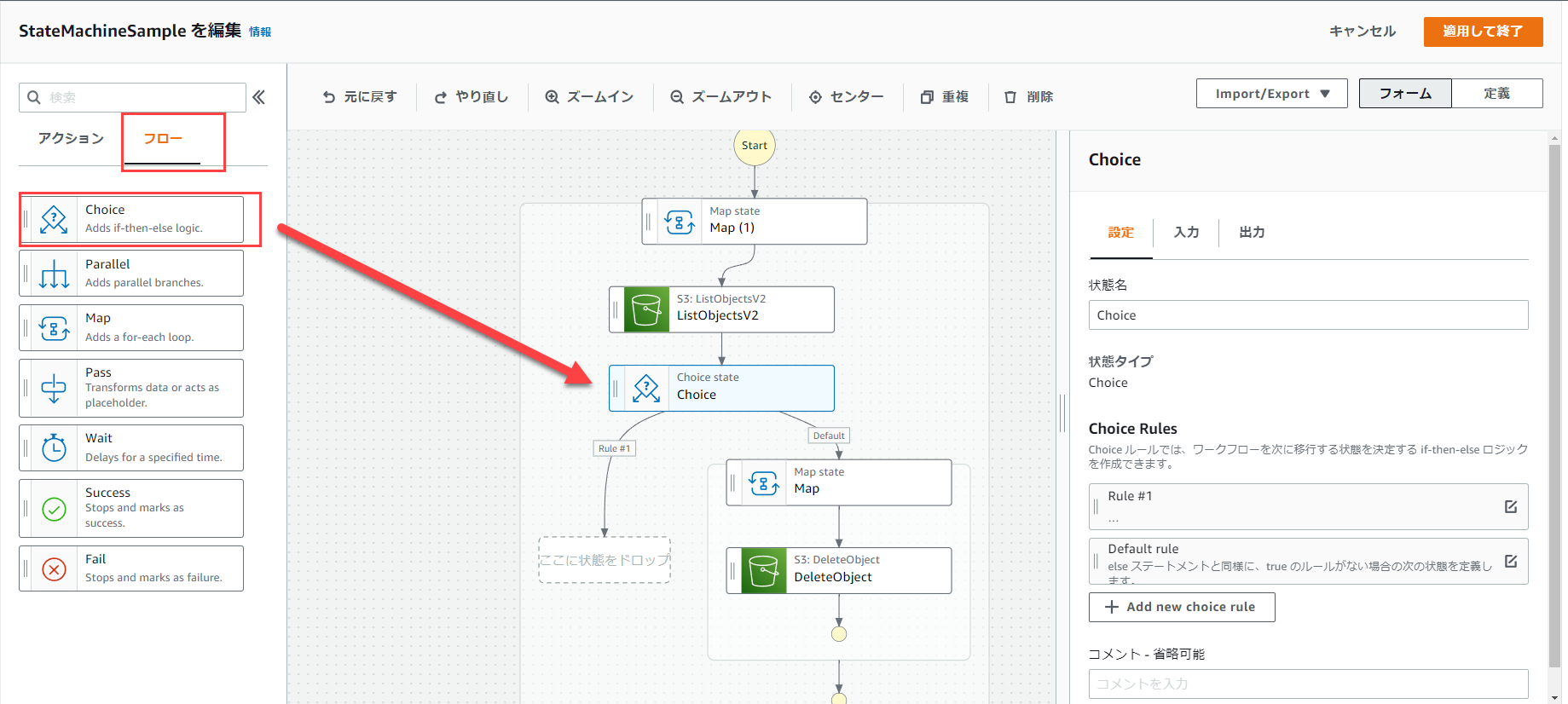
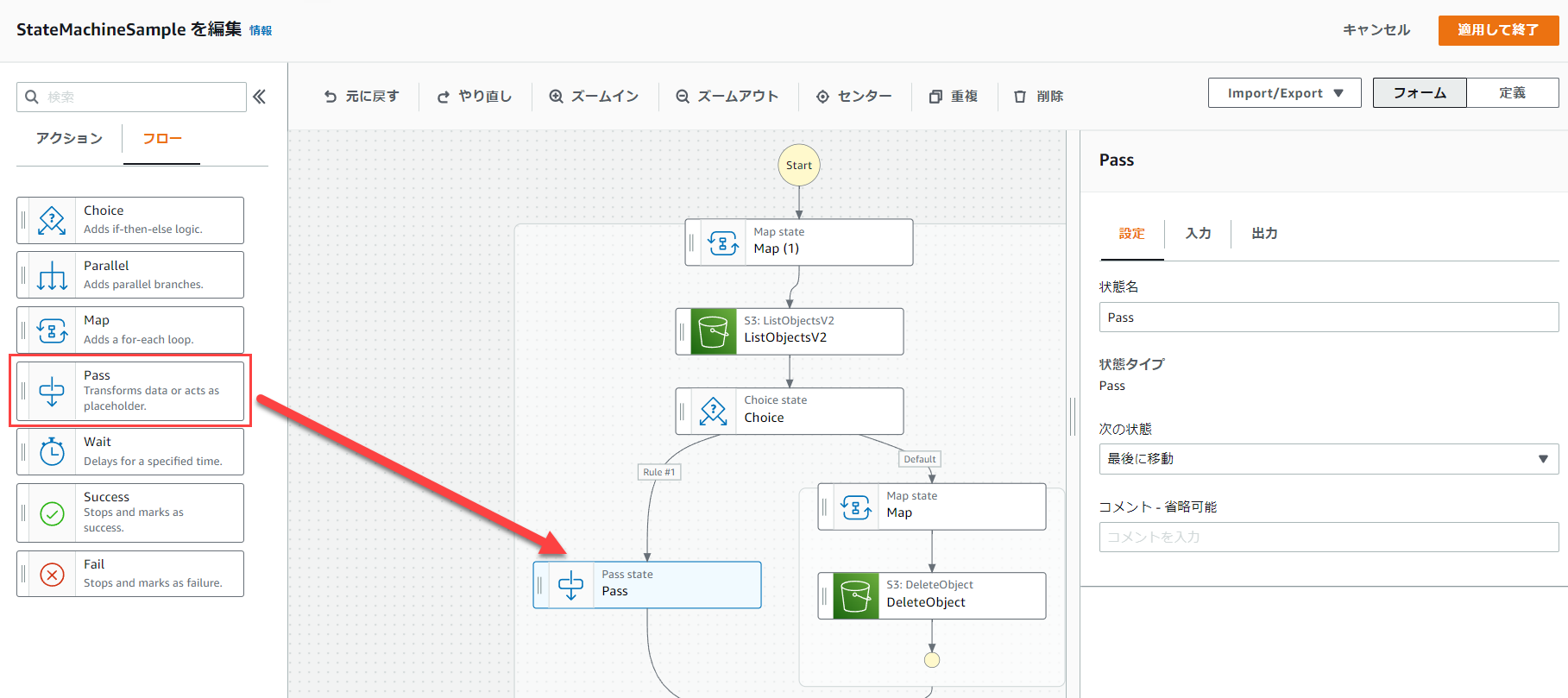
次にChoiseの「Rule #1」の下の枠に、「Pass」を入れます。
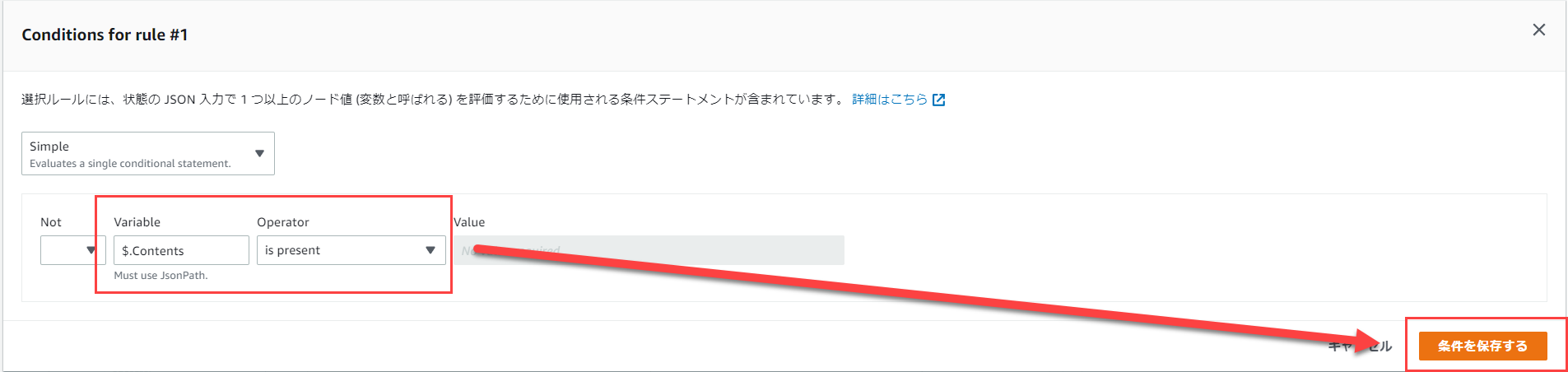
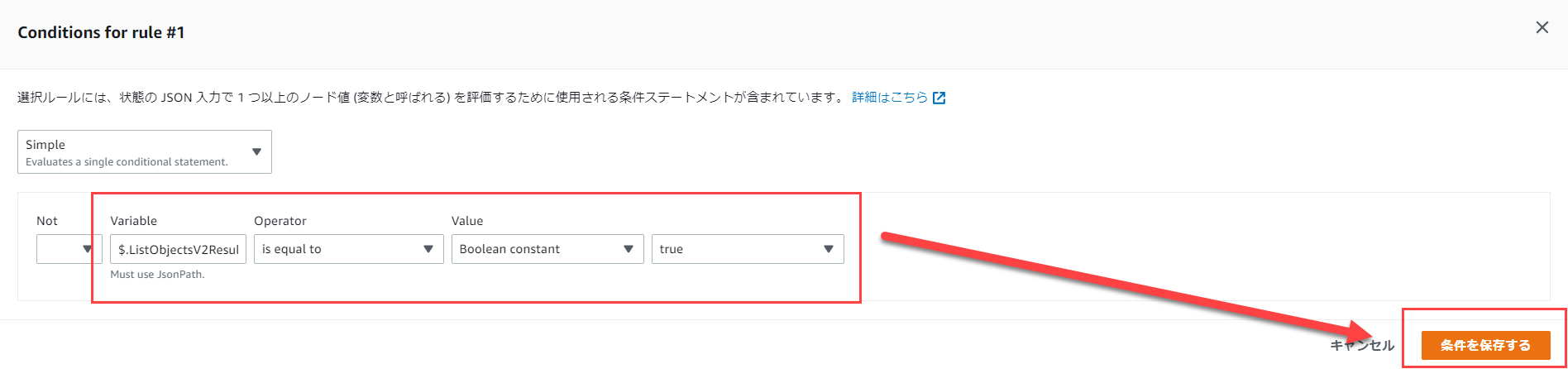
Choiseを選択し、Choise Rules内のRule #1の「Add conditions」をクリックします。
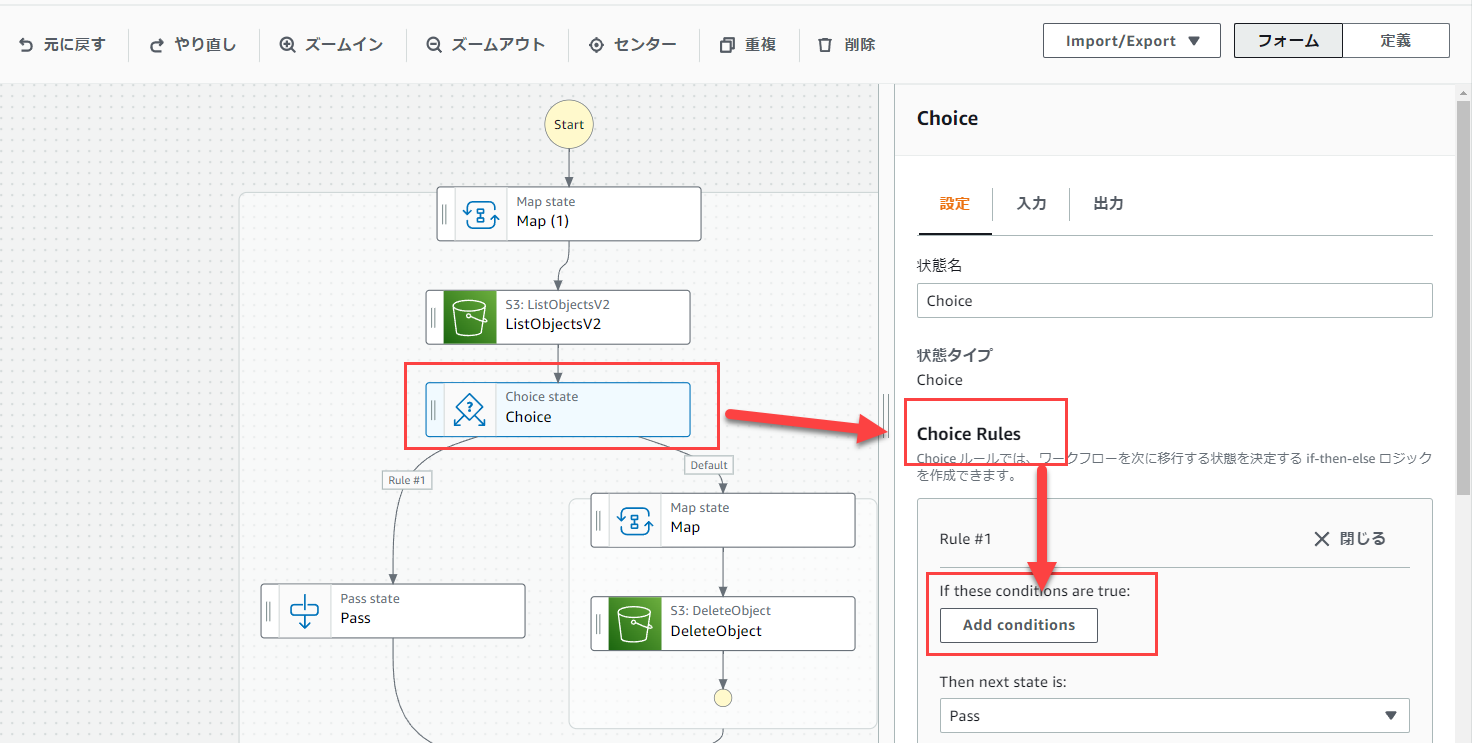
以下の画像のように修正して、「条件を保存する」をクリックします。
これで、「Conditionsが存在すれば」という条件になります。
次に、「Then next state is:」の部分を「Map」に変えます。
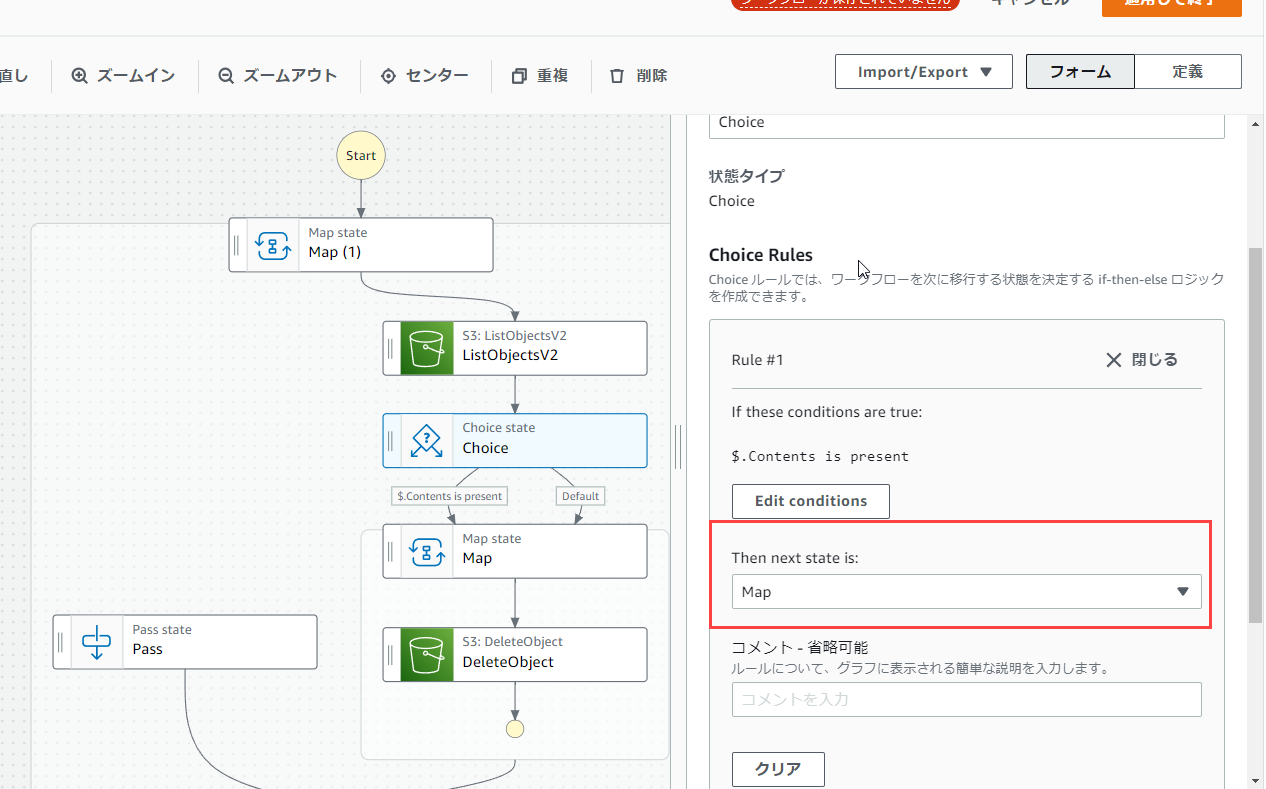
次に、「Default rule」の「default state」をPassに変えます。
するとChoiseの分岐が以下の画像のようになると思います。
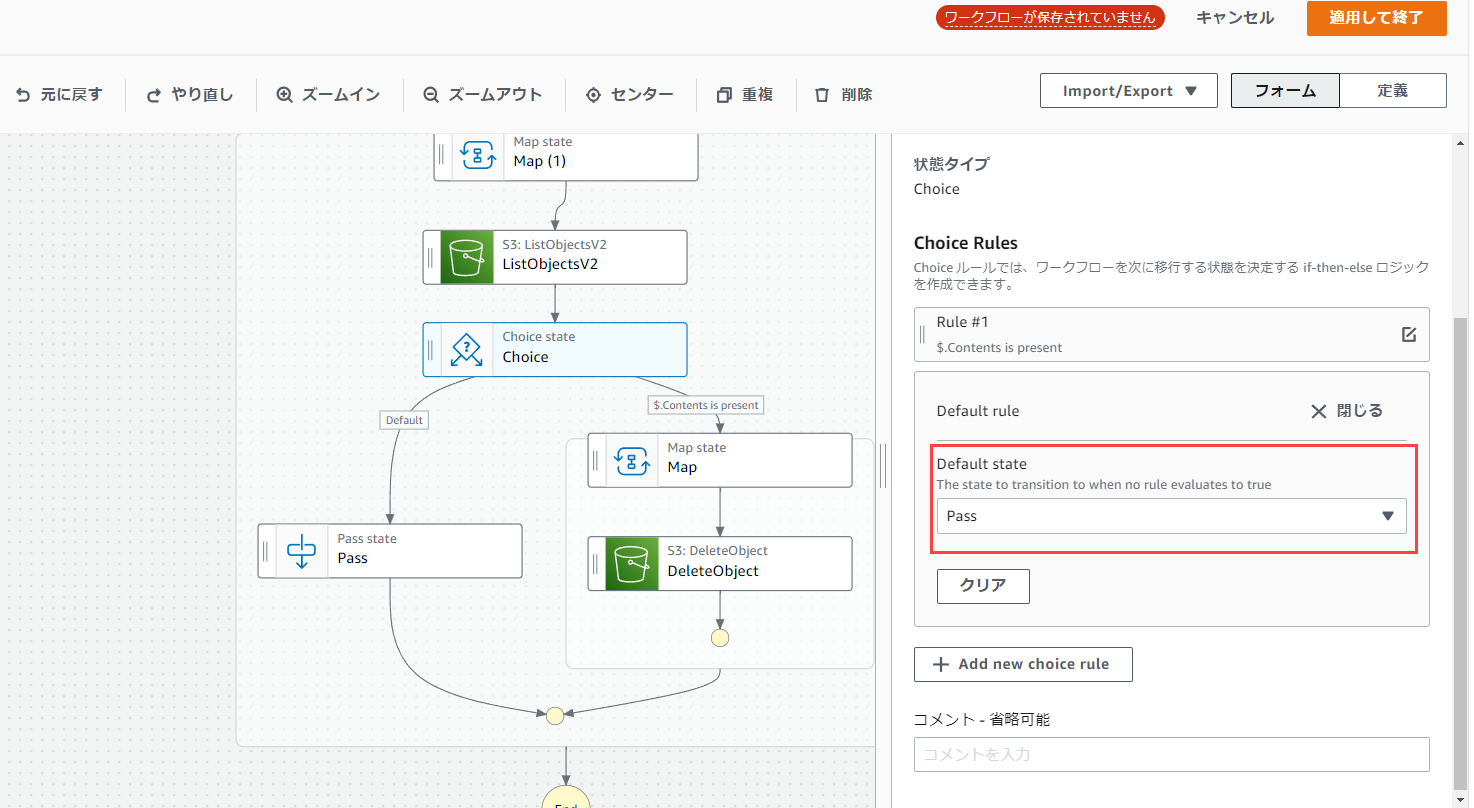
この状態で再度保存して実行してみてください。
グラフインスペクターが以下のようになっていればOKです。
今回はバケット内のオブジェクトが1つもない状態で実行したので、ただしくChoiseで分岐されていることが分かります。

ループ処理を追加する
これまでの手順でバケットの中身を空にできそうですよね?
実はまだ足りません。
ListObjectsV2のリファレンスを見ると以下の文章があります。
ListObjectsV2
Returns some or all (up to 1,000) of the objects in a bucket with each request.
要するに、一回のリクエストで上限1000件までしか返らないよ、ということです。
つまり、現状の構成だとバケット内に1000個以上のオブジェクトが存在すると、正しくバケットを空にできない、ということになります。
どうするかというと、ListObjectsV2のレスポンス内容にIsTruncatedという属性値がありました。
IsTruncatedがtrueの場合、レスポンスに全件含まれていないという意味になるので、この値で条件分岐すればよさそうです。
まず、ListObjectsV2の出力の「ResultPath を使用して元の入力を出力に追加」にチェックを入れて、「Combine original input with result」を選択、値は「$.ListObjectsV2Result」と入力します。
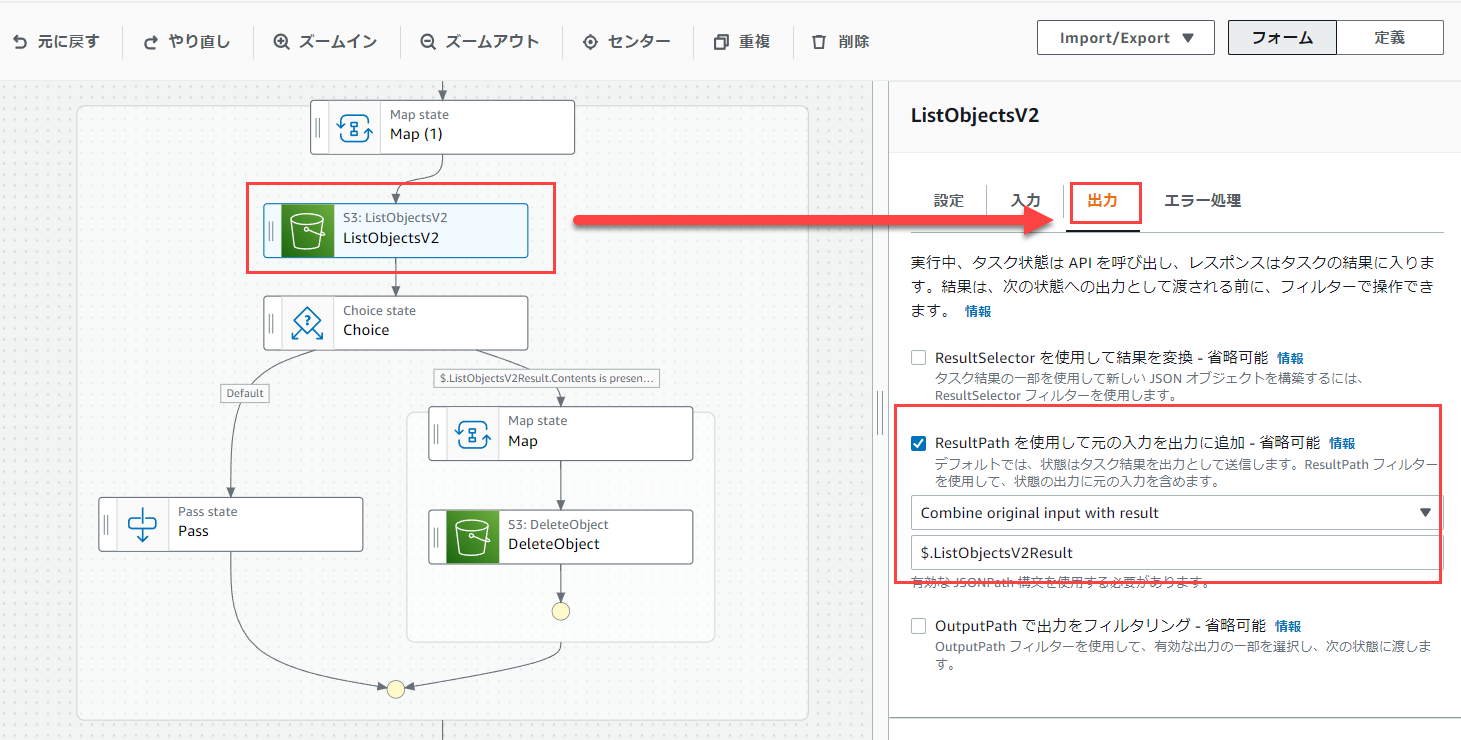
この設定はinputの内容とステートの実行結果を合わせて次のステートに渡す必要がある際に利用します。
今回のステートの実行結果はListObjectsV2Result以下に格納されます。
実際のoutputは以下のようになります。
inputのbucketNameと実行結果がListObjectsV2Result以下に入った状態になっているのがわかると思います。
{
"name": "ListObjectsV2",
"output": {
"bucketName": "step-functions-sample-1",
"ListObjectsV2Result": {
"Contents": [
{
"ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
"Key": "1-1.txt",
"LastModified": "2022-04-17T16:22:02Z",
"Size": 0,
"StorageClass": "STANDARD"
}
],
"IsTruncated": false,
"KeyCount": 6,
"MaxKeys": 1000,
"Name": "step-functions-sample-1",
"Prefix": ""
}
},
"outputDetails": {
"truncated": false
}
}
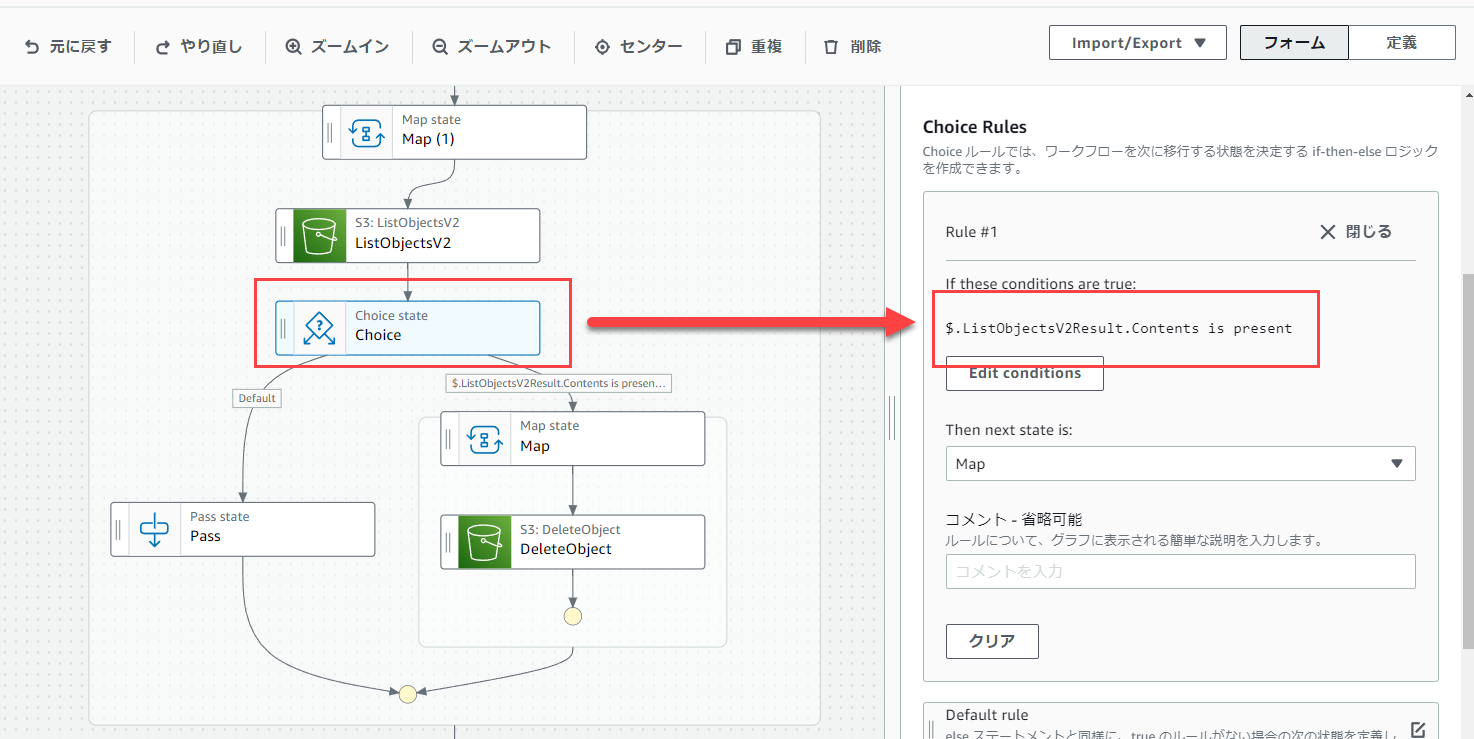
次にChoiseのRule #1を以下の画像のように修正します。
inputの値の構造が変わっているので、参照する値も変わるからです。
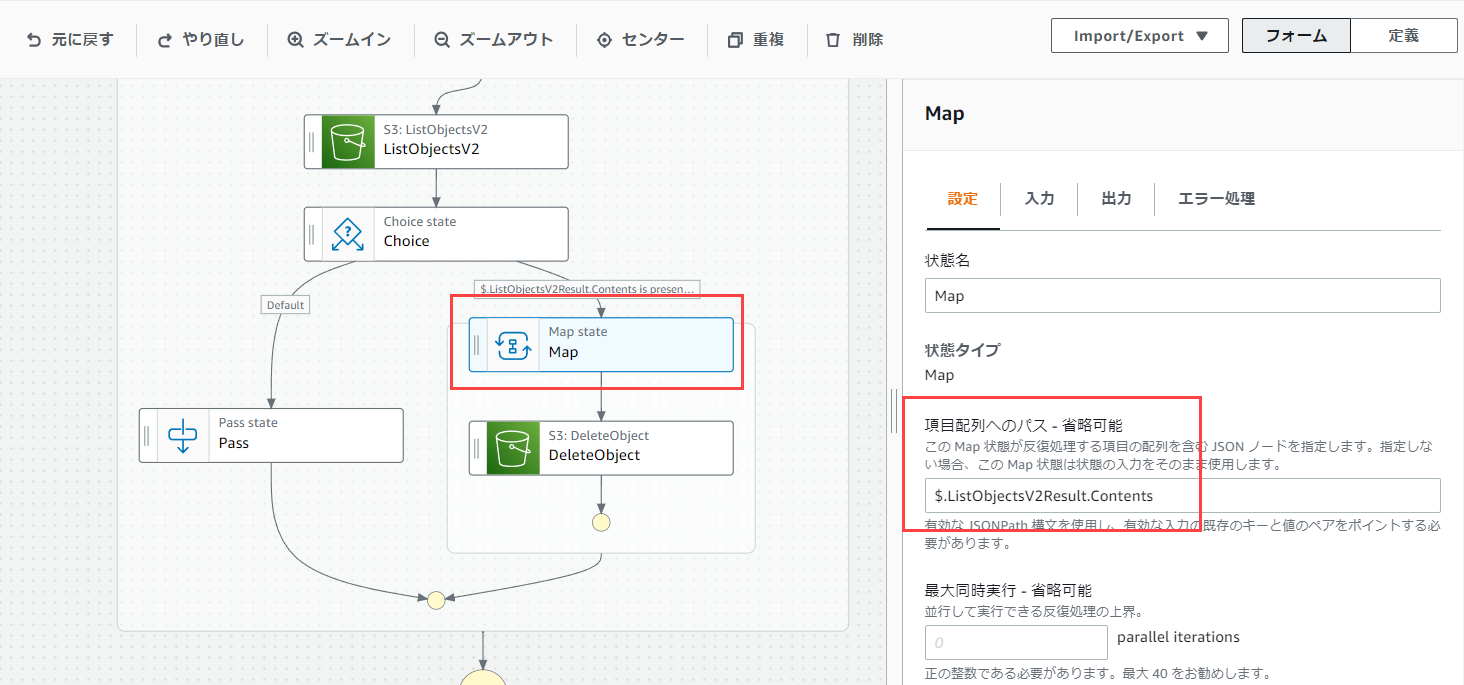
次にMapの項目配列へのパスを修正します。
inputの構造が変わったので修正が必要です。
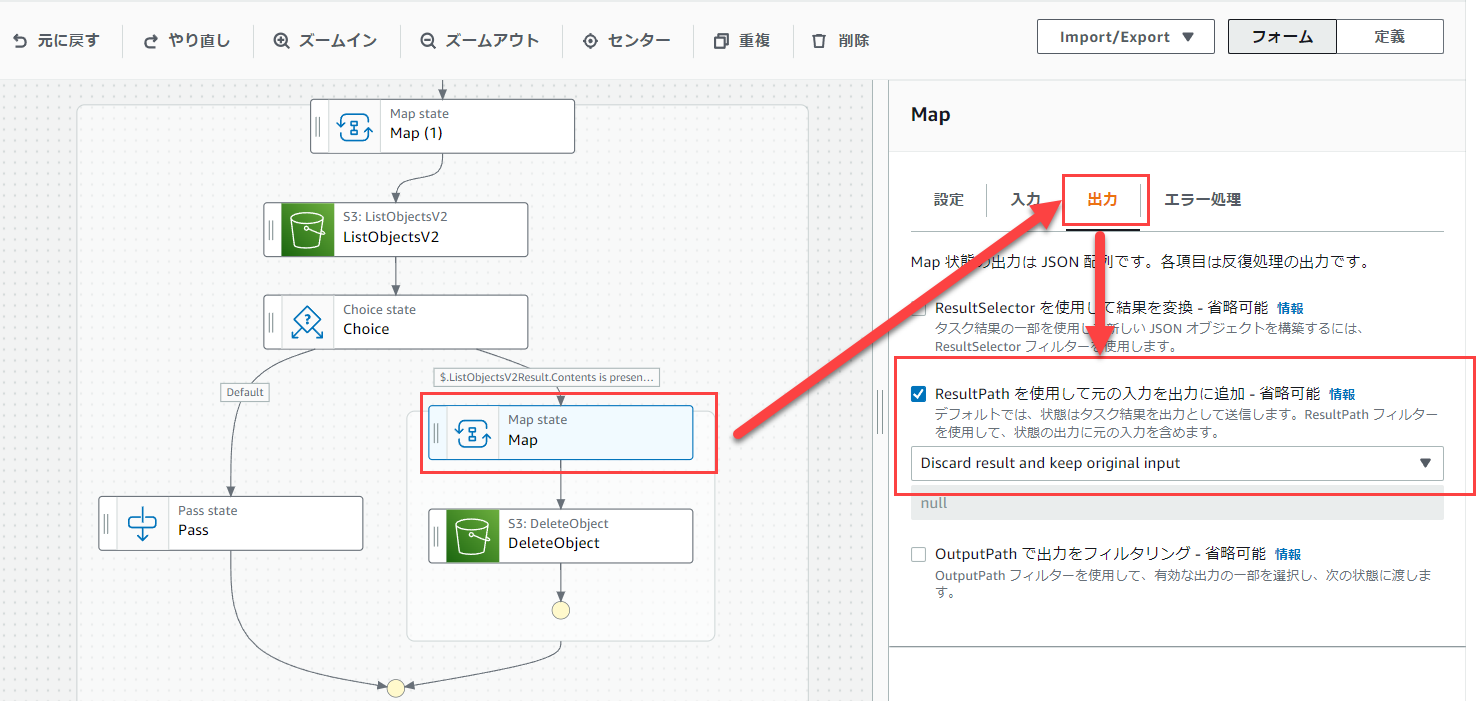
また、出力の「ResultPath を使用して元の入力を出力に追加」にチェックを入れて、「Discard result and keep original input」を選択します。
今回はタスクの実行結果は次に渡す必要がないので、「Discard result and keep original input」を選択しています。
次にChoiseをMapの下に差し込みます。
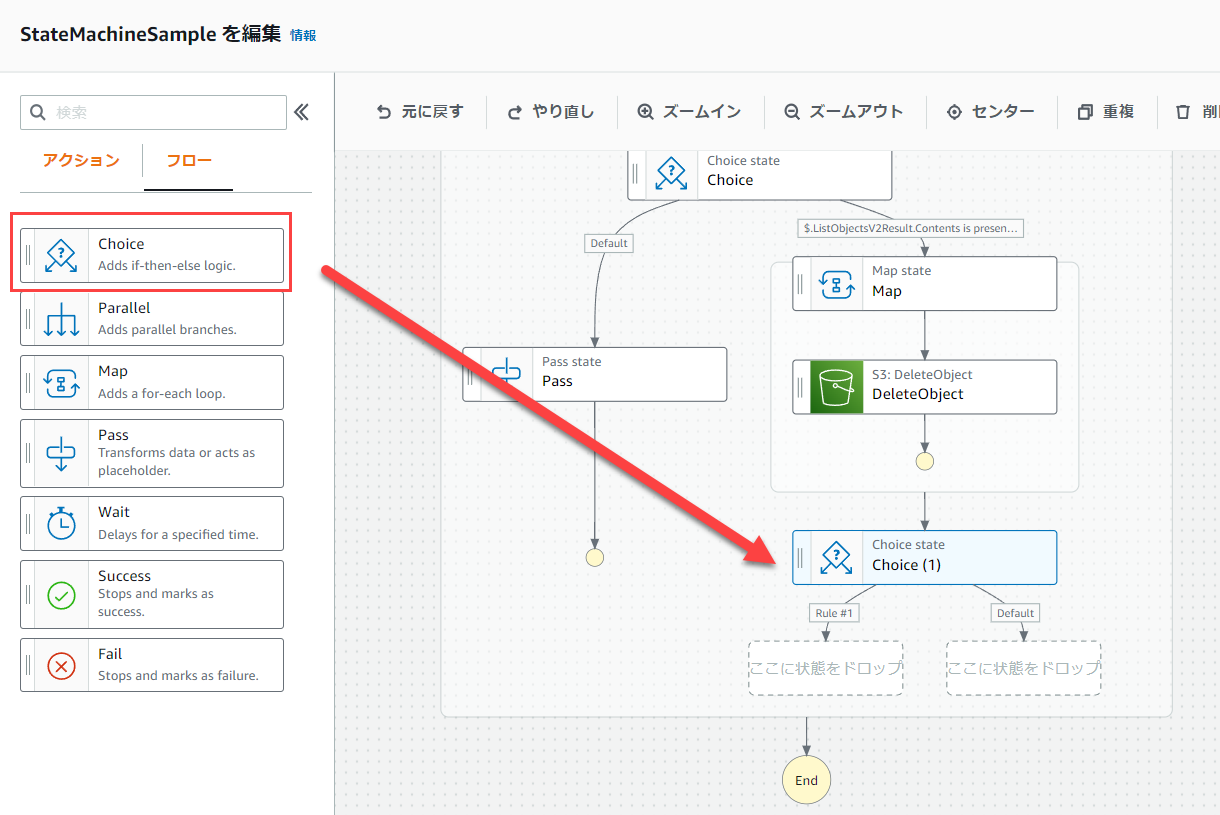
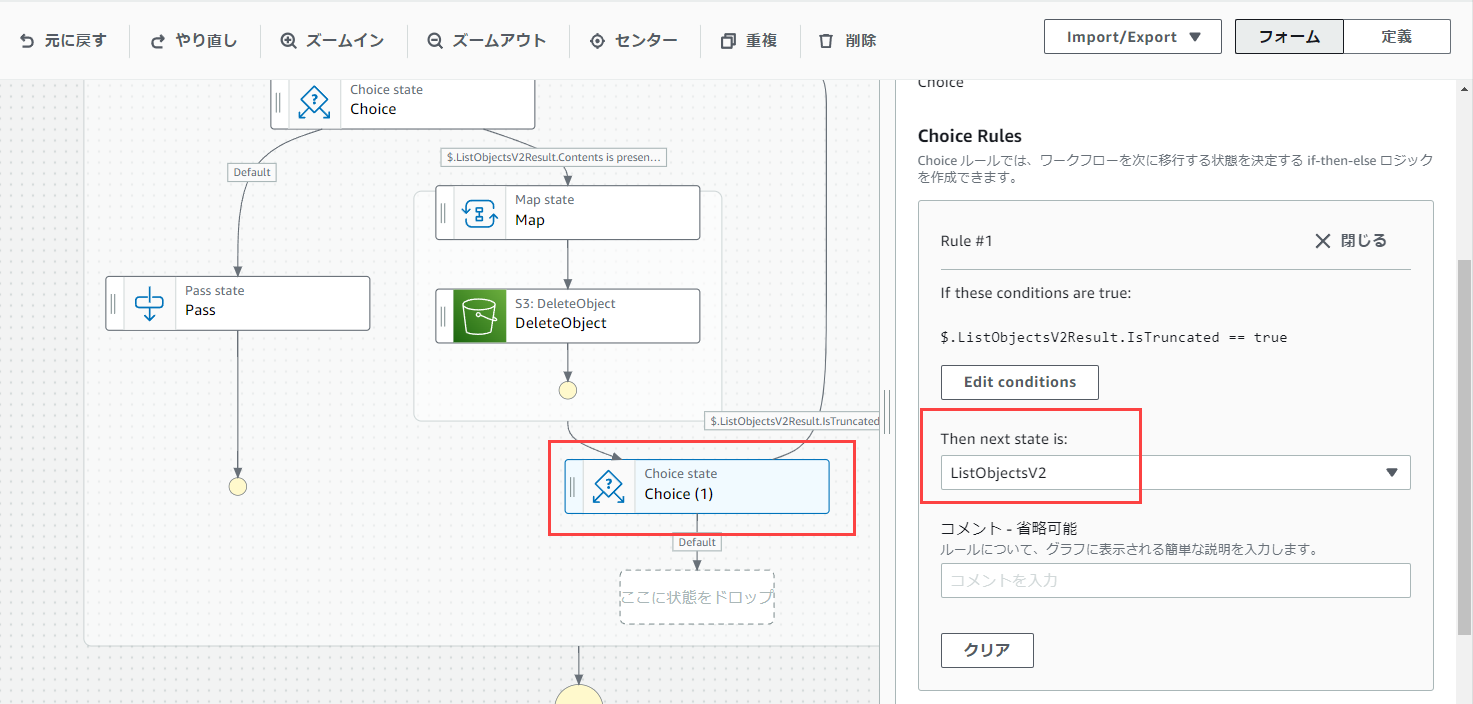
Choise(1)のRule #1の条件を以下のようにします。
Variable: $.ListObjectsV2Result.IsTruncated
Rule #1の次のステートはListObjectsV2とします。
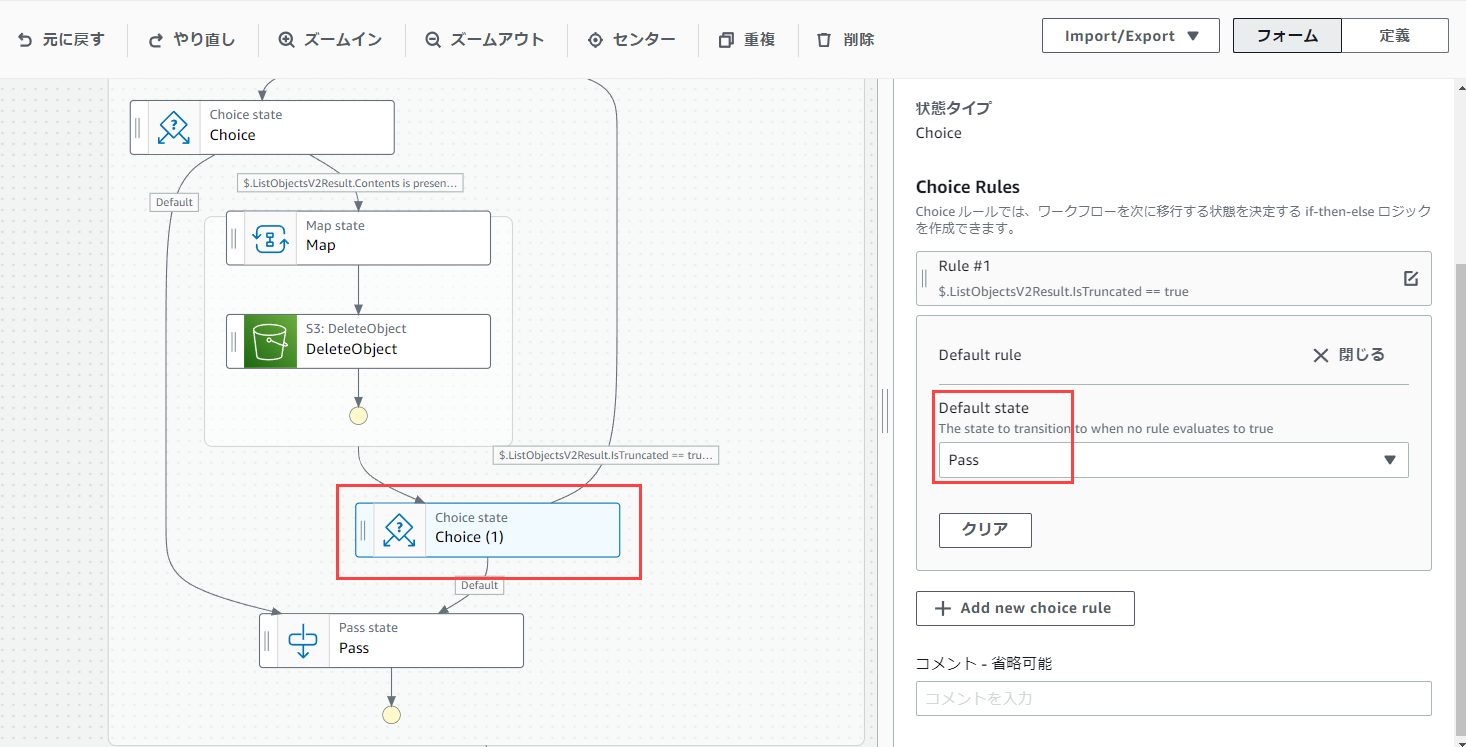
Default stateはPassとします。
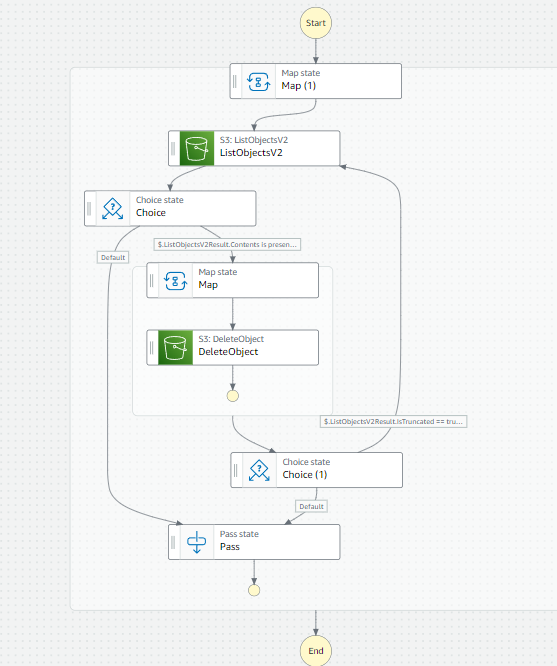
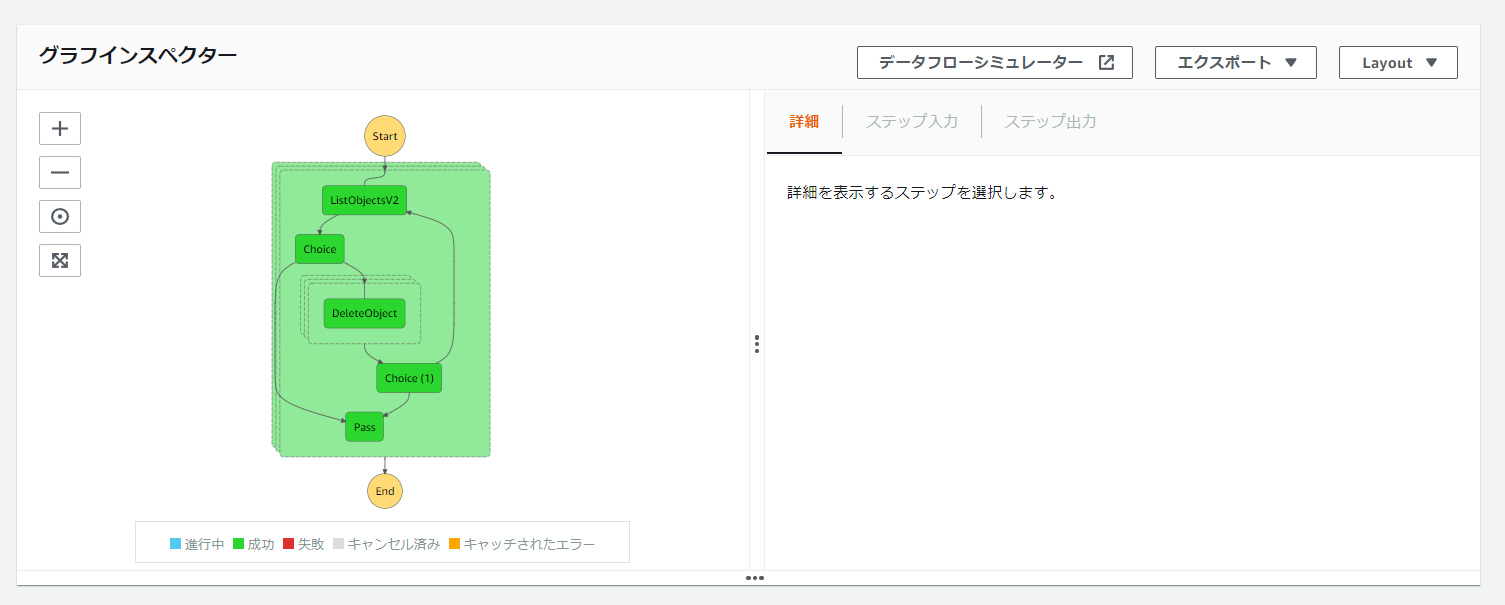
最終的には以下のようになります。
これで保存して実行してみてください。
グラフインスペクターが以下のようになっていればOKです。
最後に
バケットを空にする実装はLambdaで実装すればステートマシンを作るよりももっと簡単に実現できると思います。
実際にStep Functionsが生きてくるのはLambdaでは対応が難しいような処理の待ち時間が発生するようなユースケースや複数のLambdaの状態管理が必要になる場合だと思います。
ユースケース
ユースケース
ただ、今回の記事を通してざっくりとでもStep Functionsの使い方、魅力が伝わればいいなと思います。