はじめに
最近Pythonのコードを書く機会が増えてきていて、Pythonで綺麗なコードを書くためには、というのを考える機会がありました。
折角の機会なので自分なりに整理した内容をまとめてみました。
プログラミング言語自体はPythonですが、考え方自体は他の言語でも利用できる内容になっていると思いますので、ぜひ参考にして頂ければと思います。
綺麗なコードとは
そもそも、綺麗なコードとはどのようなコードのことでしょうか。
理解しやすいコード、テストしやすいコードなど、いろいろな定義ができるかと思います。
今回の記事では、理解しやすいコードを綺麗なコードの主要な考え方としてとらえて記事を書いています。
TIPS1: 三項演算子を利用しよう
例えば以下のようなコードを見てみましょう。
import os
STAGE = os.environ.get("STAGE")
if STAGE is None:
LOGGER_TYPE = "INFO"
else:
LOGGER_TYPE = "DEBUG"
こういったパターンはよくあると思います。
ある条件で変数の初期化時に代入する値を切り替えるパターンですね。
このコード自体に問題があるわけではないのですが、以下のようにした場合はどうでしょうか。
import os
STAGE = os.environ.get("STAGE")
LOGGER_TYPE = "INFO" if STAGE is None else "DEBUG"
いやいや、なんも変わってないやん、単に行数が減っただけじゃないか、と思われるかと思います。
しかし、この行数が減ったというのは案外重要なのです。
そもそも私たちがコードを読む時には、どのようにして理解していくでしょうか。
1行1行順番に読んでいくのではないでしょうか?
今回の処理を簡単な図で表現してみると以下のようになるかと思います。
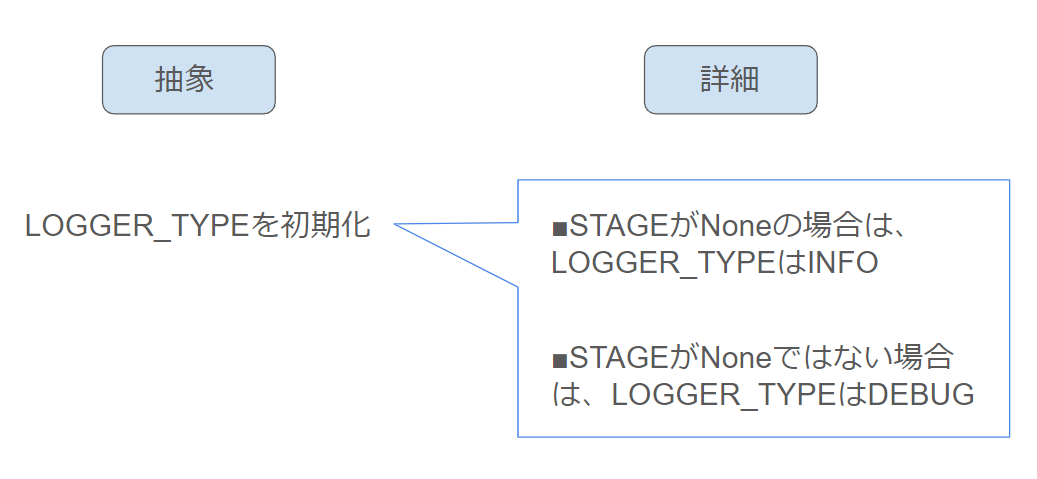
やっていることは、「LOGGER_TYPEという変数の初期化」です。
コード例1のコードでは「LOGGER_TYPEという変数の初期化」を理解するために4行のコードを読む必要があります。
しかし、コード例2では、1行を読むだけで「LOGGER_TYPEという変数の初期化」の意図をくみ取ることができます。
もし、どのような条件で初期化されているのかを知りたいのであれば、代入部分を詳しく見ればいいのです。
つまり、コード例2の場合は、コードの意図をくみ取るためのショートカットができる、ということです。
変数初期化の際に条件分岐するようなケースでは、三項演算子をうまく使うことで、理解しやすいコードをを書くことができると思いますので、ぜひ真似してみてくださいね。
関数に切り出すタイミング
今回の考え方では、処理を関数に切り出すタイミングとも関係がある考え方だと思います。
例えば、以下のようなコードを考えてみます。
def main():
connection = pymysql.connect(
host='localhost',
user='user',
password='passwd',
database='db',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor,
)
with connection:
with connection.cursor() as cursor:
sql = "SELECT * FROM users"
cursor.execute(sql)
user_list = cursor.fetchone()
base_mail_text = "{user_name}様 こんにちは"
for user in user_list:
send_mail(user["mail"], base_mail_text.format(user_name=user["user_name"]))
connection.close()
上記はサンプルコードなので動作するかは怪しいのでご了承ください。
行数は多いですが、やっていることは以下の2つです。
- DBからユーザの一覧を取得
- 取得したユーザ全員にメールを送信する
では、以下のコードはどうでしょうか。
def main():
all_user_list = get_all_user_list()
base_mail_text = "{user_name}様 こんにちは"
send_mail(all_user_list, base_mail_text)
恐らくですが、コードを見ただけで短時間で何をしているコードなのか理解できると思います。
現実世界のコードはもっといろいろな制約などがあってこんなに簡単な話ではないのですが、考え方の基本的な部分はこのような感じだと思います。
処理を関数化することで、コードが理解しやすくなる、という点についてなんとなくイメージ頂ければと思います。
※むやみやたらに関数化すべきという主張ではありません。関数化するメリットとしてコードの重複を排除する、テストしやすくする、といった点も考慮して関数化を検討すべきです。
TIPS2: セイウチ演算子を利用しよう
セイウチ演算子はPython 3.8以降に利用できる演算子なので注意ください。
例えば、以下のようなコードを考えます。
number_list = [1, 2, 3]
if len(number_list) > 2:
print(f"サイズは{len(number_list)}です")
len(number_list)を2回呼んでいるのがいけてないですね。
これを回避するためには、len(number_list)を変数に代入する必要があるのですが、IF文の外で定義すると、今回のIF以外でも利用できるように見えるため、それも避けたいです。
そんな時に利用できるのがセイウチ演算子です。
number_list = [1, 2, 3]
if (number_list_size := len(number_list)) > 2:
print(f"サイズは{number_list_size}です")
IF文の中で、変数に代入することができます。
このように書くと、number_list_sizeという変数は、このIF文でのみ利用するといった意図が明確になります。
※ただし、Pythonの変数スコープの仕様で、number_list_sizeはIF文の外でも利用可能です。。。。
ここでいいたいのは、処理の重複はできるだけ排除しましょう、ということです。
同じ関数を同じ形で2回呼び出した際に、常に一つにまとめられないか?というのを考えるよう癖づけるといいのではないかと思います。
TIPS3: リスト内方表記を利用しよう
例えば、以下の例を考えてみます。
辞書の配列から、名前を抜き出した配列を作りたい、というユースケースですね。
user_list = [{"name": "taro", "age": 12}, {"name": "jiro", "age": 9}]
user_name_list = []
for user in user_list:
user_name_list.append(user["name"])
リスト内用法記法を使うと以下のように書けます。
user_list = [{"name": "taro", "age": 12}, {"name": "jiro", "age": 9}]
user_name_list = [user["name"] for user in user_list]
これも、user_name_listの初期化、という意図がより明確にわかるようなコードになっているのではないかと思います。
リスト内方表記は通常のfor文よりも高速で動作するため、こういったユースケースではリスト内容表記の方がメリットがあります。
高階関数について
さて、リスト内方表記について記載すると、高階関数の利用はどうなの?という指摘がありそうです。
高階関数の詳細な説明は省略しますが、いわゆるmapやreduceのことです。
以下のコードもリスト内方表記と同じ出力結果になります。
user_list = [{"name": "taro", "age": 12}, {"name": "jiro", "age": 9}]
user_name_list = list(map(lambda x: x["name"], user_list))
Pythonに限って言えば、リスト内方表記の登場で高階関数の利用はほぼなくなりました。
リスト内方記法でIF文の条件も書けるため、まずはリスト内方記法で検討して、どうしても対応ができない場合のみ、高階関数を使う、という方針で良いと思います。
TIPS4: matchを利用しよう
matchはPython 3.10から利用可能になった機能です。
いわゆるCASE文です。
例えば、以下のようなコードを見てみましょう。
import os
STAGE = os.environ.get("STAGE") # prod, dev, local
if STAGE == "prod":
print("本番環境です")
elif STAGE == "dev" or STAGE == "local":
print("開発環境です")
else:
print(f"それ以外です: {STAGE}")
このコード自体特に問題はないのですが、以下のようにも書けます。
import os
STAGE = os.environ.get("STAGE") # prod, dev, local
match STAGE:
case "prod":
print("本番環境です")
case "dev" | "local":
print("開発環境です")
case _:
print(f"それ以外です: {STAGE}")
今回のSTAGEのようにenumで表現できるような変数(prod,devなどパターンが決まっているような変数)を基準に分岐するような場合、IF文で分岐するよりも、match文で記載した方がコードの見通しはよくなるのではないかなと思います。
最後に
細かい話をすればもっといろいろなTIPSがあるのですが、Pythonの新しめの機能を使ってコードをリファクタリングするんだったら、という感じで思いついたものを上げてみました。
少しでも参考になれば幸いです。