はじめに
はんなりPythonアドベントカレンダーの11日目の記事です。
私自身Pandasは本当に初心者なので、以前から気になっていたマルチインデックスについて簡単ですがまとめました。
※本記事では原則下記コードは省略しますが、記述されている前提で進めます。
import pandas as pd
そもそもマルチインデックスとは
行ラベル、列ラベルを階層的に持つことができる仕組みです。
文字での説明がややこしいので、実際に例を見てみましょう。
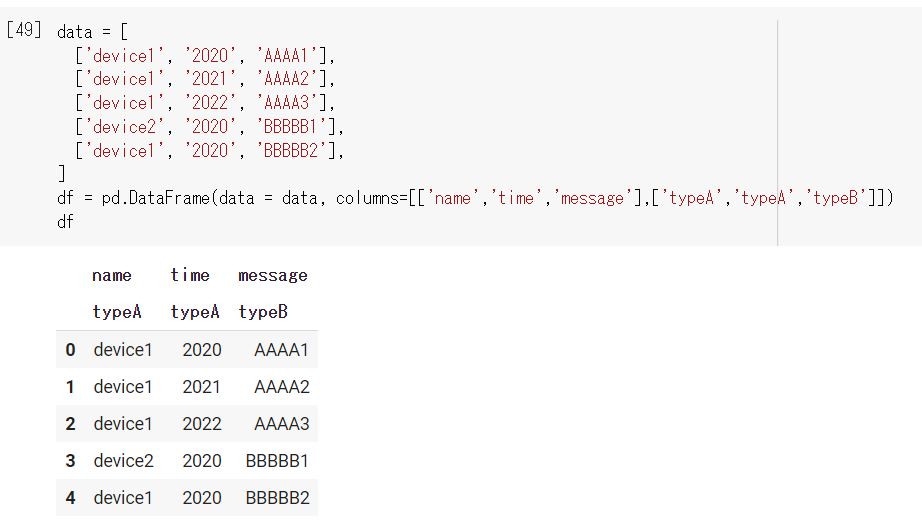
上の図の場合、列ラベルが2層になっています。1列目にはnameとtypeAというラベルが付与されており、2列目にはtimeとtypeAというラベルが付与されています。
マルチインデックスの扱い(列ラベルがマルチの場合)
では、実際にデータを取得する場合を見てみましょう。
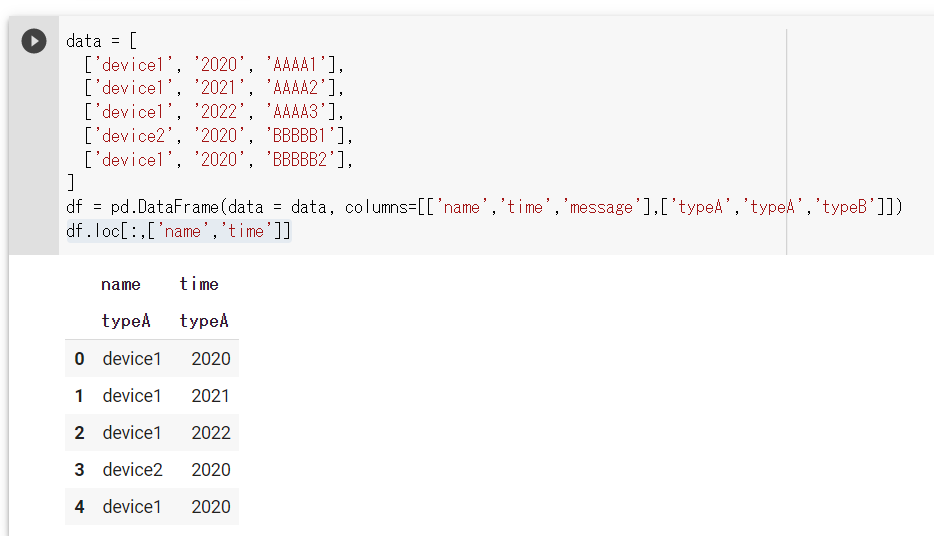
上の例では、nameとtimeのみの列を抜き出しています。
ちなみに、普通のインデックスの場合も同じ方法で列を抜き出すことができます。(下図参照)
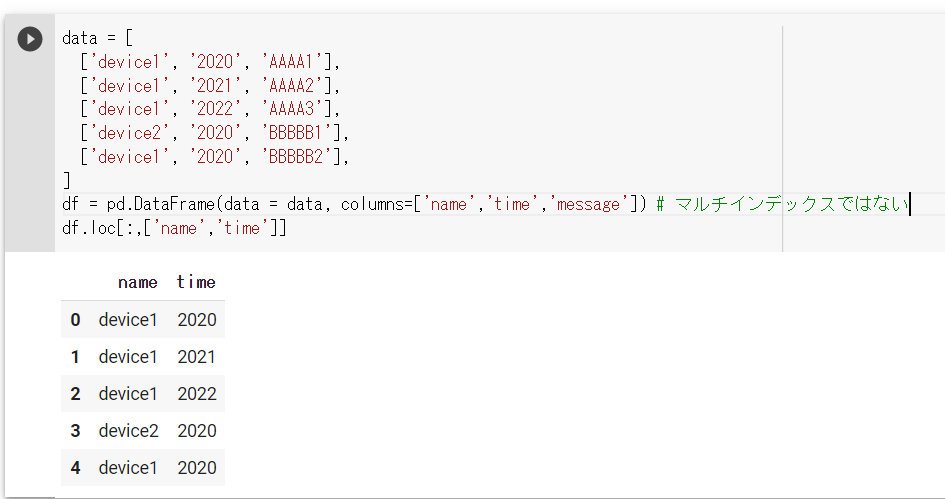
つまり、外側のラベルについては、通常の列ラベルと同じ方法で参照できる、ということです。
では、次に内側のラベルで絞り込みを実施してみましょう。
その際は、IndexSliceを使います。
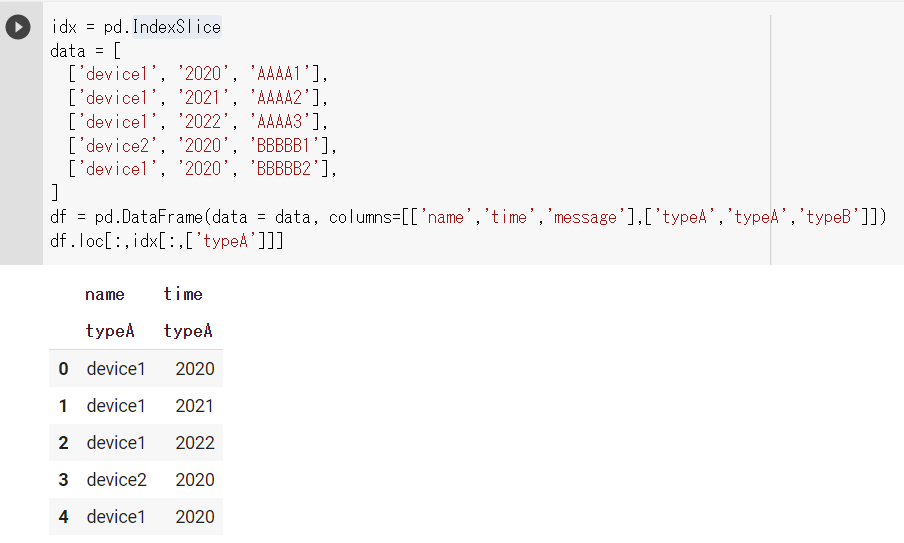
上図では、typeAで絞り込んだ結果です。typeAにはnameとtimeが含まれるので、typeAで絞るだけで、2列のデータを取得することができます。
マルチインデックスを利用すると、グループ化できるので、一つのラベルで複数の列を絞り込むことが可能になります。
ちなみに、もしnameとtypeAの両方を選択する場合は以下になります(本当はこんなことはしませんが)
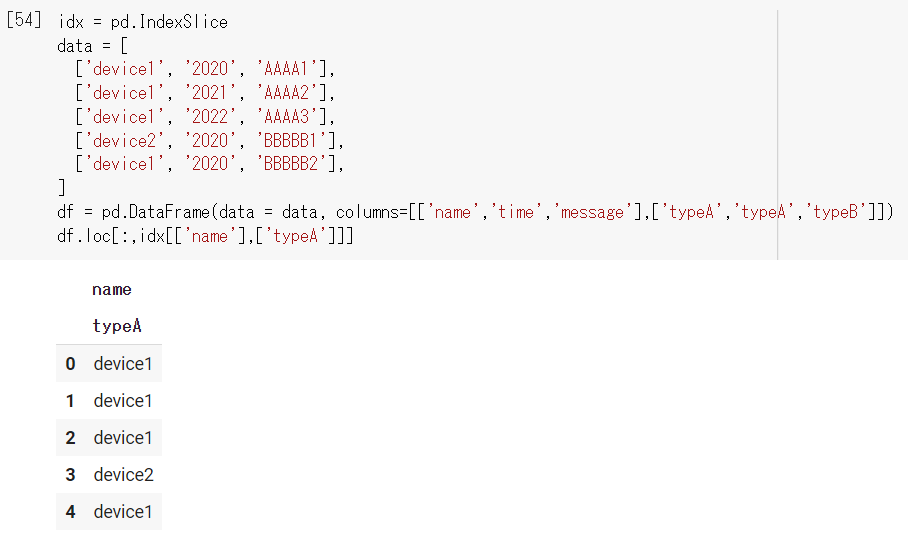
IndexSliceの記述では、外側のラベルから順番に記述します。
マルチインデックスの扱い(行ラベルがマルチの場合)
次は、行ラベルをマルチにしてみましょう。
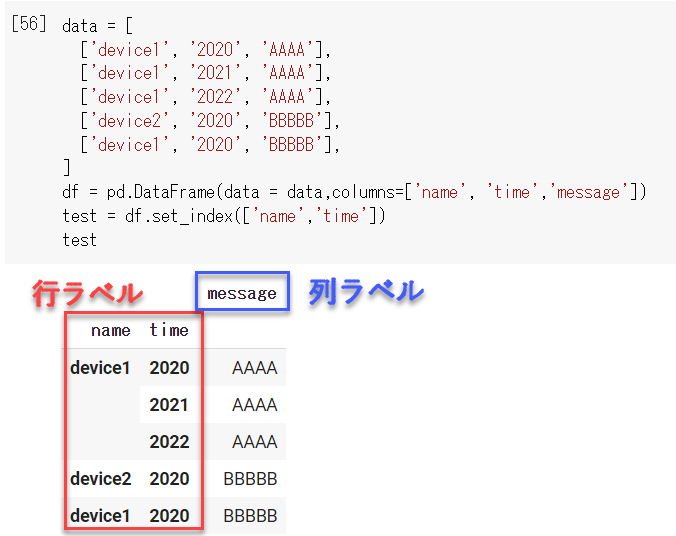
かなりややこしいのですが、まず最初にnameとtime、messageを列ラベルとして設定しています。
次に、test = df.set_index(['name','time'])の部分でnameとtimeをインデックスとしてセットしているので、nameとtimeは列ラベルではなく行ラベルとしてのマルチインデックスになります。(下図参照)

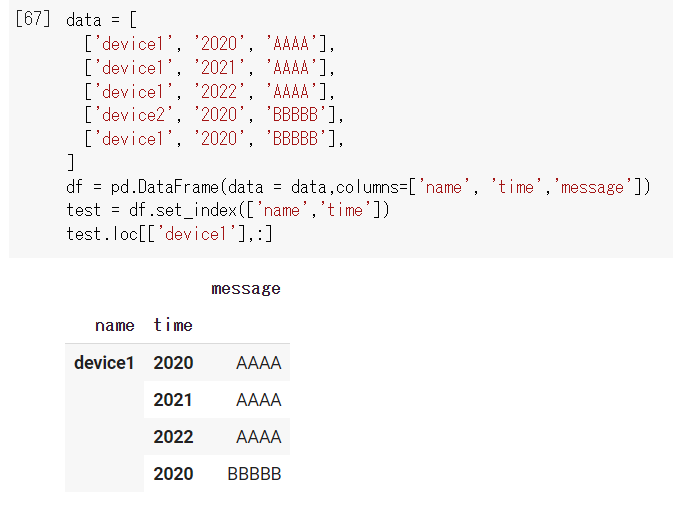
では、device1のデータだけを抜き出してみましょう。
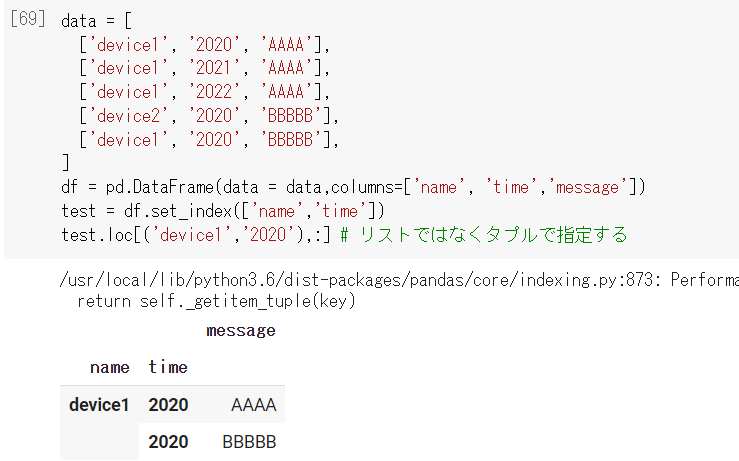
ちなみに、device1と2020で絞り込む場合は以下になります。
locの中身を配列ではなくタプルで指定することで絞り込みが可能です。
最後に
マルチインデックスる利用することで、列や行をグループ化することができ、より分かりやすいデータ処理をすることができるようになります。
最初見たときは私も全然わかりませんでしたが、この記事が少しでも理解の助けになれば幸いです。
では(^▽^)