概要
- VRCのアバターのイラストが欲しいですね!LoRAにしましょう
- 自分用の作業メモ感が強いですが一応汎用で使えるはず
環境セットアップ
- Stable Diffusion Web UIのインストール (方法は割愛)
- kohya-ssのインストール
- 自作LoRAの作り方|LoRAをKohya_ssで学習する方法のとおりにやる
- インストール先はD:\LoRA\kohya_ssにした(好みでいいが、今後それを前提で説明)
- kohya_ssのwebuiが開けばOK
SSの撮影
-
LoRAImgMakerを使う。プロジェクトをコピーし、これをインポート、ポチポチすると顔とポーズのSSが取れる
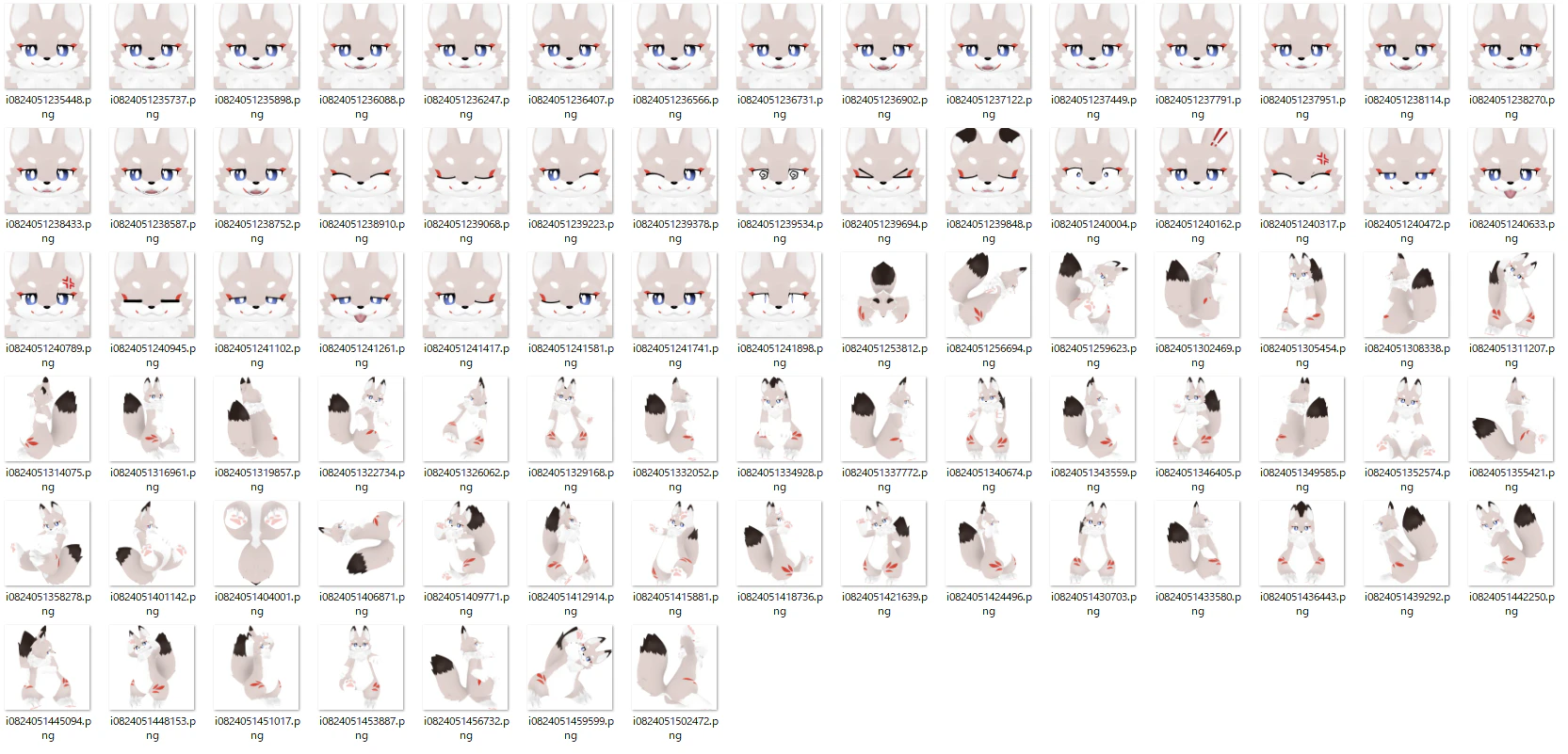
-
ほぼ変わらない口の形・あまり重要でなく、他の組み合わせで表現できる表情・意味不明なポーズがあればここの段階で削除しておく

-
顔いらないかもしれない(よくわからない)
SDの起動・Taggerの準備
- Taggerを導入してSDを再起動
タグ付け
初回
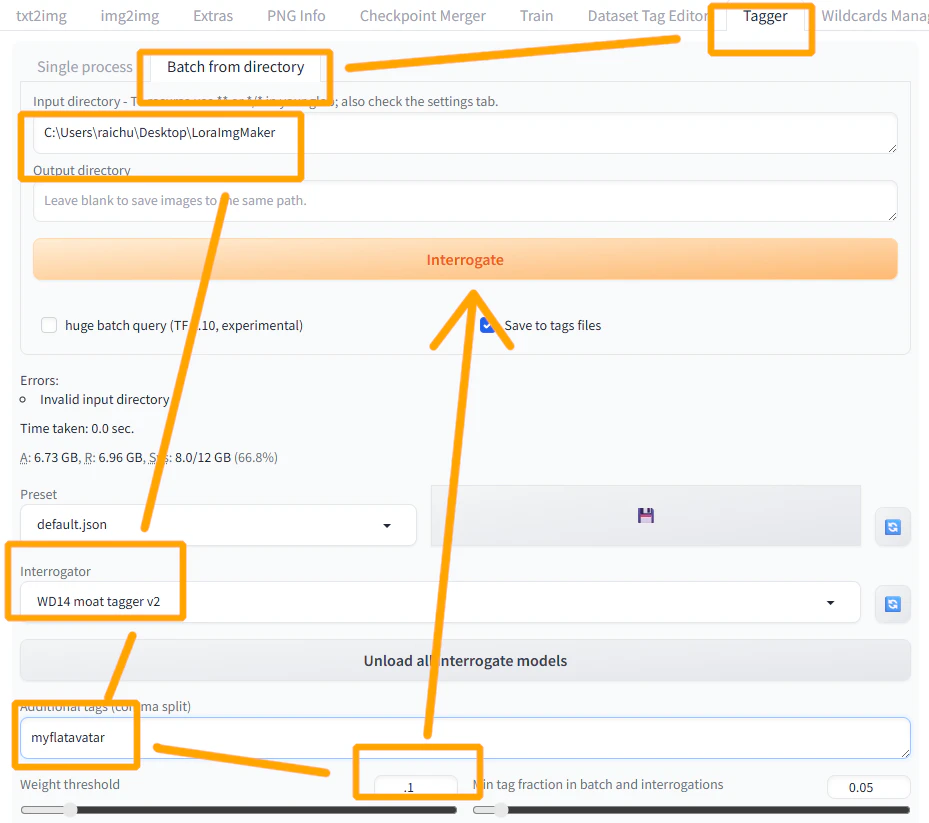
- InputDirectoryに画像のあるフォルダ(デスクトップ/LoRAImgMaker)を設定
- Outputは指定しないほうがよい
- 改めてSDを起動し、Interrogateを適当に設定
- Additional tagsに最終的に生成時使いたいキーワードを入れる
- 区切り(スペース、アンダーバー)がないほうがいいかもしれない?
- Weight thresholdを好みで変えて(0.1前後くらい?)「Interrogate」を押す
- Weightを変えるとタグの数が変わる、ポーズとか表情が正しく言葉で表現されればOK
- 2回目以降はさくさく処理できるので悩まずにやってみるが吉
ざっと出てくる

タグの訂正 (やると精度があがるが、とりあえずお試しなら飛ばしてもOK)
- 目的:次のタグを削除する
- 明らかに間違っているもの(例:eevee)
- 作成したいLoRAに絶対欠けてはいけない要素(例:kemono)
- 逆に言うと、次のようなタグは残す
- 変数にしたいもの(生成時、バリエーションを持たせたいもの)
- 表情
- 姿勢
- 背景
- portraitは絶対残してください!(表情を区別するため)
- 変数にしたいもの(生成時、バリエーションを持たせたいもの)
- 具体的な手順
-
出てきたタグを機械翻訳(読めればそのまま)して「いらないもの」のリストを作る
-
たとえばAI翻訳してスプシでやる


-
いらないものリストをTaggerの下のほうにあるExclude tagに書く

-
再度Interrogate。減ってればOK
-

今回消したもの (アバターによって異なります!)「明らかに正しいもの」「明らかに違う物」が対称
white fur,blue eyes,bright pupils,animal nose,animal ears,furry,body fur,white pupils,furry female,two-tone fur,1girl,:3,collarbone,dog ears,bangs,pokemon (creature),fluffy,fur collar,flat chest,white hair,makeup,short hair,animal focus,fox ears,no humans,sidelocks,animal ear fluff,dog girl,nude,fox girl,animal hands,1boy,brown background,gradient,eyeshadow,gradient background,lipstick,monochrome,tail,animal,tattoo,pawpads,claws,fox,red eyeliner,male focus,thighs,facial mark,thick eyebrows,artist name,feathers,head out of frame,wings,breasts,feathered wings,red eyes,pussy,navel,large breasts,thick thighs,fox tail,animal feet,eyeliner,red eyeshadow,fang,completely nude,signature,toes,grey fur,teeth,fangs,dog,:d,snout,light blush
- なんかpokemon(creature)がきえない・・
- タグはその画像を説明するもの
- LoRA学習において「(学習する/一般的な)他の画像とどう違うか?」を認識するために使用される
- 一般的な他の画像とどう違うか?観点において
- 学習のため沢山の画像を用意して、AdditionalTag「rw3」を付与した
- これはrw3はこのキャラ画像です、と伝えるためのもの
- そのキャラにpawがあることが当たり前で欠かせないのなら、それはrw3の中に入るべき情報ですから、タグからは消すべき
- Taggerが自動付与したあやっているタグ(eevee)を消した
- 他と比べて誤った勉強をする事故を減らすため
- 学習する他の画像とどう違うか?という観点において:
- 立っている画像と座っている画像を用意したならそれぞれの画像がどう違うかAIに教えるべき。だから姿勢(sitting, standing)は重要
- 全体的な理論として
- 全部の画像の共通なタグが1つ、それぞれの画像について全て異なる意味のあるタグが付与されている、という状態にするとAIにとっては一番よい学習材料なのかも(理想論)
- 共通タグに対してバリエーションは多いほど汎用的なものができるので色々な背景や服・シェーダーの元画像があったほういい、いやそれをやると時間かかるし失敗しやすい、等色々な意見がある(最初は気にしなくていい)
- 終わったら自動で(画像と同じフォルダにたくさんのテキストが)保存されているのでSDはいったん閉じる
LoRA学習
-
GUIは面倒なのでコマンドでやっていきます
- GUIでやる場合はここのjsonをつかうといい
-
D:/LoRARun/を作る
-
run.batを作る
- 基本的にはこれでいいです kohya_ssの場所が違う場合は適宜直してください
accelerate.EXE launch --dynamo_backend no --dynamo_mode default --mixed_precision bf16 --num_processes 1 --num_machines 1 --num_cpu_threads_per_process 2 D:/LoRA/kohya_ss/sd-scripts/sdxl_train_network.py --config_file D:/LoRARun/config.toml --optimizer_args weight_decay=0.01 d_coef=1 use_bias_correction=True safeguard_warmup=False betas=0.9,0.99
- config.tomlを作る
bucket_no_upscale = true
bucket_reso_steps = 256
cache_latents = true
cache_latents_to_disk = true
caption_extension = ".txt"
clip_skip = 2
dynamo_backend = "no"
enable_bucket = true
epoch = 50
full_bf16 = true
gradient_accumulation_steps = 1
gradient_checkpointing = true
huber_c = 0.1
huber_scale = 1
huber_schedule = "snr"
keep_tokens = 4
learning_rate = 1.0
loss_type = "l2"
lr_scheduler = "cosine"
lr_scheduler_args = []
lr_scheduler_num_cycles = 1
lr_scheduler_power = 1
max_bucket_reso = 2048
max_data_loader_n_workers = 0
max_grad_norm = 1
max_timestep = 1000
max_token_length = 75
max_train_epochs = 20
max_train_steps = 100
min_bucket_reso = 512
mixed_precision = "bf16"
network_alpha = 2
network_args = []
network_dim = 16
network_module = "networks.lora"
no_half_vae = true
noise_offset_type = "Original"
optimizer_args = []
optimizer_type = "Prodigy"
output_dir = "D:/LoRA/kohya_ss/output"
output_name = "myVrcAvatar"
pretrained_model_name_or_path = "D:/pinokio/api/automatic1111.git/app/models/Stable-diffusion/novaFurryXL_illustriousV7b.safetensors"
prior_loss_weight = 1
resolution = "1024,1024"
sample_sampler = "euler_a"
save_every_n_epochs = 10
save_model_as = "safetensors"
save_precision = "bf16"
seed = 0
shuffle_caption = true
train_batch_size = 1
train_data_dir = "D:/LoRA/kohya_ss/kohya_data/myVrcAvatar"
wandb_run_name = "myVrcAvatar"
xformers = true
-
モデルパスは学習したいモデルの実際のパスにして下さい
- 「\」だとエラーになります。「/」で指定して下さい
-
train_data_dirは「画像が入っているフォルダ」の親のフォルダを指定して下さい
- そのフォルダの 子フォルダの名前の最初は「1_」 にしてください
-
output_name,wandb_run_nameはTaggerで追加したタグと同じ名前がいいと思います(違っても問題はない)
-
max_train_epochsは何度学習するかという値で、20は画像60枚くらい想定です(ちょっと少なめです、本当は40くらいしたいかも)。それより多い/少ない場合比例して増減するといいかもしれません。学習時間と精度に直結します。著者のPC(RTX3060, VRAM 12GB)でこの設定で1時間かかります
-
画像を入れる場所はここです!
- D:\LoRA\kohya_ss\kohya_data\学習するアバターの名前\1_適当な名前\ここに画像
-
実行手順
- 画像・タグテキストを「train_data_dir」の子供のフォルダに移動
- Anaconda Promptを起動
- d:
- cd LoRARun
- conda activate kohya
- ./run.bat
学習完了!
- エラーがなければoutput_dor(D:\LoRA\kohya_ss\output)にLoRA(.safetensors)ができます!お疲れさまでした!
動作確認
- kohya_ssからSDのLoRAフォルダにデータを移動する
- 私の場合は D:\pinokio\api\automatic1111.git\app\models\Lora
- SDを起動する

- 学習に使ったのと同じモデルをセットする
- txt2imgでLoraタブを開き、更新ボタンを押す
- 学習したものが出てくるはずなので、クリックするとプロンプト欄に反映される
- 学習させたときのテキストファイルから適当に1つ選んで、<>のあとに中身をかく
- Generateすると、学習させた画像がそのままでてくる

もし画像生成初心者なら調べてみるといいかも
- 同じ絵しかでないんだけど・・・
-
yatoracat様記事
- プロンプトの削り方
- LoRA強度調整の方法(Pony向けの記事ですが基本的にはNovaFurry等でも同じです)
-
yatoracat様記事
- 非常に基本的なこと
-
Pony Diffusion公式おすすめのプロンプトの書き方を読む
- Clip Stepを2に設定しないと生成画像の品質が悪くなる→とても重要(らしい)
- Euler aで25ステップ、1024pxの画像がおすすめ
- furry専用コマンド、(N)SFW専用コマンドがある
- ここに書いていないですが、タグの重みも使えます
-
NovaFurry公式の配布ページ
- CFG Scale, プロンプト例など
-
Pony Diffusion公式おすすめのプロンプトの書き方を読む
- ちょっと慣れてきたら
- dynamic prompts
- LoRA強度、プロンプトなどをランダムにできる
- ControlNet + AnyTest
- 作ったものをペイントで適当に塗りつぶし修正したのをきれいに仕上げる
- 全然関係ない画像を自分のLoRAのキャラにする
- 例えば元々ない感情・ポーズの参考画像を元にしてLoRA・ノイズ強めにする
- 生成した画像をPNG Infoにいれるとプロンプトなどが調べられる
- SD WebUIはAPIで叩いたりそれを別PCに開放したりできる
- dynamic prompts
蛇足
定期的にサンプルが出せる機能があったので試してみた シード固定

15くらいでほぼ学習完了している感じ?