はじめに
タイトルの通りです。go言語を使って開発してて、make関数の挙動が理解できない部分が多々あるのに分かった風で使ってるのどうにかしたかったんです。
前提
まず基礎的なgolangのスライスの構造を理解するためには公式のドキュメントをみるのが一番早いです。
スライスを知るには配列についても理解しないとみたいですね。ざっくりと配列とスライスの特徴をまとめるとこんな感じでしょうか。
配列
-
配列型の定義は、長さと要素の型を指定する。
-
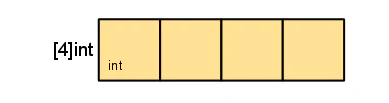
長さはその型の一部 (よって[4]int と [5]int は型としては別のものとして扱う)。
-
配列は変数定義した際実体となる。(配列値を代入または渡すときに、その内容のコピーを作成する。)
スライス
-
スライス型の定義は、厳密な長さの指定がなくても作成できる。(型指定は必要)
-
スライスは、make という組み込み関数を使用して作成する。
-
スライスは変数定義した際、配列を割り当て、その配列のアドレスを参照するスライスを返す。(スライスのゼロ値はnil、データをコピーしないので元の配列を指す新しいスライス値を作成します。)
両者にはこのような違いがありそう。
ここからはスライスを作成する際に必要なmake関数について見ていきます。
make関数とは
func make([]T, len, cap) []T // Tは作成するスライスの型を表す。
make関数は、型、長さ、オプショナルとして容量を指定する。呼び出されると、make は配列を割り当て、その配列を参照するスライスを返します。
容量は書かなくても定義できます。下二つは同じ内容のコードです。
var s []byte
s = make([]byte, 5, 5)
// s == []byte{0, 0, 0, 0, 0}
s := make([]byte, 5)
// s == []byte{0, 0, 0, 0, 0}
またスライスのゼロ値はnilです
s := []string{}
fmt.Println(len(s))
// 0
fmt.Println(cap(s))
// 0
fmt.Println(s[0])
// インデックス指定して実行するとpanicになる
// panic: runtime error: index out of range [0] with length 0
スライスの内部
スライスは配列へのポインター、セグメントの長さ、およびその容量 (セグメントの最大長) で構成されてます。
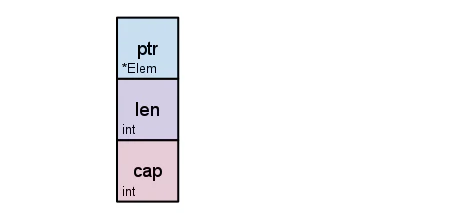
make([]byte, 5)を定義するとこんなイメージになる。
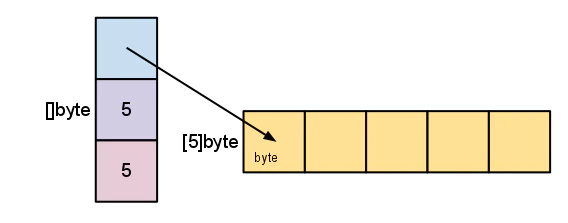
あらかじめ容量が決まっているのでその容量を超えて拡大することはできません。逸脱すると、スライスまたは配列の境界外にインデックスを作成する場合と同様に、panicが発生します。同様に、配列内の以前の要素にアクセスするために、スライスをゼロ未満に再スライスすることはできません。
スライスの拡張
スライスの容量を増やすには、新しい大きなスライスを作成し、元のスライスの内容をそこにコピーする必要があります。
copy関数
copyは異なる長さのスライス間のコピーができます
package main
import "fmt"
func main() {
s := make([]byte, 3, 3)
t := make([]byte, len(s), (cap(s)+1)*2)
copy(t, s)
s = t
fmt.Printf("s: %v 長さ: %d 容量: %d", s, len(s), cap(s))
// s: [0 0 0] 長さ: 3 容量: 8
}
append関数
append関数は要素をスライスの末尾に追加し、より大きな容量が必要な場合はスライスを拡張します。
package main
import "fmt"
func main() {
a := make([]int, 1)
// a == []int{0}
a = append(a, 1, 2, 3)
// a == []int{0, 1, 2, 3}
fmt.Printf("s: %v 長さ: %d 容量: %d", a, len(a), cap(a))
}
// s: [0 1 2 3] 長さ: 4 容量: 4
他にもGo Slices: usage and internalsにはA possible “gotcha”(考えられる「落とし穴」)として、一つのスライスから一部分だけを使用したい場合に、全体のスライスで使用しているメモリ使用量が保持され続ける事によってメモリ使用率が圧迫されてしまう問題についても取り上げてました。
これはスライスからスライスへ代入を行なっても共通の配列を見ている事によって、GCが適切に動作しないからであって、copy関数などうまく使って特定の部分を切り出して使用してくださいね的な事が書かれてました。
effective goもみてみる
上記までがスライスの基礎的な内容です。
ここからはeffective goをみつつお作法を調べていきます。
make()によるメモリ割り当て
下記にmakeによるメモリ割り当てについて記載がありました。
ここにmakeの挙動について記載があります。
make([]int, 10, 100)
上記は100個のintの配列を確保し、配列の最初の10個の要素を指す、長さ10、容量100のスライス構造体を作成します。
色々な定義方法についても言及されていました。
定義の仕方一覧
// 中身がnilの配列を見ているスライスへのポインタを定義しているケース。 この形はまず使用されなそう。
var p *[]int = new([]int)
// nilのスライス変数vを定義しmake関数で長さを定義して入れ直している。やや冗長。
var v []int = make([]int, 100)
// 中身がnilの配列を見ているスライスへのポインタを定義し、変数pのスライスにmake関数を使って生成した配列を代入している。すごくわかりづらい。。
var p *[]int = new([]int)
*p = make([]int, 100, 100)
// この書き方が一般的
v := make([]int, 100)
基本的にスライスはポインタ定義しない。(ポインタで明示的に定義しようとすると複雑になってしまう。)みたいですね。。
appendの挙動についてもっと詳しく
appendの挙動について深掘りします。
まず配列[3]int{0}の配列をみる変数aを定義し、それをbに代入。
そこに容量内に収まる分だけappendします。
package main
import "fmt"
func main() {
a := make([]int, 1, 3)
// a == []int{0}
b := a
b = append(b, 1, 2)
// b == []int{0, 1, 2}
fmt.Printf("a: %v 長さ: %d 容量: %d\n", a, len(a), cap(a))
// a: [0] 長さ: 1 容量: 3
fmt.Printf("b: %v 長さ: %d 容量: %d\n", b, len(b), cap(b))
// b: [0 1 2] 長さ: 3 容量: 3
fmt.Printf("a: %v b: %v\n", &a[0], &b[0])
// a: 0xc000018018 b: 0xc000018018
// 変数aとbは同じ配列をみている
}
これだとaとbは同じ配列をみている事がわかります。次に変数aの容量を少なくしてみます。
package main
import "fmt"
func main() {
a := make([]int, 1, 2) // <-容量を3から2へ
// a == []int{0}
b := a
b = append(b, 1, 2) // 2つintを追加するので容量オーバーとなる
// b == []int{0, 1, 2}
fmt.Printf("a: %v 長さ: %d 容量: %d\n", a, len(a), cap(a))
// a: [0] 長さ: 1 容量: 2
fmt.Printf("b: %v 長さ: %d 容量: %d\n", b, len(b), cap(b))
// b: [0 1 2] 長さ: 3 容量: 4
fmt.Printf("a: %v b: %v\n", &a[0], &b[0])
// a: 0xc00001c030 b: 0xc000100000
// 変数aとbの参照している配列が変わった。
}
上記のコードを実行すると今度は変数a,bが別々の配列を参照しています。
容量を超えた事によって新たに配列を定義し直している事がわかりますね。
appendの実装はこんな感じです。上記のコードと当てはめて処理の流れをみます。
func Append(slice, data[]byte) []byte {
// slice = bだと仮定(a := make([]int, 1, 2))
// sliceの長さは1
l := len(slice);
// sleceの長さ + 今回追加する数が現状のsliceの容量より大きい場合は再割り当てが行われる。
if l + len(data) > cap(slice) {
// 再割り当てとなる場合2倍の容量で作成される
newSlice := make([]byte, (l+len(data))*2);
for i, c := range slice {
newSlice[i] = c
}
slice = newSlice;
}
slice = slice[0:l+len(data)];
for i, c := range data {
slice[l+i] = c
}
return slice;
}
このようにappendを実行した際に元の容量をこ超える追加の必要がある場合に別に配列を作成している。