この記事は、不動産情報サイト LIFULL HOME'S などを運営する株式会社LIFULL の LIFULL Advent Calendar 2022 の記事です。
入社1年目、趣味は整理整頓、 @pal4de です。
正規表現が大好きです。
先日投稿した記事が好評いただき本当にうれしかったです。もっとたくさんの人に読んでもらいたい!!!
さて、上の記事で紹介したのは単語境界 \b でしたが、これは先読み/後読みを駆使して下記の通りに表せると紹介しました。
(?<=\W|^)(?=\w)|(?<=\w)(?=\W|$)
便利な\bですらショートハンドに過ぎず、真に強力なものは 先読み(?=...)と後読み(?<=...) だということを主張したい!!!
わかりすい図解も添えましたので、是非お楽しみください🏝️
正規表現の記号は4種類
先読みの紹介に入る前に、改めて正規表現を俯瞰してみましょう。
誤解を恐れずに言えば、正規表現に出てくる記号の種類は4つしかないといえます1 2。
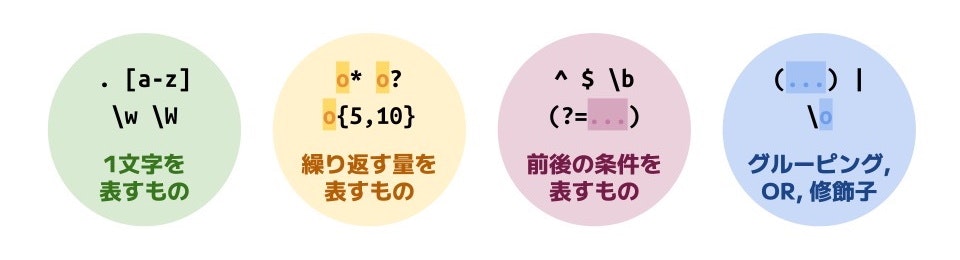
このようにとらえてみると、正規表現と向き合うのがだいぶ楽になります。体系化された理解への第一歩ですね 🗿
図にもある通り、 行頭 ^ も行末 $ も単語境界 \b も先読み (?=...) も後読み (?<=...) も 文字の前後の条件を表すもの に分類されます。
「文字の前後の条件を表すもの」の特徴
この 文字の前後の条件を表すもの の特徴は次の通りにとらえましょう。
- 1文字の前後の条件に関する特殊な表現
- 文字と文字の間にマッチする
- 0文字分の幅しか持たない (どれほど長く記述されていても)
例を見てみる
試しに const [level, setLevel] = useState(1); に対して 文字の前後の条件を表すもの を使ってみた例も見てみましょう3。
| 正規表現 | マッチの結果 | 解説 |
|---|---|---|
^ |
|const [level, setLevel] = useState(1); | 行頭にマッチ |
$ |
const [level, setLevel] = useState(1);| | 行末にマッチ |
\b |
|const| [|level|, |setLevel|] = |useState|(|1|); | 単語境界にマッチ |
(?=,) |
const [level|, setLevel] = useState(1); |
右側に , がある場所にマッチ |
(?<=set) |
const [level, set|Level] = useState(1); |
左側に set がある場所にマッチ |
どれも文字と文字の間にマッチしているイメージがつかめるはずです。
これに、ただの文字列levelを組み合わせると このグループの底力が垣間見えてきます。
| 正規表現 | マッチの結果 |
|---|---|
level |
const [level, setLevel] = useState(1); |
level(?=,) |
const [level, setLevel] = useState(1); |
(?<=set)level |
const [level, setLevel] = useState(1); |
先読みとは
本題です。
正規表現の先読み (?=...) とは、記述された部分よりも 右側の条件を表す 記号です。
先述の通り、文字の前後の条件を表すもの は0文字分の幅しか持ちません。
level(?=,)の例をビジュアルで表現するならば次のようなイメージです。

我ながらよくできた図だと思います。
否定先読み
先ほど紹介した 先読み (?=...) の逆、すなわち 右側の条件を満たさないことを表す 記号が 否定先読み (?!...) です4。
const [level, setLevel] = useState(1);
| 正規表現 | マッチの結果 | 解説 |
|---|---|---|
(?!,) |
|c|o|n|s|t| |[|l|e|v|e|l,| |s|e|t|L|e|v|e|l|]| |=| |u|s|e|S|t|a|t|e|(|1|)|;| | 右に,がない場所 |
level(?!,) |
const [level, setLevel] = useState(1); | 右に,がないlevel
|
後読みとは
先読みが「記述された部分よりも右側の条件を表す」ものでした。
後読み(?<=...)は当然、記述された部分よりも左側の条件を表します。
<が視覚的にも左向きなイメージを与えます。
(?<=set)levelの例をビジュアルで表現するならば次のようなイメージです。

パフォーマンス上の理由で、後読みは多くの環境で有限長のパターンしか使えません。
⭕ (?<=[0-9]hoge)fuga (後読み内パターン長が5文字で確定する)
❌ (?<=hoge.*)fuga (後読み内パターン長が無制限の可能性がある)
ただし、OR | で複数の有限長パターンを使えることがあります。
⭕ (?<=hoge|hogera)fuga (後読み内パターン長が4文字か6文字で確定する)
否定後読み
肯定先読み (?=...) と否定先読み (?!...) の関係と同様に、肯定後読み (?<=...) の否定版として 否定後読み (?<!...) があります。
応用例
簡単な応用例は省いて、ちょっとトリッキーな例をちょっと示してみます。
〇〇を含まない行
例えば、「remを含む行」は ^.*rem.*$と表せる一方、「remを含まない行」のような条件は難しかったりします。
否定先読み (?!...) を使うと次のように書き表せます5。
^((?!rem).)*$
日本語に意訳するなら「remが続かないような一文字が、最初から最後まで、任意長続く」ぐらいの意味になります。
この一文字ずつ先読みしていく方法は非常に応用が利くので覚えておくと便利です。
単語境界 (ケバブケース対応版)
単語境界 \b では、 ケバブケースの単語に対する検索結果は次のような結果となってしまいます。
| 正規表現 | 検索対象 | マッチの結果 |
|---|---|---|
\b |
user-icon | |user|-|icon| |
\buser-icon\b |
user-icon | user-icon |
\buser-icon\b |
user-icon-badge | user-icon-badge |
\buser-icon\b |
large-user-icon | large-user-icon |
(?<!-)\buser-icon\b(?!-)のように、「単語境界より左にハイフンが無い (?<!-)」「単語境界より右にハイフンが無い (?!-)」というニュアンスを両端に付け加えることで、スネークケースと同様の結果を得られます。
| 正規表現 | 検索対象 | マッチの結果 |
|---|---|---|
(?<!-)\buser-icon\b(?!-) |
user-icon | user-icon |
(?<!-)\buser-icon\b(?!-) |
user-icon-badge | user-icon-badge |
(?<!-)\buser-icon\b(?!-) |
large-user-icon | large-user-icon |
文字の前後の条件を表すもの は0文字分の幅しか占めないため、ANDのような感覚で条件の重ね掛けができるのがおもしろいんです
まとめ
- 先読み/後読み は 文字の前後の条件を表すもの です。
- 先読み/後読み はどれだけ長くとも0文字分の幅しか占めません。
- 先読み
(?=...)により、その場所よりも右側が満たすべき条件を記述できます。 ((?!...)で否定の意味) - 後読み
(?<=...)により、その場所よりも左側が満たすべき条件を記述できます。 ((?<!...)で否定の意味)
オマケ
「先読み」という名前について
私はかつて (?=...) が先読みなのか、後読みなのかよく混乱していました。
正直なところ正確に覚える必要なんてないと思ったりしますが、強いて言えば次のように覚えることになるのでしょうか。
正規表現は左から右に進んでいくものである。
(?=...)は「ここより右側の条件を指定するもの」であるので、進行方向の先を予め見ている。
よって、(?=...)は先読み。
処理系について
はてブで言及頂いたので追記します。
簡単のため処理系については言及しておりませんが、主題がコード検索であるため VSCode での挙動を念頭に置いています。
VSCodeでの具体的なFlavorについては今日まで知らなかったのですが、複数の処理系が併用されているようです。
先読み (?= ) (?! ) はおおよそどこでも使え、後読み (?<= ) (?<! ) は使えないことも多い、という程度の肌感でいます。
目立った仕様の違いもないように感じています。
ここまでご覧いただきありがとうございました!
弊社カレンダーの他の記事もぜひご覧ください😉