はじめに
実践Redis入門を読んでいてRedis Clusterがフェイルオーバーする時に次のmasterになるreplicaを選出する方法がよく分からなかったので、手元で動かしつつ挙動を確認してみました。
自分もまだまだ理解できていないことが多いので、解釈を間違えている箇所などあればご指摘いただけると幸いです🙇♂️
Redis Cluster構築
コンテナを起動する
docker-composeを使用します。
confファイルにはデバッグコマンドとClusterモードの使用のみを指定してます。
version: '3'
services:
node:
image: redis:latest
ports:
- 6379
volumes:
- $PWD/redis.conf:/usr/local/etc/redis/redis.conf
command: redis-server /usr/local/etc/redis/redis.conf
networks:
- redis_network
networks:
redis_network:
enable-debug-command yes
cluster-enabled yes
コンテナを立ち上げます。
今回はmaster3、replica3の構成にするので--scaleオプションで6つのコンテナを立ち上げるようにしました。
ログはリアルタイムで確認したいのでアタッチで起動しておき、以降の処理は別のターミナルで行います。
$ docker-compose up --scale node=6
ログ
Creating network "test-redis-cluster_redis_network" with the default driver
Creating test-redis-cluster_node_1 ... done
Creating test-redis-cluster_node_2 ... done
Creating test-redis-cluster_node_3 ... done
Creating test-redis-cluster_node_4 ... done
Creating test-redis-cluster_node_5 ... done
Creating test-redis-cluster_node_6 ... done
Attaching to test-redis-cluster_node_6, test-redis-cluster_node_5, test-redis-cluster_node_3, test-redis-cluster_node_4, test-redis-cluster_node_1, test-redis-cluster_node_2
node_1 | 1:C 06 Sep 2023 08:37:17.267 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
node_1 | 1:C 06 Sep 2023 08:37:17.267 # Redis version=7.0.11, bits=64, commit=00000000, modified=0, pid=1, just started
node_1 | 1:C 06 Sep 2023 08:37:17.267 # Configuration loaded
node_3 | 1:C 06 Sep 2023 08:37:17.235 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
node_3 | 1:C 06 Sep 2023 08:37:17.235 # Redis version=7.0.11, bits=64, commit=00000000, modified=0, pid=1, just started
node_3 | 1:C 06 Sep 2023 08:37:17.235 # Configuration loaded
node_3 | 1:M 06 Sep 2023 08:37:17.237 * monotonic clock: POSIX clock_gettime
node_1 | 1:M 06 Sep 2023 08:37:17.269 * monotonic clock: POSIX clock_gettime
node_1 | 1:M 06 Sep 2023 08:37:17.269 * No cluster configuration found, I'm b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602
node_5 | 1:C 06 Sep 2023 08:37:17.243 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
node_5 | 1:C 06 Sep 2023 08:37:17.243 # Redis version=7.0.11, bits=64, commit=00000000, modified=0, pid=1, just started
node_5 | 1:C 06 Sep 2023 08:37:17.243 # Configuration loaded
node_5 | 1:M 06 Sep 2023 08:37:17.243 * monotonic clock: POSIX clock_gettime
node_5 | 1:M 06 Sep 2023 08:37:17.243 * No cluster configuration found, I'm cc97431d2343a3ca7a57e6d6b4da6d37bb569198
node_4 | 1:C 06 Sep 2023 08:37:17.275 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
node_1 | 1:M 06 Sep 2023 08:37:17.274 * Running mode=cluster, port=6379.
node_1 | 1:M 06 Sep 2023 08:37:17.274 # Server initialized
node_3 | 1:M 06 Sep 2023 08:37:17.239 * No cluster configuration found, I'm a6049751e651642f261095950d469a6b0cb8e611
node_3 | 1:M 06 Sep 2023 08:37:17.244 * Running mode=cluster, port=6379.
node_3 | 1:M 06 Sep 2023 08:37:17.244 # Server initialized
node_3 | 1:M 06 Sep 2023 08:37:17.246 * Ready to accept connections
node_6 | 1:C 06 Sep 2023 08:37:17.189 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
node_6 | 1:C 06 Sep 2023 08:37:17.189 # Redis version=7.0.11, bits=64, commit=00000000, modified=0, pid=1, just started
node_6 | 1:C 06 Sep 2023 08:37:17.189 # Configuration loaded
node_4 | 1:C 06 Sep 2023 08:37:17.275 # Redis version=7.0.11, bits=64, commit=00000000, modified=0, pid=1, just started
node_4 | 1:C 06 Sep 2023 08:37:17.275 # Configuration loaded
node_6 | 1:M 06 Sep 2023 08:37:17.190 * monotonic clock: POSIX clock_gettime
node_6 | 1:M 06 Sep 2023 08:37:17.191 * No cluster configuration found, I'm 8fe04f39df4e6b453a395da23f25bdc060559847
node_6 | 1:M 06 Sep 2023 08:37:17.195 * Running mode=cluster, port=6379.
node_4 | 1:M 06 Sep 2023 08:37:17.276 * monotonic clock: POSIX clock_gettime
node_4 | 1:M 06 Sep 2023 08:37:17.277 * No cluster configuration found, I'm 382223b947b401c45495a01c254e466630750c80
node_5 | 1:M 06 Sep 2023 08:37:17.247 * Running mode=cluster, port=6379.
node_5 | 1:M 06 Sep 2023 08:37:17.247 # Server initialized
node_6 | 1:M 06 Sep 2023 08:37:17.195 # Server initialized
node_6 | 1:M 06 Sep 2023 08:37:17.197 * Ready to accept connections
node_1 | 1:M 06 Sep 2023 08:37:17.277 * Ready to accept connections
node_5 | 1:M 06 Sep 2023 08:37:17.248 * Ready to accept connections
node_4 | 1:M 06 Sep 2023 08:37:17.279 * Running mode=cluster, port=6379.
node_4 | 1:M 06 Sep 2023 08:37:17.280 # Server initialized
node_4 | 1:M 06 Sep 2023 08:37:17.282 * Ready to accept connections
node_2 | 1:C 06 Sep 2023 08:37:17.283 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
node_2 | 1:C 06 Sep 2023 08:37:17.283 # Redis version=7.0.11, bits=64, commit=00000000, modified=0, pid=1, just started
node_2 | 1:C 06 Sep 2023 08:37:17.283 # Configuration loaded
node_2 | 1:M 06 Sep 2023 08:37:17.284 * monotonic clock: POSIX clock_gettime
node_2 | 1:M 06 Sep 2023 08:37:17.285 * No cluster configuration found, I'm bf59ab9a08f7c39bceaaec562acfc2ca90f84621
node_2 | 1:M 06 Sep 2023 08:37:17.288 * Running mode=cluster, port=6379.
node_2 | 1:M 06 Sep 2023 08:37:17.288 # Server initialized
node_2 | 1:M 06 Sep 2023 08:37:17.292 * Ready to accept connections
Redis ClusterをCreateする
Redis Clusterを構築します。
前処理として、各ノードのIPを変数に入れています。
$ NODES=`docker network inspect test-redis-cluster_redis_network | jq -r '.[0].Containers | .[].IPv4Address' | sed -e 's/\/16/:6379 /g' | sed -e ':a' -e 'N' -e '$!ba' -e 's/\n//g'`
$ echo $NODES
172.27.0.7:6379 172.27.0.4:6379 172.27.0.5:6379 172.27.0.6:6379 172.27.0.2:6379 172.27.0.3:6379
$ docker-compose exec node bash -c "redis-cli --cluster create ${NODES} --cluster-replicas 1"
ログ
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.27.0.2:6379 to 172.27.0.7:6379
Adding replica 172.27.0.3:6379 to 172.27.0.4:6379
Adding replica 172.27.0.6:6379 to 172.27.0.5:6379
M: b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602 172.27.0.7:6379
slots:[0-5460] (5461 slots) master
M: a6049751e651642f261095950d469a6b0cb8e611 172.27.0.4:6379
slots:[5461-10922] (5462 slots) master
M: 382223b947b401c45495a01c254e466630750c80 172.27.0.5:6379
slots:[10923-16383] (5461 slots) master
S: bf59ab9a08f7c39bceaaec562acfc2ca90f84621 172.27.0.6:6379
replicates 382223b947b401c45495a01c254e466630750c80
S: 8fe04f39df4e6b453a395da23f25bdc060559847 172.27.0.2:6379
replicates b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602
S: cc97431d2343a3ca7a57e6d6b4da6d37bb569198 172.27.0.3:6379
replicates a6049751e651642f261095950d469a6b0cb8e611
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 172.27.0.7:6379)
M: b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602 172.27.0.7:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 8fe04f39df4e6b453a395da23f25bdc060559847 172.27.0.2:6379
slots: (0 slots) slave
replicates b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602
S: bf59ab9a08f7c39bceaaec562acfc2ca90f84621 172.27.0.6:6379
slots: (0 slots) slave
replicates 382223b947b401c45495a01c254e466630750c80
S: cc97431d2343a3ca7a57e6d6b4da6d37bb569198 172.27.0.3:6379
slots: (0 slots) slave
replicates a6049751e651642f261095950d469a6b0cb8e611
M: 382223b947b401c45495a01c254e466630750c80 172.27.0.5:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: a6049751e651642f261095950d469a6b0cb8e611 172.27.0.4:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
一部抜粋すると、node_1(172.27.0.7)をマスターとして、node_6(172.27.0.2)がレプリカになっていることが分かります。
M: b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602 172.27.0.7:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 8fe04f39df4e6b453a395da23f25bdc060559847 172.27.0.2:6379
slots: (0 slots) slave
replicates b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602
アタッチ状態のターミナルでは以下のようなログが出力されます。
ログ
node_1 | 1:M 06 Sep 2023 08:39:06.156 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH
node_3 | 1:M 06 Sep 2023 08:39:06.156 # configEpoch set to 2 via CLUSTER SET-CONFIG-EPOCH
node_4 | 1:M 06 Sep 2023 08:39:06.157 # configEpoch set to 3 via CLUSTER SET-CONFIG-EPOCH
node_2 | 1:M 06 Sep 2023 08:39:06.157 # configEpoch set to 4 via CLUSTER SET-CONFIG-EPOCH
node_6 | 1:M 06 Sep 2023 08:39:06.158 # configEpoch set to 5 via CLUSTER SET-CONFIG-EPOCH
node_5 | 1:M 06 Sep 2023 08:39:06.158 # configEpoch set to 6 via CLUSTER SET-CONFIG-EPOCH
node_1 | 1:M 06 Sep 2023 08:39:06.195 # IP address for this node updated to 172.27.0.7
node_6 | 1:M 06 Sep 2023 08:39:06.297 # IP address for this node updated to 172.27.0.2
node_2 | 1:M 06 Sep 2023 08:39:06.298 # IP address for this node updated to 172.27.0.6
node_3 | 1:M 06 Sep 2023 08:39:06.298 # IP address for this node updated to 172.27.0.4
node_5 | 1:M 06 Sep 2023 08:39:06.298 # IP address for this node updated to 172.27.0.3
node_4 | 1:M 06 Sep 2023 08:39:06.298 # IP address for this node updated to 172.27.0.5
node_2 | 1:S 06 Sep 2023 08:39:07.162 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
node_2 | 1:S 06 Sep 2023 08:39:07.162 * Connecting to MASTER 172.27.0.5:6379
node_2 | 1:S 06 Sep 2023 08:39:07.162 * MASTER <-> REPLICA sync started
node_2 | 1:S 06 Sep 2023 08:39:07.162 # Cluster state changed: ok
node_2 | 1:S 06 Sep 2023 08:39:07.162 * Non blocking connect for SYNC fired the event.
node_6 | 1:S 06 Sep 2023 08:39:07.163 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
node_2 | 1:S 06 Sep 2023 08:39:07.163 * Master replied to PING, replication can continue...
node_2 | 1:S 06 Sep 2023 08:39:07.163 * Trying a partial resynchronization (request 412d504d4a874b33efa641ca6da7b420db87c1dc:1).
node_6 | 1:S 06 Sep 2023 08:39:07.163 * Connecting to MASTER 172.27.0.7:6379
node_6 | 1:S 06 Sep 2023 08:39:07.163 * MASTER <-> REPLICA sync started
node_6 | 1:S 06 Sep 2023 08:39:07.163 # Cluster state changed: ok
node_6 | 1:S 06 Sep 2023 08:39:07.163 * Non blocking connect for SYNC fired the event.
node_5 | 1:S 06 Sep 2023 08:39:07.164 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
node_5 | 1:S 06 Sep 2023 08:39:07.164 * Connecting to MASTER 172.27.0.4:6379
node_5 | 1:S 06 Sep 2023 08:39:07.164 * MASTER <-> REPLICA sync started
node_5 | 1:S 06 Sep 2023 08:39:07.164 # Cluster state changed: ok
node_4 | 1:M 06 Sep 2023 08:39:07.164 * Replica 172.27.0.6:6379 asks for synchronization
node_6 | 1:S 06 Sep 2023 08:39:07.166 * Master replied to PING, replication can continue...
node_4 | 1:M 06 Sep 2023 08:39:07.164 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '412d504d4a874b33efa641ca6da7b420db87c1dc', my replication IDs are 'a0a4beddfcaf11abea7b7b5a05c8f6e8ce426d48' and '0000000000000000000000000000000000000000')
node_4 | 1:M 06 Sep 2023 08:39:07.164 * Replication backlog created, my new replication IDs are '40c42a17e28ff6e039c38f565c54f3ad4bb76881' and '0000000000000000000000000000000000000000'
node_4 | 1:M 06 Sep 2023 08:39:07.164 * Delay next BGSAVE for diskless SYNC
node_5 | 1:S 06 Sep 2023 08:39:07.164 * Non blocking connect for SYNC fired the event.
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Replica 172.27.0.2:6379 asks for synchronization
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '9df651b1729a067c6cb6ef216e93ac3cbd3b23a1', my replication IDs are 'f9f16c0a4046bff27d18a0b7a78e959715e44180' and '0000000000000000000000000000000000000000')
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Replication backlog created, my new replication IDs are '1d3c4b9e83fe1771fed2b03e6ce385f12ec9b614' and '0000000000000000000000000000000000000000'
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Delay next BGSAVE for diskless SYNC
node_5 | 1:S 06 Sep 2023 08:39:07.166 * Master replied to PING, replication can continue...
node_6 | 1:S 06 Sep 2023 08:39:07.166 * Trying a partial resynchronization (request 9df651b1729a067c6cb6ef216e93ac3cbd3b23a1:1).
node_3 | 1:M 06 Sep 2023 08:39:07.167 * Replica 172.27.0.3:6379 asks for synchronization
node_3 | 1:M 06 Sep 2023 08:39:07.167 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'a185e6b510870587a61eb2d9d3d262c2c68e6623', my replication IDs are 'b2728e79267eedddf20198120262edee523fcab7' and '0000000000000000000000000000000000000000')
node_3 | 1:M 06 Sep 2023 08:39:07.167 * Replication backlog created, my new replication IDs are '50f8e3341e3ca47f153233cbc402cdb5cb31bf81' and '0000000000000000000000000000000000000000'
node_3 | 1:M 06 Sep 2023 08:39:07.167 * Delay next BGSAVE for diskless SYNC
node_5 | 1:S 06 Sep 2023 08:39:07.166 * Trying a partial resynchronization (request a185e6b510870587a61eb2d9d3d262c2c68e6623:1).
node_4 | 1:M 06 Sep 2023 08:39:11.133 # Cluster state changed: ok
node_3 | 1:M 06 Sep 2023 08:39:11.133 # Cluster state changed: ok
node_1 | 1:M 06 Sep 2023 08:39:11.134 # Cluster state changed: ok
node_3 | 1:M 06 Sep 2023 08:39:12.042 * Starting BGSAVE for SYNC with target: replicas sockets
node_4 | 1:M 06 Sep 2023 08:39:12.042 * Starting BGSAVE for SYNC with target: replicas sockets
node_5 | 1:S 06 Sep 2023 08:39:12.042 * Full resync from master: 50f8e3341e3ca47f153233cbc402cdb5cb31bf81:14
node_1 | 1:M 06 Sep 2023 08:39:12.042 * Starting BGSAVE for SYNC with target: replicas sockets
node_2 | 1:S 06 Sep 2023 08:39:12.042 * Full resync from master: 40c42a17e28ff6e039c38f565c54f3ad4bb76881:14
node_6 | 1:S 06 Sep 2023 08:39:12.043 * Full resync from master: 1d3c4b9e83fe1771fed2b03e6ce385f12ec9b614:14
node_4 | 1:M 06 Sep 2023 08:39:12.045 * Background RDB transfer started by pid 21
node_1 | 1:M 06 Sep 2023 08:39:12.045 * Background RDB transfer started by pid 27
node_3 | 1:M 06 Sep 2023 08:39:12.045 * Background RDB transfer started by pid 21
node_2 | 1:S 06 Sep 2023 08:39:12.047 * MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF to disk
node_2 | 1:S 06 Sep 2023 08:39:12.047 * Discarding previously cached master state.
node_2 | 1:S 06 Sep 2023 08:39:12.047 * MASTER <-> REPLICA sync: Flushing old data
node_3 | 21:C 06 Sep 2023 08:39:12.047 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
node_6 | 1:S 06 Sep 2023 08:39:12.047 * MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF to disk
node_6 | 1:S 06 Sep 2023 08:39:12.047 * Discarding previously cached master state.
node_5 | 1:S 06 Sep 2023 08:39:12.047 * MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF to disk
node_1 | 27:C 06 Sep 2023 08:39:12.047 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
node_4 | 21:C 06 Sep 2023 08:39:12.047 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
node_4 | 1:M 06 Sep 2023 08:39:12.047 # Diskless rdb transfer, done reading from pipe, 1 replicas still up.
node_5 | 1:S 06 Sep 2023 08:39:12.048 * Discarding previously cached master state.
node_5 | 1:S 06 Sep 2023 08:39:12.048 * MASTER <-> REPLICA sync: Flushing old data
node_6 | 1:S 06 Sep 2023 08:39:12.047 * MASTER <-> REPLICA sync: Flushing old data
node_3 | 1:M 06 Sep 2023 08:39:12.047 # Diskless rdb transfer, done reading from pipe, 1 replicas still up.
node_2 | 1:S 06 Sep 2023 08:39:12.047 * MASTER <-> REPLICA sync: Loading DB in memory
node_6 | 1:S 06 Sep 2023 08:39:12.047 * MASTER <-> REPLICA sync: Loading DB in memory
node_1 | 1:M 06 Sep 2023 08:39:12.047 # Diskless rdb transfer, done reading from pipe, 1 replicas still up.
node_5 | 1:S 06 Sep 2023 08:39:12.048 * MASTER <-> REPLICA sync: Loading DB in memory
node_2 | 1:S 06 Sep 2023 08:39:12.052 * Loading RDB produced by version 7.0.11
node_2 | 1:S 06 Sep 2023 08:39:12.052 * RDB age 0 seconds
node_2 | 1:S 06 Sep 2023 08:39:12.052 * RDB memory usage when created 1.82 Mb
node_2 | 1:S 06 Sep 2023 08:39:12.052 * Done loading RDB, keys loaded: 0, keys expired: 0.
node_1 | 1:M 06 Sep 2023 08:39:12.052 * Background RDB transfer terminated with success
node_1 | 1:M 06 Sep 2023 08:39:12.052 * Streamed RDB transfer with replica 172.27.0.2:6379 succeeded (socket). Waiting for REPLCONF ACK from slave to enable streaming
node_1 | 1:M 06 Sep 2023 08:39:12.052 * Synchronization with replica 172.27.0.2:6379 succeeded
node_6 | 1:S 06 Sep 2023 08:39:12.051 * Loading RDB produced by version 7.0.11
node_6 | 1:S 06 Sep 2023 08:39:12.051 * RDB age 0 seconds
node_6 | 1:S 06 Sep 2023 08:39:12.051 * RDB memory usage when created 1.78 Mb
node_6 | 1:S 06 Sep 2023 08:39:12.051 * Done loading RDB, keys loaded: 0, keys expired: 0.
node_6 | 1:S 06 Sep 2023 08:39:12.051 * MASTER <-> REPLICA sync: Finished with success
node_3 | 1:M 06 Sep 2023 08:39:12.053 * Background RDB transfer terminated with success
node_3 | 1:M 06 Sep 2023 08:39:12.053 * Streamed RDB transfer with replica 172.27.0.3:6379 succeeded (socket). Waiting for REPLCONF ACK from slave to enable streaming
node_3 | 1:M 06 Sep 2023 08:39:12.053 * Synchronization with replica 172.27.0.3:6379 succeeded
node_2 | 1:S 06 Sep 2023 08:39:12.052 * MASTER <-> REPLICA sync: Finished with success
node_5 | 1:S 06 Sep 2023 08:39:12.053 * Loading RDB produced by version 7.0.11
node_5 | 1:S 06 Sep 2023 08:39:12.053 * RDB age 0 seconds
node_5 | 1:S 06 Sep 2023 08:39:12.053 * RDB memory usage when created 1.82 Mb
node_5 | 1:S 06 Sep 2023 08:39:12.053 * Done loading RDB, keys loaded: 0, keys expired: 0.
node_5 | 1:S 06 Sep 2023 08:39:12.053 * MASTER <-> REPLICA sync: Finished with success
node_4 | 1:M 06 Sep 2023 08:39:12.053 * Background RDB transfer terminated with success
node_4 | 1:M 06 Sep 2023 08:39:12.053 * Streamed RDB transfer with replica 172.27.0.6:6379 succeeded (socket). Waiting for REPLCONF ACK from slave to enable streaming
node_4 | 1:M 06 Sep 2023 08:39:12.053 * Synchronization with replica 172.27.0.6:6379 succeeded
マスターとレプリカの同期
レプリカがマスターと同期する方法は2種類あり、完全同期または部分同期のどちらかで行います。
完全同期はマスターの全データをダンプして転送するので、状況を選ばずいつでも実行可能ですがネットワーク帯域圧迫など、パフォーマンス面に注意する必要があります。
部分同期はレプリケーションが切断されている最中の差分だけ同期するので、完全同期と比べて同期データが少なく済みますが、レプリケーションバックログ(マスターの持つバッファ)にレプリカのオフセットが含まれていない場合は行えません(レプリケーション切断中にバックログのサイズ以上データが書き込まれるなど)
アタッチ状態のターミナルのログを見ると、node_6(レプリカ)はnode_1(マスター)に対してまず部分同期するリクエストを行なっています。
node_6 | 1:S 06 Sep 2023 08:39:07.163 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
node_6 | 1:S 06 Sep 2023 08:39:07.163 * Connecting to MASTER 172.27.0.7:6379
node_6 | 1:S 06 Sep 2023 08:39:07.163 * MASTER <-> REPLICA sync started
node_6 | 1:S 06 Sep 2023 08:39:07.163 # Cluster state changed: ok
node_6 | 1:S 06 Sep 2023 08:39:07.163 * Non blocking connect for SYNC fired the event.
node_6 | 1:S 06 Sep 2023 08:39:07.166 * Master replied to PING, replication can continue...
node_6 | 1:S 06 Sep 2023 08:39:07.166 * Trying a partial resynchronization (request 9df651b1729a067c6cb6ef216e93ac3cbd3b23a1:1).
しかし、node_1(マスター)はできたてほやほやで当然バックログにレプリカのオフセットなどあろうはずもないので、部分同期が失敗し完全同期が行われます。
Streamed RDB transfer with replica 172.27.0.2:6379 succeeded (socket).で完全同期が成功したことが分かります(172.27.0.2はnode_6のIP)
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Replica 172.27.0.2:6379 asks for synchronization
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '9df651b1729a067c6cb6ef216e93ac3cbd3b23a1', my replication IDs are 'f9f16c0a4046bff27d18a0b7a78e959715e44180' and '0000000000000000000000000000000000000000')
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Replication backlog created, my new replication IDs are '1d3c4b9e83fe1771fed2b03e6ce385f12ec9b614' and '0000000000000000000000000000000000000000'
node_1 | 1:M 06 Sep 2023 08:39:07.166 * Delay next BGSAVE for diskless SYNC
node_1 | 1:M 06 Sep 2023 08:39:12.042 * Starting BGSAVE for SYNC with target: replicas sockets
node_1 | 1:M 06 Sep 2023 08:39:12.045 * Background RDB transfer started by pid 27
node_1 | 27:C 06 Sep 2023 08:39:12.047 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
node_1 | 1:M 06 Sep 2023 08:39:12.047 # Diskless rdb transfer, done reading from pipe, 1 replicas still up.
node_1 | 1:M 06 Sep 2023 08:39:12.052 * Background RDB transfer terminated with success
node_1 | 1:M 06 Sep 2023 08:39:12.052 * Streamed RDB transfer with replica 172.27.0.2:6379 succeeded (socket). Waiting for REPLCONF ACK from slave to enable streaming
node_1 | 1:M 06 Sep 2023 08:39:12.052 * Synchronization with replica 172.27.0.2:6379 succeeded
ノードの状態を確認する
コンテナIDを確認します。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c95717cf74af redis:latest "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:60434->6379/tcp test-redis-cluster_node_2
c1facc6773b9 redis:latest "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:60432->6379/tcp test-redis-cluster_node_4
666bb02b9458 redis:latest "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:60431->6379/tcp test-redis-cluster_node_3
02897e83f47f redis:latest "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:60433->6379/tcp test-redis-cluster_node_1
dfafdb0e2309 redis:latest "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:60430->6379/tcp test-redis-cluster_node_5
da59e140c108 redis:latest "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:60429->6379/tcp test-redis-cluster_node_6
起動時に各ノードの状態はnodes.confというファイルに記録されるので、このファイルを見てマスターとレプリカの関係を確認してみます(redis-cliの CLUSTER NODESコマンドなどでも確認できます)。
$ docker exec 02897e83f47f bash -c "cat nodes.conf"
8fe04f39df4e6b453a395da23f25bdc060559847 172.27.0.2:6379@16379 slave b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602 0 1693989548918 1 connected
bf59ab9a08f7c39bceaaec562acfc2ca90f84621 172.27.0.6:6379@16379 slave 382223b947b401c45495a01c254e466630750c80 0 1693989547000 3 connected
cc97431d2343a3ca7a57e6d6b4da6d37bb569198 172.27.0.3:6379@16379 slave a6049751e651642f261095950d469a6b0cb8e611 0 1693989547000 2 connected
382223b947b401c45495a01c254e466630750c80 172.27.0.5:6379@16379 master - 0 1693989547908 3 connected 10923-16383
a6049751e651642f261095950d469a6b0cb8e611 172.27.0.4:6379@16379 master - 0 1693989548000 2 connected 5461-10922
b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602 172.27.0.7:6379@16379 myself,master - 0 1693989546000 1 connected 0-5460
vars currentEpoch 6 lastVoteEpoch 0
各パラメータは以下の順に並んでいます。
| 項目 | 概要 |
|---|---|
| id | ノードID |
| ip:port@cport | ノードのアドレスとポート。cportはクラスターバスポートと言い、ノード間でやりとりするためのポートで、デフォルトでは通常のポートに1万を足したもの |
| flags | ノードの状態 |
| master | レプリカならmasterのノードID、masterなら- |
| ping-sent | アクティブなpingが送信されたUNIX時間 |
| pong-recv | 最後にpingの応答を受け取ったUNIX時間 |
| config-epoch | configEpochの値(後述) |
| link-state | ノード間クラスターバスでの接続状態 |
| slot | 割り当てられたハッシュスロットの範囲 |
node_6(172.27.0.2)がnode_1(172.27.0.7)をマスターとして参照していることが分かりますね。
また、0〜16383までのスロットがマスターにそれぞれ均等に割り当てられていることも確認できます。
フェイルオーバー
epoch
Redis Clusterではepochという値を使ってノードの状態をバージョニングし、最新の情報を共有しながらフェイルオーバーを行います。
(Raftという分散同意アルゴリズムのtermと似たような概念らしいです)
epochは以下の3種類があります。
-
currentEpoch
- クラスター全体の現在の状態を管理する
- currentEpochがインクリメントされると、クラスターの状態が変化したことを表す
- 全てのノードがcurrentEpochに同意する必要があり、これにより一貫性を保つ
-
configEpoch
- シャードごとに一意の数値が割り当てられる
- 新しい設定が適用されるとインクリメントされる
- 異なるノードが異なる構成を主張した際、コンフリクトを解消するために役立つ
-
lastVoteEpoch
- レプリカから認証リクエストが来た際に用いる
- マスターは自身のlastVoteEpochより古いcurrentEpochを持つレプリカからの認証リクエストは拒否する
- レプリカに投票した後に更新される
レプリカをマスターに昇格させる手順
マスターがダウンした時、新たにマスターに昇格させるレプリカは以下の手順で選出します。
- レプリカはcurrentEpochをインクリメントし、他のマスターに対してFALOVER_AUTH_REQUEST(認証リクエスト)を送信した後、
cluster-node-timeout * 2秒の間投票を待機する - マスターはFALOVER_AUTH_REQUESTを受け取ったら、送信元のレプリカのcurrentEpochを確認する。currentEpochがマスターのcurrentEpochおよびlastVoteEpochより小さければ投票を受け付けない
- 正常に投票を受け付けたらFAILOVER_AUTH_ACK(投票)を返して、lastVoteEpochをレプリカのcurrentEpochに更新する
- レプリカは過半数のマスターから投票を受け付けるとマスターに昇格し、configEpochを最新のcurrentEpochに更新する
マスターは投票した後、cluster-node-timeout * 2秒間は他のレプリカからの認証リクエストに答えず、各エポックで1回しか投票できないので、ダウンしたマスターに紐づくレプリカが複数存在する場合は早く認証リクエストしたレプリカが有利になります。
しかし、レプリカはマスターがFAIL状態になることを確認したらすぐに認証リクエストを送信するのではなく、以下の時間だけ待機する必要があります。
500ms + 0~500ms(ランダム) + REPLICA_RANK * 1000ms
それぞれのパラメータの内訳は以下の通りです。
- 500ms
- マスターがFAILになっているという情報がクラスター内に伝播されるのを待つための時間
- 0~500ms
- 1レプリカが同時にマスターとして選出されるのを避ける時間
- REPLICA_RANK * 1000
- REPLICA_RANKはレプリケーションオフセットが進んでいるレプリカ順に0から連番で振られる
要するに、オフセットが最も進んでいる(マスターと最も近い情報を持つ)レプリカは認証リクエストを早く送信できて昇格しやすくなるわけですね。
マスターを停止してフェイルオーバーを行う
それではnode_1(master)をダウンさせてフェイルオーバーの挙動を見てみましょう。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b7f1da8d42ff redis:latest "docker-entrypoint.s…" 7 minutes ago Up 7 minutes 0.0.0.0:55686->6379/tcp test-redis-cluster_node_1
18ada60b2206 redis:latest "docker-entrypoint.s…" 7 minutes ago Up 7 minutes 0.0.0.0:55687->6379/tcp test-redis-cluster_node_2
...
$ docker exec -it b7f1da8d42ff bash
# redis-cli
> DEBUG SEGFAULT
node_1(マスター)をダウンさせました。nodes.confを確認すると、node_1(172.27.0.7)がfailになっており、node_3(172.27.0.2)がマスターに昇格していることが確認できますね。
$ docker exec da59e140c108 bash -c "cat nodes.conf"
b969fd526f09d3ca5d1c9d6dbc7fd2d08ed21602 172.27.0.7:6379@16379 master,fail - 1693993459028 1693993454000 1 connected
8fe04f39df4e6b453a395da23f25bdc060559847 172.27.0.2:6379@16379 myself,master - 0 1693993471000 7 connected 0-5460
bf59ab9a08f7c39bceaaec562acfc2ca90f84621 172.27.0.6:6379@16379 slave 382223b947b401c45495a01c254e466630750c80 0 1693993471116 3 connected
cc97431d2343a3ca7a57e6d6b4da6d37bb569198 172.27.0.3:6379@16379 slave a6049751e651642f261095950d469a6b0cb8e611 0 1693993470000 2 connected
382223b947b401c45495a01c254e466630750c80 172.27.0.5:6379@16379 master - 0 1693993471000 3 connected 10923-16383
a6049751e651642f261095950d469a6b0cb8e611 172.27.0.4:6379@16379 master - 0 1693993472125 2 connected 5461-10922
vars currentEpoch 7 lastVoteEpoch 0
epochの挙動の流れについて図でも確認してみます。
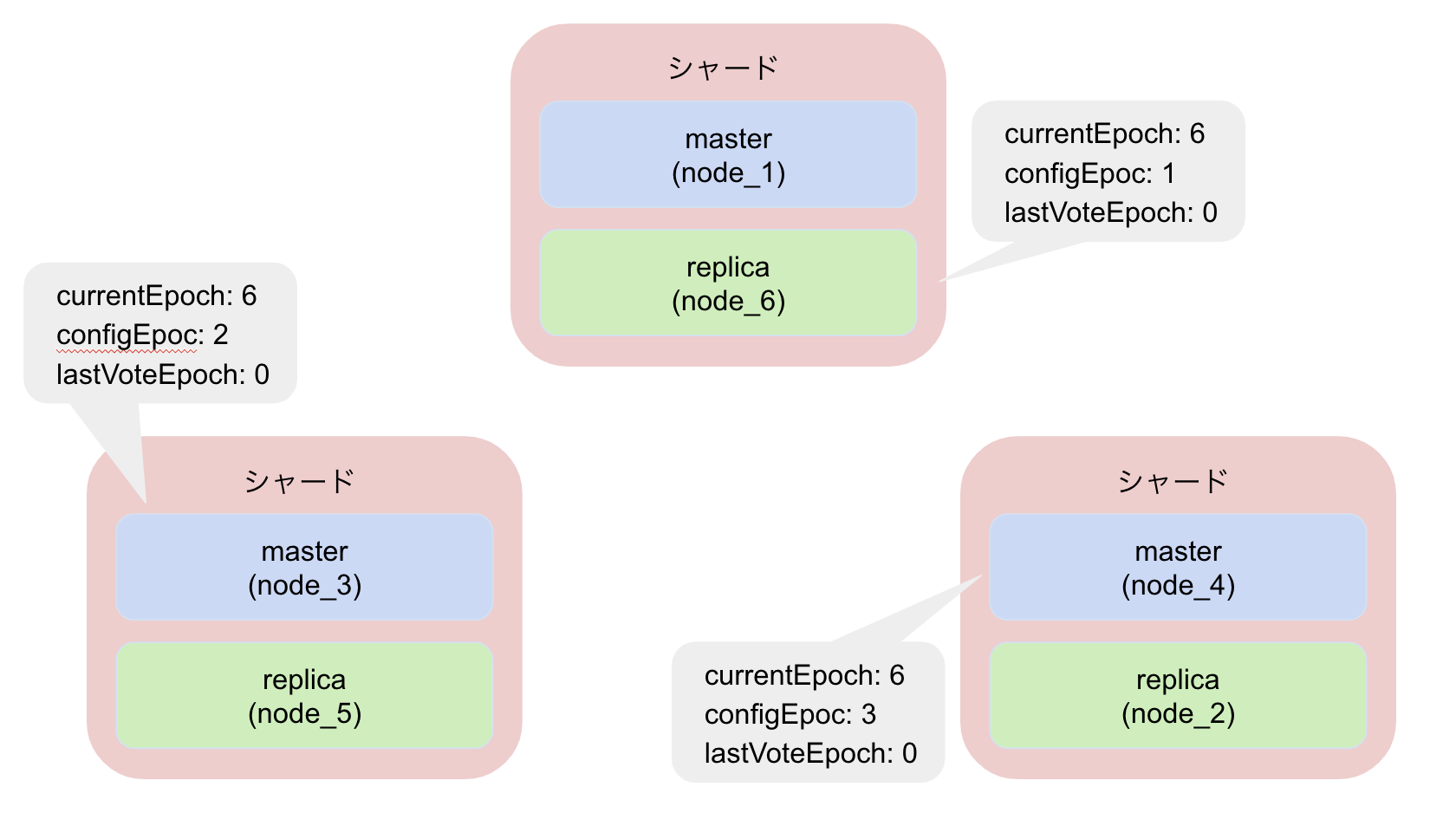
フェイルオーバー前の状態です。まだnode_1は生きていますね。
node_6、node_3、noed_4の各種epochの変化を見ていきましょう。

node_1を停止しました。
node_6は500ms + 0~500ms(ランダム) + REPLICA_RANK * 1000msだけ待機した後、自身のcurrentEpochをインクリメントしてFAILOVER_AUTH_REQUESTをnode_3とnode_4に送信します。

node_3とnode_4は送信元レプリカのcurrentEpochが自身のcurrentEpoch、lastVoteEpochよりも大きいことを確認し、それぞれ送信元currentEpochと同じ値に更新した後、node_6にFAILOVER_AUTH_ACKを送信します。

node_6は過半数からの投票を得られたのでconfigEpochをcurrentEpochと同じ値に更新し、無事マスターに昇格することができました!
おわりに
docker-composeを使ってローカルでRedis Clusterを構築しながら、フェイルオーバー時のレプリカの選出の流れについて図解で見ていきました。
epochを意識してRedis Clusterを触る機会は少ないかもしれないですが、へーこういう流れでマスターに昇格するのかーくらいの感想を持っていただければ幸いです。
ではまた。