Advent Calendarへの参加は、というかQiitaへの投稿自体が初めてなので緊張します。
本記事ではCloud Spannerについての概説と設計上の要点などをまとめてみました。技術的な解説というよりは実設計レベルの話を中心にします。
今後ますます注目されるサービスだと思いますが、これから使う人にとって理解の一助になれば幸いです。
ちなみに本記事はスケールアウトするSQLシステム(2017/8/22)での発表をベースにしています。ほとんどはこの時に話した内容そのままです。
このイベントでの発表スライドも参考にしてみてください。
Cloud Spannerとは
GCPで提供されているデータベースサービスのひとつで、2012年ごろからGoogle社内では使用されてきた。
2017年2月にGCPサービスとしてβリリース、2017年7月には東京リージョンで正式版が提供されている。
Google社内ではAdWordsやGooglePlayなどのサービスで使っているらしく、使用規模や信頼性は十分であることが分かる。
GCPのデータベース比較
GCPにはデータベースとして使えるサービスはいくつかあり、それぞれ得意な領域や料金体系が異なる。
- Cloud Bigtable
- Cloud Datastore
- Cloud SQL
- Cloud Spanner
- Firebase
本題ではないが、それぞれのサービスについてさわりだけ説明する。
(筆者は全部を触ったわけではないので参考程度に)
Cloud Bigtable
スケーラビリティの高いNoSQLで、GCPのデータベースサービスとしては最も高パフォーマンス(たぶん)。料金はお高め。
シャーディングがフルマネージドで、文字通り「Big」なデータを扱うことに長けている。IoTなどで使うのに適している。
トランザクションはなく、複雑なことをするのには不向き。
BigQueryから直接クエリを投げられるというのは地味なメリット。
なお2017年12月現在では東京リージョンがない。
Cloud Datastore
Bigtableのアーキテクチャ上に構築されたサービス。
リレーショナルじゃないデータベースだが、複数のキーをまたいだトランザクションも使えたりする。
スケールイン・スケールアウトともフルマネージド。
月間あたりの使用量について無料枠がある。そのためスモールスタートにとても適してると言える。
すでに数多くのスマホゲームでも使用されていることから分かるようにRDBMSからの置き換えとしてはまずDatastoreが挙がる。
しかしDatastoreを使う場合、RDBMSを使う場合とは設計思想がかなり異なってくるので「置き換えには結構苦労した」な話もよく聞く。
Cloud SQL
GCP上で使えるMySQLで、2ndGenerationになり他のクラウドサービスのMySQL互換サービスとも遜色なくなった。
DatastoreやSpannerで謳っているようなスケーラビリティのメリットなどは得られないので、これを使うためにGCPを選択する必要は今のところないが、運用案件の一部の機能を任せることはある。
2017年12月現在ではMySQL5.6とMySQL5.7が使用できる。(PostgreSQLがベータ版で使用できるようになったようだ)
Cloud Spanner
フルマネージドにスケール可能なRDBMSとして使えるサービス。
詳細は後述するがパフォーマンスを発揮するための設計上の制約があり、既存のRDBMSからの移行はそんなに簡単ではない。
実際にはRDBMSっぽく扱えるNoSQLと考えると色々しっくりくる。
「ノードを増やせば増やすほど捌けるクエリの上限が上がる、ノード間の負荷分散は勝手にやってくれる」というのはBigtableとも共通する。Bigtableの構成を知っておくとSpannerの挙動についても納得いくことが多いので、公式のCloud Bigtable のアーキテクチャとか読んでおくのがオススメ。
Datastoreと同じようにBigtable上に構築されたものなのか、それともBigtableに似たアーキテクチャではあるが専用に作られたものなのかは良く知らない。
値段はBigtableよりさらにお高い(使用目的が異なるため単純な比較はできないですが)
他だと出来ることがSpannerではまだ出来ないなどはあるが、最近だとDataflowからの書き込みもサポートされるなど、徐々に使いやすくなっていくと思う。
Firebase
いわゆるmBaaS。Googleが買収しGCPの一部という扱いになっているため、一応軽く触れておく。
FirebaseにはCloud FirestoreとRealtime Database2種類のデータベースがあるが、いずれもクライアント側から直接アクセスでき、リアルタイム反映とオフライン対応で容易に使えるのが特徴。
前者は10月にベータ公開されたばかりのプロダクト。バックエンドが前述のDatastoreであり、Datastoreの安定性や拡張性がより手軽に享受できる(一部機能が省かれている部分はある)。
後者は以前からのプロダクト。リアルタイム反映の速さと仕様が多少よりシンプルであることは前者より勝る。お高め。
(Yatimaさんに追記していただきました)
これらのGCPデータベースサービス(CloudSQLは除く)全体的に言えることとしては、局所的な性能を得ることに関してはそれほどでもない(悪いというわけではない)が、運用案件の規模が大きくなった時にも初期の性能をしっかり担保できるということ。
これが最大の魅力だと思うので、このメリットを活かせるならばGCPを選択する理由になる。
また、Datastoreではノード数の増減はフルマネージドだが、BigtableとSpannerでは直接操作する必要があるので自動化したい場合は自前で構築しなければならない。
それではここから先が本題になります。
Spannerのノードとシャーディング
Spannerのノードはテーブルデータの実体を持たず、主キーでシャーディングされたデータのかたまりに対してのポインタを持ちクエリの処理を行う。物理的なデータのかたまりに対してノードをどのように割り当てるかは自動で最適化してくれる上に、その変更は一瞬でパフォーマンスにほとんど影響を与えない。
しかしノードに対しての最適化を本当に最適にしてもらうためにはSpanner特有の制約事項を守る必要がある。それが主キーの分散とインターリーブで、それはこの後詳細を説明する。
- ノードとシャーディングの挙動において参考になるBigtableのアーキテクチャ
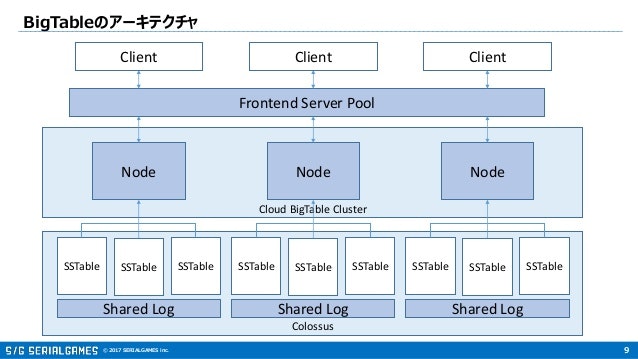
(先にあげた公式のCloud Bigtable のアーキテクチャも参考にしてほしい)
Spannerではノードを増やすとパフォーマンスの上限(クエリを処理できる上限)が上がる。これは本当に線形に上がる。理論的には無限に上がると言われたりもしているが、実際にどのあたりで限界が見えてくるのかは分からない。そのあたりは実案件での運用を検討する際に想定負荷でしっかり試してみてほしい。
気をつけたいところは、ノードを増やしても最適化は少し遅れること。(これは想像だが)流れてくるクエリを分析してノードの最適化を行うので、30分から最大1時間くらいはノードの増設の効果が出るまでラグがある。
なのでスパイクの激しいサービスのそのスパイクを捌くのには向いていないのではないかと考えている。
(ちょっとこれは語弊があるかもしれない。新規ユーザが瞬間的に大量に作られるようなサービスは、と言うべきかも。仮に捌きたいデータの主キーがすでに作られており十分分散されているなら問題ない)
Spannerでの設計上の要点
ここから先は設計上の気をつけるべきことを挙げていく
auto increment はNG
auto_incrementやシリアル型に相当するものがない。
アプリケーション側で実装することはもちろん可能だが、auto_incrementの主キーをつけるのはSpannerでは最もやってはいけないこと。
Spannerでは主キーに単調増加 or 単調減少する値を使うとHotSpotが発生する。
HotSpotとは、あるテーブルの処理が特定のノードに集中してしまうことで、この状態が発生するとパフォーマンスの劣化がおきる。主キーをその型の取りうる範囲で分散させておかないとデータも分散されない。
試しに、性能試験でauto_incrementのキーで実装してみたが、ノード数を1から5に増やした場合に性能の上昇が全くなかった。
次に無作為(かつもちろんユニーク)なキーで実装してみたところ、ノード数を1から5にすると性能も5倍になった。
前者はまさにHotSpotが発生していて、1台のノードに処理が集中していたということになる。
「その型の取りうる範囲で最大限分散させる」というのは結構難しいような気がするが、例えばUUIDを使うことは推奨されている。またINT64であれば最上位からの何ビットかを分散させておくことで目立ったHotSpotは発生しないことを確認できている。
インターリーブ
見た目上は外部キー制約のようなものだが、Spannerでは親子関係にあるテーブルを物理的にまとめるための指定。
インターリーブする際には子テーブルにおいて親キーを部分キーとする必要がある。
基本的にあらゆるクエリやレコードはノードの数だけ分散処理されるのだが、インターリーブしておくと物理的に同じ場所(SStable)にまとめて格納・アクセスされるので、全体としてのパフォーマンスが向上する。
つまり1人のユーザのアクションとして実行されるトランザクション処理を、1台のノードで完結できることになる。
インターリーブは「挟み込む」と言う意味の言葉だが、まさに親テーブルの主キーの間に子テーブルを挟み込んでいるということになる。
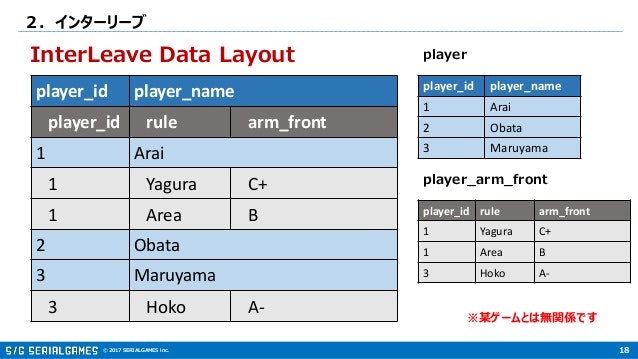
実際のところは、インターリーブにより性能が向上するというよりはアクセス頻度の高いデータは全てインターリーブしておかないと十分性能が出ない。
つまりSpannerを使う上ではインターリーブはほぼ必須なもの
「ほぼ」と書いたのは、アクセス頻度が低いデータも含めてすべてをインターリーブすると逆に重くなる(らしい)ということ。
これ関してはまさにいま知見を集めている段階だが、「ユーザ毎」というよりは「一度にアクセスしたい単位毎」にインターリーブすると考えると良いのかもしれない
- 親キーをまたがる処理
複数の親キーにまたがる処理、例えば2ユーザ間の操作した場合は最大2台のノードでの処理になるが頻繁でなければ特に重いとかは感じない。この処理だけで見るとSpannerに対して通常の2倍のアクセス負荷になっている可能性はある。
- 多段インターリーブ
最大6段まで多段インターリーブが可能だが、性能面でどれほどの効果があるのかちょっと分からない。
- インターリーブの削除
インターリーブされた子テーブルのインターリーブを外すことはできない。
これは結構落とし穴になるかもしれないので注意。
- インターリーブ指定の方法
CREATE TABLE player (
player_id INT64 NOT NULL,
player_name STRING(64),
player_info BYTES(MAX),
player_comment STRING(1024)
) PRIMARY KEY (player_id);
CREATE TABLE player_udemae (
player_id INT64 NOT NULL,
match_rule INT64 NOT NULL,
udemae INT64
) PRIMARY KEY (player_id, match_rule),
INTERLEAVE IN PARENT player ON DELETE CASCADE;
このように指定する。
サロゲートキーは使えない
上記のauto_incrementとインターリーブの設計上の制約により、サロゲートキーは使えなくなる。
個人的には状況によっては使ってもいいよ派だが、Spannerでは議論の余地なく使えない。
indexはカバリングindex
Spannerではindexを使用しないアクセスもできることになってはいるが、パフォーマンスは非常に悪くなる。
そのため本項では(本記事全体でも)indexアクセスのみ使用する前提としている。
- セカンダリindex
Spannerではセカンダリindexをつけることは普通に可能だが、indexキーと主キーしか参照できない。
つまり、いわゆるカバリングindexとしてのアクセスしかできない。
- STORING index
セカンダリindexでindexキーまたは主キー以外の列を参照する方法としてSTORING indexという方法がある。公式ドキュメントにはこの手段はパフォーマンスとトレードオフと書いている。
そもそもセカンダリindexではインターリーブを活用したアクセスにならないので、積極的に使うことはオススメできない。
しかしどうしてもという場合はもちろんあり、実際に局所的に使うぶんには問題がない。その場合でも可能であればindexキーを分散させたい。
- STORING index指定の方法
CREATE TABLE player (
player_id INT64 NOT NULL,
player_name STRING(64),
player_info BYTES(MAX),
player_comment STRING(1024)
) PRIMARY KEY (player_id);
CREATE INDEX storing ON player (
player_name
) STORING (
player_info,
player_comment
)
これはplayer_nameでユーザの情報を検索したいような場合で、あんまり推奨できない例ではある
すみません。。力尽きたのでこの後の内容は後日ちゃんと書きます。
トランザクションは冪等に
トランザクションでは冪等性を担保しないといけない的な事
カラム追加の制約
カラム追加が一瞬だがNOT NULL制約がつけられないので、そこに頼った設計ができないこと。
あとそれならいっそ全面的に最初からNOT NULL禁止というルールを考えていること。
その他の注意点
集計・分析をやりたい場合
BigQueryを使いましょう的な事
フェイルオーバー
自動でやってくれるがリカバリ手段が現状用意されていない事
まとめ
まとめ的な内容