開発者およびシステム設計者のMichael Wittigは、Cloudonoutブログで、AWS(Amazon Web Services)を使用する際の最も一般的な誤りに関する興味深い記事を投稿しました。 この記事の要点をご紹介します。
WittigはAWSコンサルタントとして働いており、サイズに関係なく多くのシステムを見てきたそうです。ほとんどの場合、これらは標準のウェブアプリケーションです。 彼は、避けるべき5つの最も一般的な間違いのリストを紹介しました。
典型的なWebアプリケーション
標準のWebアプリケーションは次のものが含まれています。
- ロードバランサー
- スケーラブルなサーバーサイド(ウェブバックエンド)
- ストレージ
図では、次のようになります。
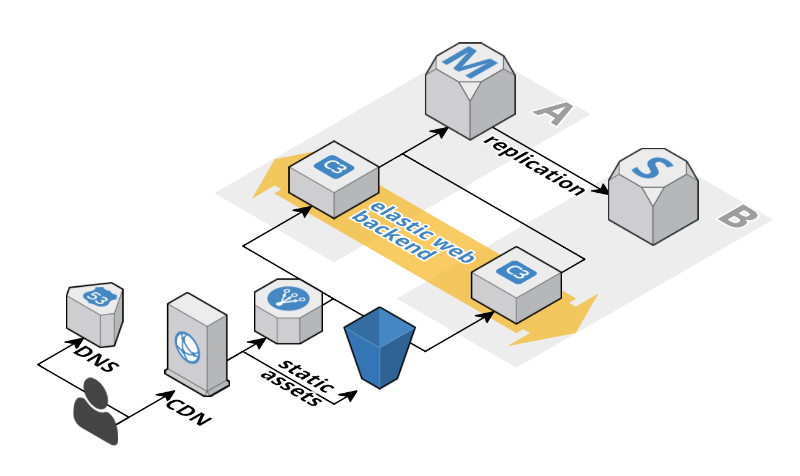
これは一般的なパターンです。 他の方法を使用してアプリケーションを設計する正当な理由がなければなりません。
間違い1.インフラストラクチャを手動で管理すること
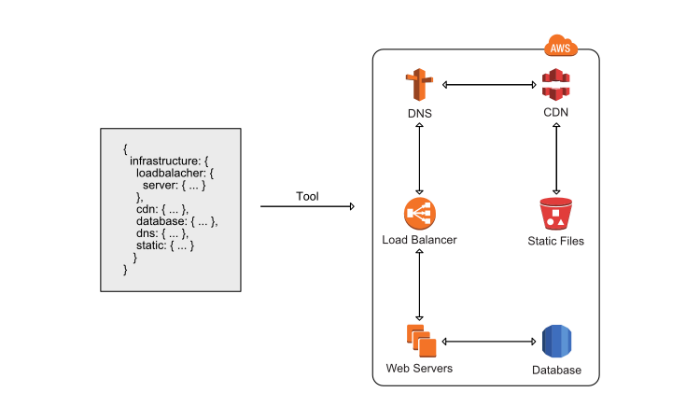
コンソールを使用してAWSのリソースが作られているということは、インフラストラクチャが手動で管理されているということです。この制御オプションの主な問題は、リソースの設定は再現できず、どこにも登録されていないことです。その結果、多くのエラーが発生する可能性があります。幸いなことに、この問題を無料で解決できるAWS CloudFormationがあります。
リソース(EC2インスタンス、セキュリティグループ、サブネット)を手動で作成する代わりに、テンプレートでリソースを記述したり、独自に作成したり、既製のものを使用したりできます。 CloudFormationは、それらを現在のスタックに統合する方法を処理します。図の通り、このサービスが正しい順番にリソースを作成してくれます。
間違い2. Auto Scalingグループを使用しないこと
一部の人は、特別な機能に頼らずに自分でリソースを拡張できると信じています。もちろん、それは大間違いです。各EC2インスタンスはAuto Scaling Groupで実行される必要があります。独自のインスタンスであっても。 Auto Scaling Groupは、必要な数のインスタンスの起動を制御します。実際、仮想マシンの論理グループのように動作します。この機能は無料で使用できます。
標準のWebアプリケーションでは、サーバーはAuto Scaling Group内の仮想マシンの中に起動されます。負荷に基づいてコンピューティングリソースの量を増加または減少させることができます。アドミニストレーターは、自動スケーリングを開始する条件を指定できます。これは例えば、論理グループのCPUパフォーマンスのしきい値または負荷分散のためのリクエストの数です。
間違い3. Amazon Cloud Watchの分析を怠ること
AWSサービスに関する必然的なデータは、Cloud Watchから取得できます。 仮想マシンは、プロセッサの負荷、ネットワーク、ディスク操作について通知します。 ストレージは、メモリ使用量とI/O操作の数に関する情報を提供します。 これらの統計を正しく使用するのはあなたです。 一日のCPU使用率のメトリックスを見てみましょう。
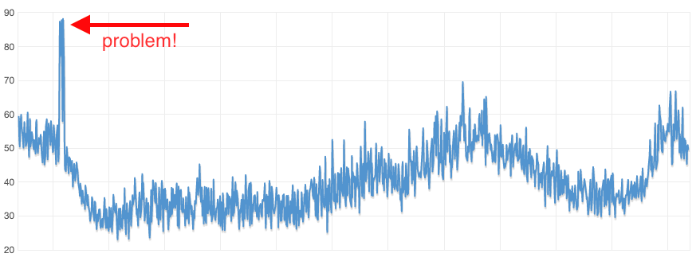
ピークをご覧ください。Wittigは、この飛躍が毎日同じ時間に発生していると確信していました。
タスクスケジューラが悪さしているように見えます。 やっぱりそうですね。 このマシンからWebサーバーが起動されたということはスケジューラにより毎日待機時間が増加していたということです。 別の仮想マシンでスケジューラを起動すると、問題は解決するはずです。情報はすべてCloudWatchにありますが、あなたはそれを見る必要があります!
メトリックを分析した後のステップは、メトリックのアラームを定義することです。 その逆ではダメです!
間違い4.Trusted Advisorを無視すること
Trusted Advisorツールは、AWS環境がサービスを操作するベストプラクティスに準拠しているかどうかを確認します。 チェックされるのは:
- コストの最適化
- パフォーマンス
- 安全性
- 耐障害性。
Trusted Advisor管理コンソールが次のようになっている場合:
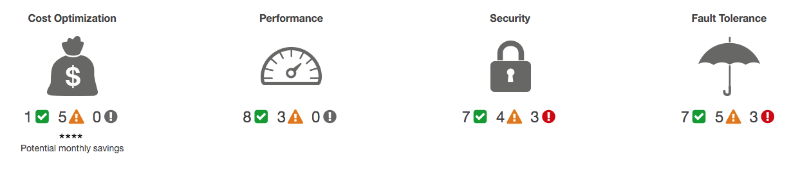
Wittig氏によると、環境内のプロセスの最適化を開始すべきです。
まず、セキュリティに十分注意をした方がいいです。 毎週のフィードバック機能を使うと、Trusted Advisorは現在および解決済みのすべての問題について報告してくれます。 無料版と有料版があります。 有料版により検証の機能がさらに広がります。
間違い5.仮想マシンの効率を管理しないこと
EC2インスタンスが十分に活用していないことに気付いた場合、インスタンスのサイズ(マシンの数またはc3.xlargeからc3.largeへ)を縮小しないようにする理由はありません。手動で管理されているインフラストラクチャなら話は別ですが。
十分に活用していないというのをどうすればわかると? CloudWatchのメトリックスを確認してください! とても簡単です。
Auto Scalingグループを使用している場合は、スケーリングする前にオートスケーリングルールとCloudWatchメトリックスを確認した方が良いです。
おまけ
今度インフラストラクチャを確認するのはあなたの番です。