SQLのパフォーマンスチューニングで考えるべきことの一つに、インデックスがある。インデックス無しで作業をしてみて、インデックスの重要性を理解しましょう。
ディスクからのデータの読み込み
ディスク上ではファイルという概念はない。ブロックという概念がある。普段なら一つのファイルがいくつかのブロックを使用している。ブロックの順位が決まっていて、ファイルが分割された後に各部分がそれぞれのブロックに保存されます。
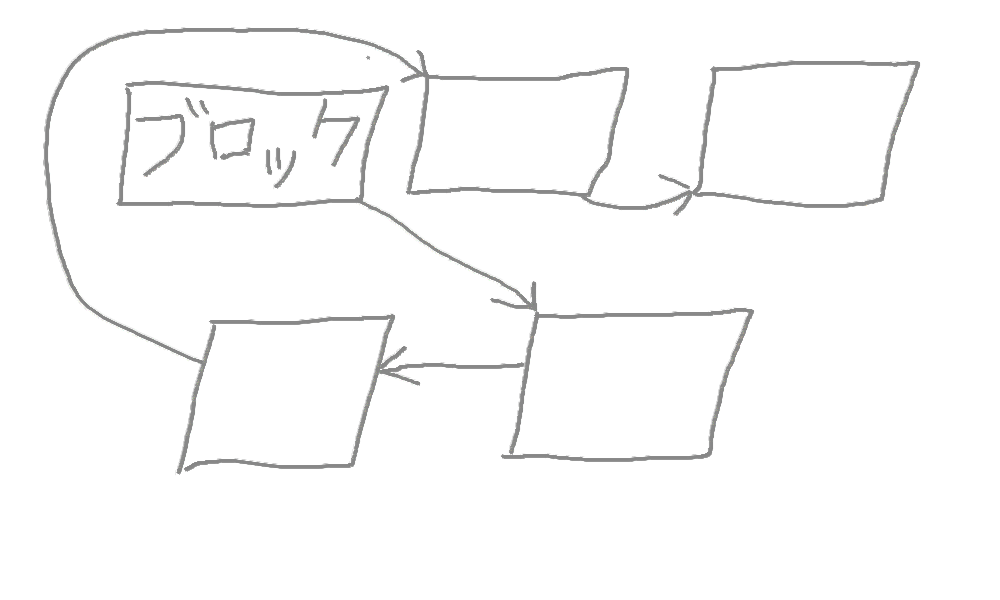
ファイルを読み込んでる時に、各ブロックのデータを取得して組み立てる。フラグメンテーションによってそのブロックがディスクの色んな位置に置いてある可能性があるので、それによって読み込みが遅くなりかねない。
ファイルの中で何かを探している時に、全てのブロックからデータを取得する必要が出てくる。ファイルが大きければ大きいほどブロックの数が増えて検索がすごく遅くなる。
MySQLでのデータ検索
MySQLのテーブルはファイルである。次のクエリーを実行してみよう:
SELECT * FROM users WHERE age = 29
実行の結果としてMySQLがusersのデータを持っているファイルを開き、必要なレコードを探す。
しかも、クエリーの値をテーブルの各行の値と比較する。例えば、テーブルに10個のレコードがあったら、MySQLがその10個全てを読み込み、各レコードのageの値をクエリーの値と比較して、該当な値だけを返す。
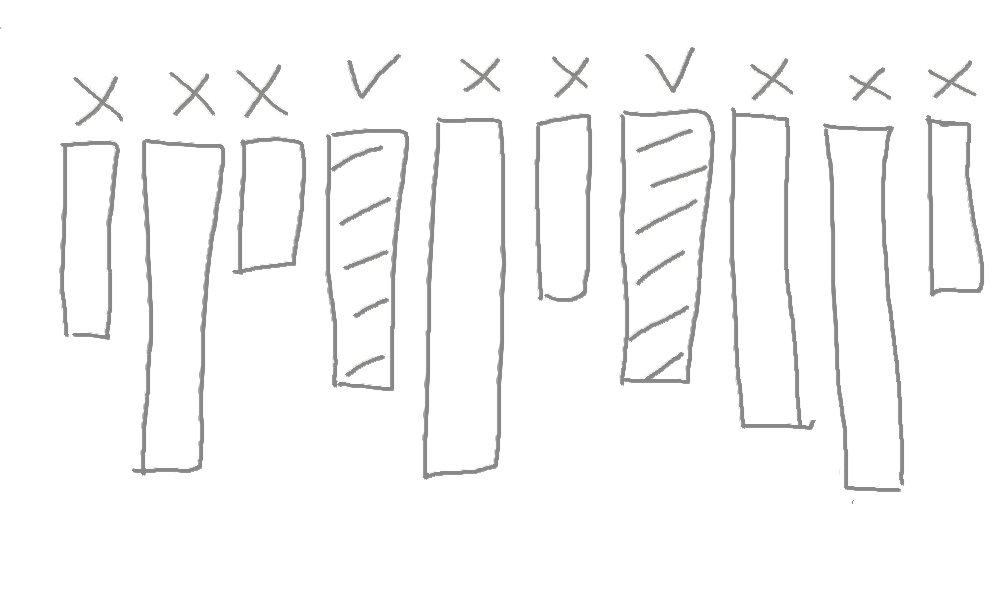
- ブロックがディスクのそれぞれの部分(フラグメンテーション)にあるため読み込みが遅い。
- 比較の数が多い
データのソート
例えばさっきの10個のレコードが降順でソートされていたら二分探索を使って4つのオペレーションで必要な値を取得できた。
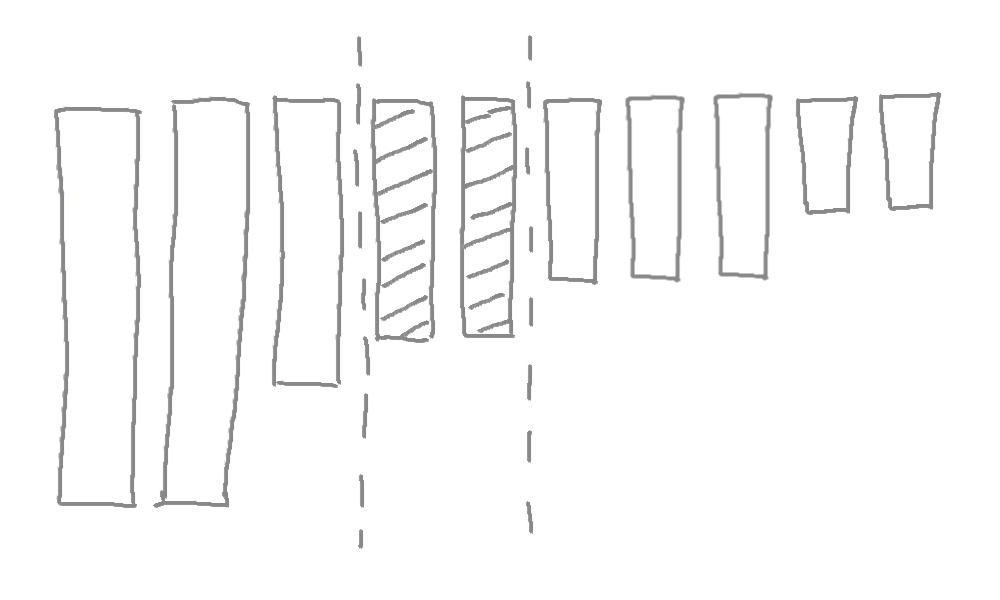
レコードがソートされていたら、比較の回数が減るだけではなく、読み込み自体の数が少なくなる。
ソートされたレコードのセットがインデックスである。MySQLではインデックスをカラムに対して作る。さっきの例だと、ageに対してインデックスを作った方が良かった。
インデックスを作る時の考え方
一番シンプルなのはWHEREに入っているカラムに対してインデックスを作る事。
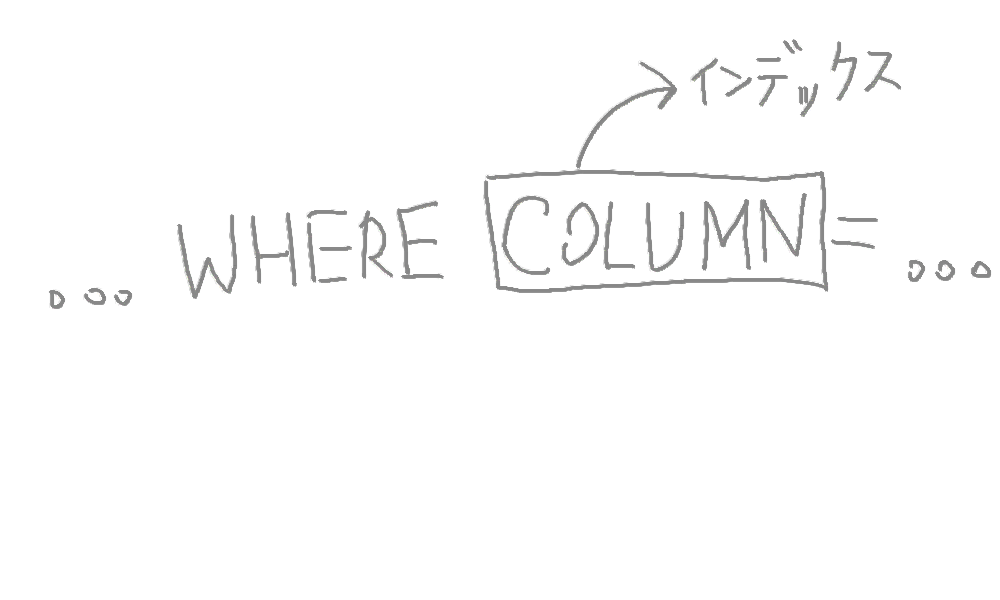
例えば、次のクエリーを見てみよう
SELECT * FROM users WHERE age = 29
ageに対してインデックスを作る
CREATE INDEX age ON users(age);
そうすると、上記のクエリーが実行されたら、MySQLがさっき作成されたインデックスを使い始める。
=だけではなくて、<>にもインデックスが使われる。
SELECT * FROM users WHERE age < 29
ソート
ソートも一緒で
SELECT * FROM users ORDER BY register_date
こういうクエリーがあったら、ソートされるカラムに対してインデックスを作成する
CREATE INDEX register_date ON users(register_date);
インデックスの構造
例えばこういうテーブルがあって:
| id | name | age |
|---|---|---|
| 1 | Tanaka | 29 |
| 2 | Sato | 15 |
| 3 | Suzuki | 89 |
| 4 | John | 12 |
ageに対してインデックスが作られた後、MySQLがそのカラムの全ての値をソートして保存する。
age index
12
15
29
89
それに、レコードとの関連性も守られる。普段はそのためにPrimary Keyが使われる。
ageのindexとレコードの関連性
12: 4
15: 2
29: 1
89: 3
ユニークなインデックス
MySQLではユニークなインデックスを作ることが可能。カラムの値がそれぞれ違う時に便利、こういうインデックスによってサンプリングパフォーマンスが向上する。
SELECT * FROM users WHERE email = 'tanaka@example.com';
emailのカラムに対してユニークなインデックスを作る
CREATE UNIQUE INDEX email ON users(email)
そうすると検索の時にMySQLが該当な値を見つけたら検索を停止する。普通のインデックスの場合、もう1つのチェックが実行される(インデックスの次の値)。
複合インデックス
一つのテーブルに対して一つのインデックスしか使えない(例外はある)ので複数のカラムを使って検索する時に複合インデックスを使う。
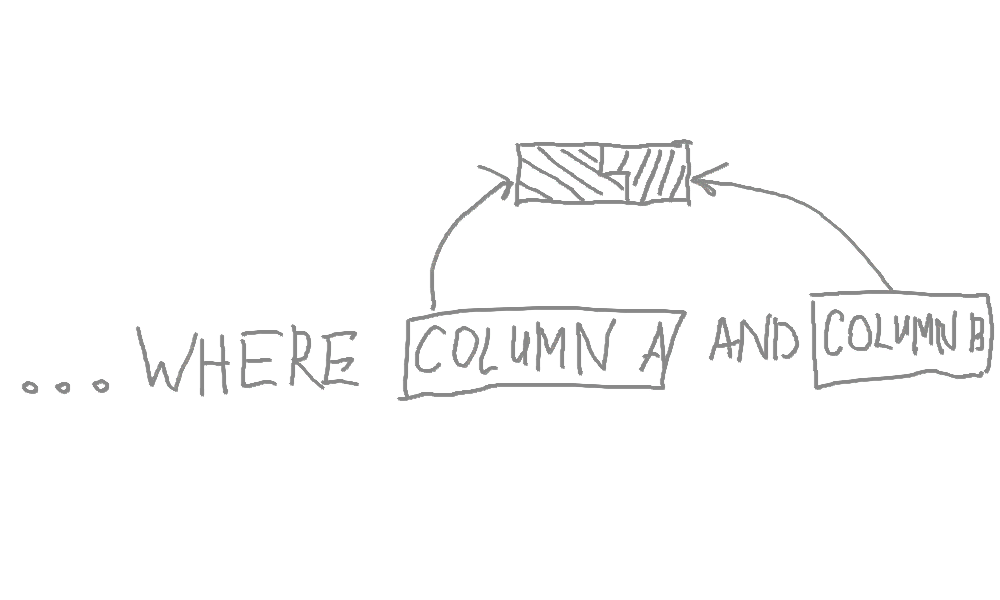
例えばこういうクエリー
SELECT * FROM users WHERE age = 29 AND gender = 'male'
二つのカラムに対しての複合インデックスを作る
CREATE INDEX age_gender ON users(age, gender);
複合インデックスの構造
複合インデックスを正しく使うにはまず構造を理解する必要がある。普通のインデックスに似ているが、値として全てのカラムの値を使っている。
こういうデータなら
| id | name | age | gender |
|---|---|---|---|
| 1 | Tanaka | 29 | male |
| 2 | Sato | 15 | female |
| 3 | Suzuki | 89 | female |
| 4 | John | 12 | male |
インデックスの値がこうなる
age_gender
12male
15female
29male
89female
ということは順番がとても大事。普段はWHEREに使うカラムがインデックスの先、ORDER BYのカラムが後ろにつける。
範囲検索
例えば実行しているクエリーの中で比較ではなくて範囲検索をするとしたら
SELECT * FROM users WHERE age <= 29 AND gender = 'male'
MySQLがインデックスの部分しか使えない。なぜならgenderがそれぞれのレコードで違うため。この場合、MySQLがageの部分だけを使って検索を行う
age_gender
12male
15female
29male
89tsar
つまりまずは age <= 29の条件を満たしているデータが残されて、次は gender='male'の条件でインデックスを使わずに検索を行う。
ソート
ソートの時でもインデックスを使える。
SELECT * FROM users WHERE gender = 'male' ORDER BY age
この場合はソートがフィルタリングの後に行われるため、インデックスを逆順で作った方がいい。
CREATE INDEX gender_age ON users(gender, age);
この順だとインデックスのgenderの部分でフィルタリングをしてageの部分でソートをする。必要に応じてカラムを増やすのも可能。
例えば:
SELECT * FROM users WHERE gender = 'male' AND country = 'JP' ORDER BY age, register_time
この場合は次のインデックスがよく合う:
CREATE INDEX gender_country_age_register ON users(gender, country, age, register_time);
EXPLAINでインデックスを分析する
EXPLAINステートメントは、特定のクエリのインデックス使用状況データを表示する
mysql> EXPLAIN SELECT * FROM users WHERE email = 'tanaka@example.com';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 336 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
keyカラムには、使用されているインデックスが表示される。 possible_keysカラムには、このクエリに使用可能なインデックスが表示される。rowsカラムには、このクエリを実行するためにデータベースが読み取ったレコードの数が表示される(テーブルには合計336レコードがある)。この例ではインデックスが使われていない。インデックスを作ってみよう:
mysql> EXPLAIN SELECT * FROM users WHERE email = 'tanaka@example.com';
+----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+
| 1 | SIMPLE | users | const | email | email | 386 | const | 1 | |
+----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+
インデックスが使用されているため、読み取られたのは一つのレコードだけ。
複合インデックスの長さの確認
Explainはインデックスが正しく使われているか教えてくれる。
mysql> EXPLAIN SELECT * FROM users WHERE age = 29 AND gender = 'male';
+----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+
| 1 | SIMPLE | users | ref | age_gender | age_gender | 24 | const,const | 1 | Using where |
+----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+
key_lenの値は使用されているインデックスの長さを示している。今回の長さは24バイト(ageが5バイトとgenderが19バイト)
検索条件を変えるとこのインデックスが正しく設定されていないのが明確になる。
mysql> EXPLAIN SELECT * FROM users WHERE age <= 29 AND gender = 'male';
+----+-------------+--------+------+---------------+------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------------+---------+------+------+-------------+
| 1 | SIMPLE | users | ref | age_gender | age_gender | 5 | | 82 | Using where |
+----+-------------+--------+------+---------------+------------+---------+------+------+-------------+
key_lenが5になってるからこのインデックスを作り直した方がいい。順番を変えると:
mysql> Create index gender_age on users(gender, age);
mysql> EXPLAIN SELECT * FROM users WHERE age < 29 and gender = 'male';
+----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+
| 1 | SIMPLE | users | range | age_gender,gender_age | gender_age | 24 | NULL | 47 | Using where |
+----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+
今回は正しい順番のおかげでインデックスが全体的に使用される。
インデックスの選択性
前のクエリーに戻ってみよう:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
このようなクエリの場合、複合インデックスを作成する必要がある。 しかし、インデックスのカラムの順番をどうやって決める? オプションは二つある:
- age, gender
- gender, age
どっちもいける。しかし、それらは異なる効率で動作する。それを理解するには、値ごとのレコードの数を見てみよう:
mysql> select age, count(*) from users group by age;
+------+----------+
| age | count(*) |
+------+----------+
| 15 | 160 |
| 16 | 250 |
| ... |
| 76 | 210 |
| 85 | 230 |
+------+----------+
68 rows in set (0.00 sec)
mysql> select gender, count(*) from users group by gender;
+--------+----------+
| gender | count(*) |
+--------+----------+
| female | 8740 |
| male | 4500 |
+--------+----------+
2 rows in set (0.00 sec)
この情報から次のことがわかる:
- ageカラムの各値に約200レコードが該当する
- genderカラムの各値に約6000レコードが該当する
ageをインデックスの先頭に入れるとこの部分が処理されると約200レコードが残る。そして先頭はageじゃなくてgenderだったら残るのは約6000レコード。つまり ageの場合よりも一桁大きい。ということはgender_ageよりage_genderのインデックスの方が効率が高い。
そして、age, genderの複合キーが有るときには、age単体で検索したいときにも使ってくれるので、ageのキーを後から追加する必要はないけど、gender だけで検索したいときには使えないので必要に応じてgenderのキーを追加する必要がある。
カラムの選択性は、同じ値を持っているレコードの数によって決まる。 同じ値を持つレコードが少ない場合、選択性は高くなる。 このようなカラムは、複合インデックスで先頭に入れる必要がある。
Primary Key(PK)
主キーは特殊なインデックスで、テーブルのレコードの識別子。 必ず一意であり、テーブルを作成するときに設定される。
CREATE TABLE `users` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`email` varchar(128) NOT NULL,
`name` varchar(128) NOT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
InnoDBの場合は必ずPKを設定してください。MySQLはPKが定義されていなくても勝手にバーチャルキーを作ってくれる。
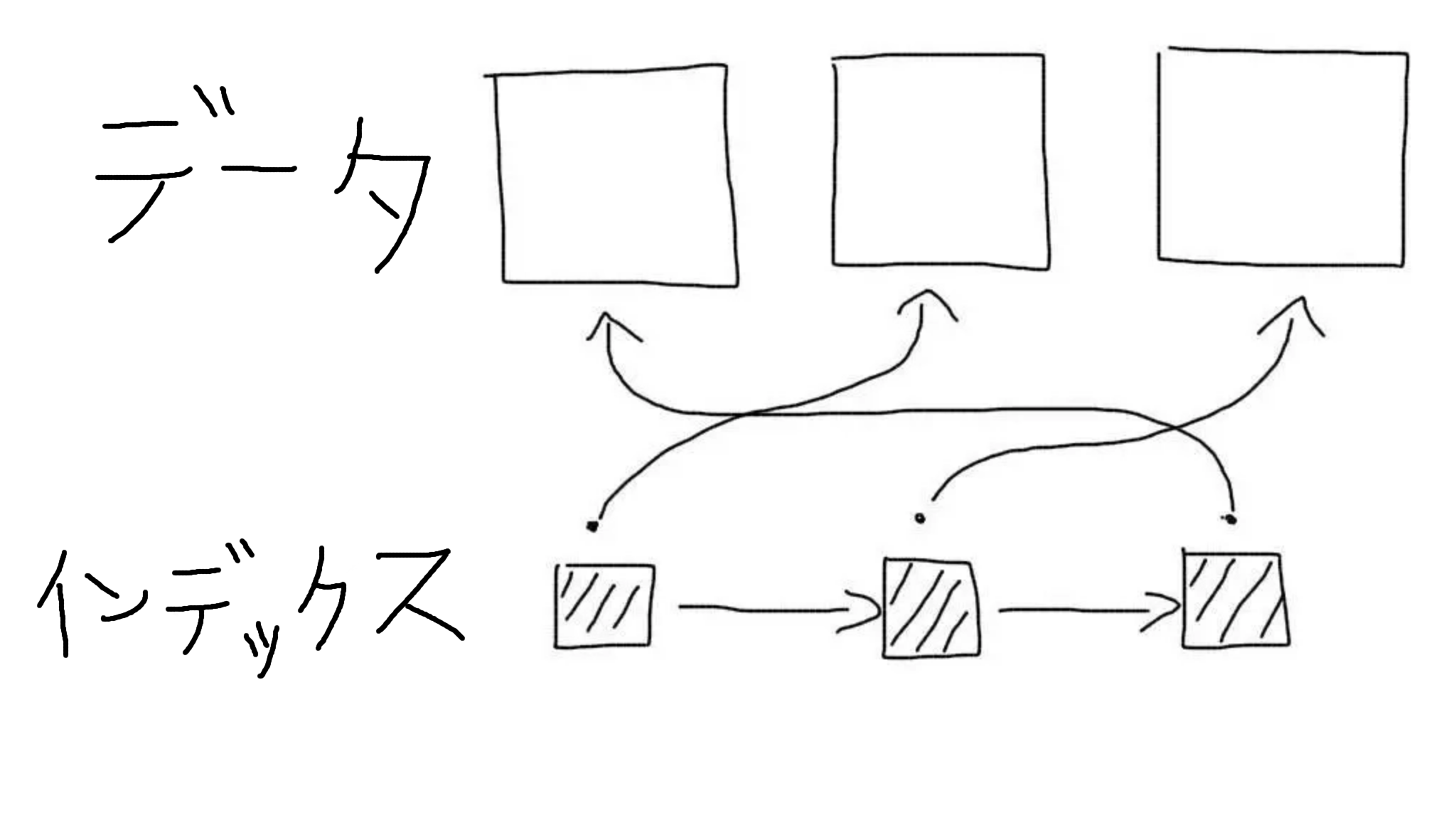
クラスターインデックス
通常のインデックスはクラスタ化されていない。つまりインデックス自体がレコードへの参照リンクしか持たないということ。インデックスを操作する場合、クエリに一致するレコードのリスト(より正確には、主キーのリスト)のみが決定される。 その後、別のクエリが発生して、このリストから各レコードのデータを取得する。
クラスターインデックスは、レコードへのリンクではなく、レコードのデータ全体を格納している。このようなインデックスを使用する場合、追加のデータ読み取り操作は必要ない。
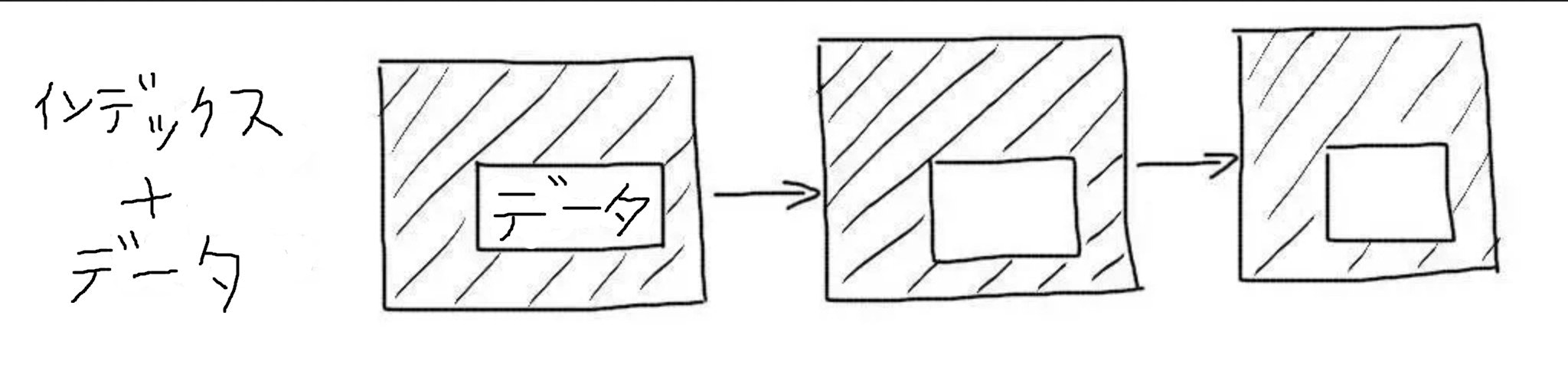
InnoDBではPKがクラスター化されているため検索効率がとても高い。
Overhead
インデックスを使用する際にディスクへの書き込み操作が増えることを忘れてはならない。テーブルのデータを追加又は編集をするたびにインデックスのデータも変更される。
- リソースを無駄にしないように、必要なインデックスだけを作成すること。
- インデックスサイズを制御すること。
インデックスを作成するタイミング
- 遅いクエリーが発見された時。発見するにはMySQLのslow logが便利。1秒以上かかっているクエリーがあったら、それのオプティマイズを検討すること。
- 一番よく実行されるクエリーにはインデックスが最も相応しい。1日に1000回実行される1秒のクエリーは、1日に数回実行される10秒のクエリよりも大きなダメージを与える。
- 数千レコード未満のテーブルにインデックスを作成しないこと。もし目的がパフォーマンスの強化だったらそのようなサイズのテーブルはインデックス使うメリットはほとんどない。
- 事前にインデックスを作らないこと(例えばDEV環境)。インデックスは本番の負荷に合わせて作成するべき。
- 使用されていないインデックスを削除すること。
一番重要なこと(おまけ)
- MySQL(および他のデータベース)のインデックスを分析および整理するのに十分な時間を確保してください。
- 本番に似たような環境を用意して、そこで色んなインデックスを試すのもいいかもしれない。
- 場合によってユニークなインデックスを作った方がいい。
- PKを設定するのを忘れないこと。
以上