背景
日本アミノ酸学会第15回学術大会にて自然言語処理を応用した発表をおこないました。内容は日本「アミノ酸学会の要旨(約30年の要旨約900報)をPython使って分類してみたら、学会の発表内容の変遷が分かってきたよ」というものです。これほど多量かつ専門用語が盛りだくさんのコーパスで自然言語処理することはとっても稀有な体験なので私も勉強になりました。学会に参加した方がコードを見たいということなので紹介させていただきます。詳細データをお示しすることができないため、学会に参加していない方は意味不明な記事になってしまうことをご了承ください。
作業環境
windows10のpython3.7.1です。
全体の流れ
以下のような順序で作業を実施したのですが、今回は一番の肝になる後半の「研究要旨の高次元ベクトル化、次元削減とクラスタリング」の部分をご紹介します。大部分はQiitaのSCDV法に関する記事を参考にさせていただきました。その他の部分は別途ご紹介予定です。
研究要旨(PDFデータ)のテキスト化⇒
MeCabのインストールと専門用語の辞書登録⇒
研究要旨の高次元ベクトル化⇒
次元削減とクラスタリング⇒
各クラスターの特徴となる単語の図示化(Wordcloud)
使用データ
要旨のタイトルが”title”、解析する研究要旨が”abstract”、出版年数が”category”に記載されている以下の画像のようなExcelファイルを使用しました(著作権を考慮してぼやかして見えないようにしています)。このデータが約900行続いています。
コード紹介
使用モジュール
何かいらないやつがあったりしたらごめんなさい。
from gensim.models import Word2Vec
from gensim import models
import pandas as pd
import re
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn import datasets, manifold, mixture, model_selection
from sklearn.cluster import DBSCAN
import hashlib
import MeCab
ストップワード
自然言語処理をするときに考慮に入れない単語の一覧です。一つ目のstop_word1はSlothLibからお借りしましたが、それ以外にも要旨の特質として特殊文字等が引っかかってきたので、stop_word2として追加で登録しました。背景とか序論とか、研究要旨に高頻度ではいってくるものの、それ自体が分類分けに寄与しないであろうものはストップワードとして登録しました。多すぎて重複とかしてたら嫌だったのでリストを一回set型に変換して再度list型に戻しています。
stop_word1 = ['あそこ', 'あたり', 'あちら', 'あっち', 'あと', 'あな', 'あなた', 'あれ', 'いくつ', 'いつ', 'いま', 'いや', 'いろいろ',
'うち', 'おおまか', 'おまえ', 'おれ', 'がい', 'かく', 'かたち', 'かやの', 'から', 'がら', 'きた', 'くせ', 'ここ', 'こっち', 'こと', 'ごと',
'こちら', 'ごっちゃ', 'これ', 'これら', 'ごろ', 'さまざま', 'さらい', 'さん', 'しかた', 'しよう', 'すか', 'ずつ', 'すね', 'すべて', 'ぜんぶ',
'そう', 'そこ', 'そちら', 'そっち', 'そで', 'それ', 'それぞれ', 'それなり', 'たくさん', 'たち', 'たび', 'ため', 'だめ', 'ちゃ', 'ちゃん',
'てん', 'とおり', 'とき', 'どこ', 'どこか', 'ところ', 'どちら', 'どっか', 'どっち', 'どれ', 'なか', 'なかば', 'なに', 'など', 'なん', 'はじめ',
'はず', 'はるか', 'ひと', 'ひとつ', 'ふく', 'ぶり', 'べつ', 'へん', 'ぺん', 'ほう', 'ほか', 'まさ', 'まし', 'まとも', 'まま', 'みたい', 'みつ',
'みなさん', 'みんな', 'もと', 'もの', 'もん', 'やつ', 'よう', 'よそ', 'わけ', 'わたし', 'ハイ',
'上', '中', '下', '字', '年', '月', '日', '時', '分', '秒', '週', '火', '水', '木', '金', '土', '国', '都', '道', '府', '県',
'市', '区', '町', '村', '各', '第', '方', '何', '的', '度', '文', '者', '性', '体', '人', '他', '今', '部', '課', '係', '外',
'類', '達', '気', '室', '口', '誰', '用', '界', '会', '首', '男', '女', '別', '話', '私', '屋', '店', '家', '場', '等', '見',
'際', '観', '段', '略', '例', '系', '論', '形', '間', '地', '員', '線', '点', '書', '品', '力', '法', '感', '作', '元', '手',
'数', '彼', '彼女', '子', '内', '楽', '喜', '怒', '哀', '輪', '頃', '化', '境', '俺', '奴', '高', '校', '婦', '伸', '紀', '誌',
'レ', '行', '列', '事', '士', '台', '集', '様', '所', '歴', '器', '名', '情', '連', '毎', '式', '簿', '回', '匹', '個', '席',
'束', '歳', '目', '通', '面', '円', '玉', '枚', '前', '後', '左', '右', '次', '先', '春', '夏', '秋', '冬', '一', '二', '三',
'四', '五', '六', '七', '八', '九', '十', '百', '千', '万', '億', '兆', '下記', '上記', '時間', '今回', '前回', '場合', '一つ',
'年生', '自分', 'ヶ所', 'ヵ所', 'カ所', '箇所', 'ヶ月', 'ヵ月', 'カ月', '箇月', '名前', '本当', '確か', '時点', '全部', '関係', '近く',
'方法', '我々', '違い', '多く', '扱い', '新た', 'その後', '半ば', '結局', '様々', '以前', '以後', '以降', '未満', '以上', '以下',
'幾つ', '毎日', '自体', '向こう', '何人', '手段', '同じ', '感じ']
stop_word2 = ["(♀)","(♀),②","(♀),③","(♀),④","(♂)","(株)",")③",")。",")。②",")。②.",")。③",")。③.","))","),",
"),②","),③","),④","),⑤",")}]",",②",",③",",♂)",":①",")。","fig","table",
"背景","緒論","序論","緒言","目的","結果","考察","緒論"]
stop_word1.extend(stop_word2)
stop_words = list(set(stop_word1))
下処理
ハッシュ関数を自作してword2vecに渡さないとword2vecの再現性が得られなくなってしまうので、Twitterの記事を参考にhashfxn関数を作成してます。3行目でMeCabの出力モードを指定しています。analizer関数では名詞だけを残し、改行やら記号やら、URLやらを抜いて、さらにストップワードを削除しています。
def hashfxn(x):
return int(hashlib.md5(str(x).encode()).hexdigest(), 16)
tokenizer = MeCab.Tagger("-Ochasen")
def analyzer(text):
text = [line.split()[0] for line in tokenizer.parse(text).splitlines()
if "名詞" in line.split()[-1]]
text = ' '.join(text).replace("\u3000","")
text = text.lower() # 小文字化
text = text.replace('\n', '') # 改行削除
text = text.replace('\t', '') # タブ削除
text = re.sub(re.compile(r'[!\/:-@[-`{-~]'), ' ', text) # 記号をスペースに置き換え(ハイフンは出るようにする)
text = re.sub(r"(https?|ftp)(:\/\/[-_\.!~*\'()a-zA-Z0-9;\/?:\@&=\+\$,%#]+)", " " , text) # URLが出た場合は削除
text = text.split(' ') # スペースで区切る
words = []
for word in text:
if word in stop_words: # ストップワードに含まれるものは除外
continue
if len(word) < 2: # 1文字、0文字(空文字)は除外
continue
words.append(word)
return words
メイン処理
分けて個々に説明した方がよいのかもしれませんが、詳細は参考URLをご確認ください。
SRCHTTL = input("ファイル名を入力してください : ")
article_list = pd.read_excel(SRCHTTL + ".xlsx", encoding="utf_8_sig")
article_abst = article_list['abstract']
article_year = article_list["category"]
# word2vecのパラメータを指定
epoch_num = 20 #トレーニング反復関数
features_num = 300 # Word vector dimensionality 単語ベクトルの次元数
min_word_count = 30 # Minimum word count n回未満登場する単語を破棄
context = 10 #元は5だった # Context window size 学習に使う前後の単語数
downsampling = 1e-3 # Downsample setting for frequent words 単語を無視する頻度
num_workers = 1 # Number of threads to run in parallel 1以外では再現性がなくなる
# どのような名詞が出てきているのかをテキストとして排出し、確認できるようにしています。
sentences=[analyzer(text) for text in article_abst]
words_2=[]
for sentence in sentences:
for word in sentence:
words_2.append('"'+ word+'"')
tenp_words_2=sorted(set(words_2))
f=open("words.txt","w")
f.write(",".join(tenp_words_2))
f.close()
# ここでWord2vecで単語ベクトルの作成
word2vecs = Word2Vec(
sentences=sentences, workers=num_workers,iter=epoch_num, size=features_num,
min_count=min_word_count, window=context, sample=downsampling, seed=42,hashfxn=hashfxn
)
avg_word2vec = np.array([word2vecs.wv[list(analyzer(text) & word2vecs.wv.vocab.keys())].mean(axis=0) for text in article_abst])
model_name = str(features_num) + "features_" + str(min_word_count) + "minwords_" + str(context) + "context_word2vec_model"
word2vecs.save(model_name)
# tf-idf値の算出
tfidf_vectorizer = TfidfVectorizer(analyzer=analyzer, min_df=min_word_count)
tfidfs = tfidf_vectorizer.fit_transform(article_abst)
tfidfs.shape
# gmmでクラスタリング
word_vectors = word2vecs.wv.vectors
clusters_num = 60
gmm = mixture.GaussianMixture(n_components=clusters_num, covariance_type='tied',random_state=42, max_iter=100)
gmm.fit(word_vectors)
# Word-topics vectorの作成
idf_dic = dict(zip(tfidf_vectorizer.get_feature_names(), tfidf_vectorizer._tfidf.idf_))
assign_dic = dict(zip(word2vecs.wv.index2word, gmm.predict(word_vectors)))
soft_assign_dic = dict(zip(word2vecs.wv.index2word, gmm.predict_proba(word_vectors)))
word_topic_vecs = {}
for word in assign_dic:
word_topic_vecs[word] = np.zeros(features_num*clusters_num, dtype=np.float32)
for i in range(0, clusters_num):
try:
word_topic_vecs[word][i*features_num:(i+1)*features_num] = word2vecs.wv[word]*soft_assign_dic[word][i]*idf_dic[word]
except:
continue
# Word-topics vector を用いた各文章ベクトルの作成
scdvs = np.zeros((len(article_abst), clusters_num*features_num), dtype=np.float32)
a_min = 0
a_max = 0
for i, text in enumerate(article_abst):
tmp = np.zeros(clusters_num*features_num, dtype=np.float32)
words = analyzer(text)
for word in words:
if word in word_topic_vecs:
tmp += word_topic_vecs[word]
norm = np.sqrt(np.sum(tmp**2))
if norm > 0:
tmp /= norm
a_min += min(tmp)
a_max += max(tmp)
scdvs[i] = tmp
p = 0.04
a_min = a_min*1.0 / len(article_abst)
a_max = a_max*1.0 / len(article_abst)
thres = (abs(a_min)+abs(a_max)) / 2
thres *= p
scdvs[abs(scdvs) < thres] = 0
scdvs.shape
# t-SNEによる次元削減
tsne_scdv = manifold.TSNE(n_components=2,random_state=42).fit_transform(scdvs)
tsne_scdv.shape
# DB scanでクラスタリング
plt.plot(tsne_scdv[:,0], tsne_scdv[:,1], ".")
dbscan = DBSCAN(eps=3.4,min_samples=6) #半径epsと円に含まれる点の最小数を指定
dbscan_tsne = dbscan.fit_predict(tsne_scdv)
color=matplotlib.cm.nipy_spectral(np.linspace(0,1,np.max(dbscan_tsne) - np.min(dbscan_tsne)+1))#色付けはクラスターの数でグラジエントがかかるようにしています。
for i in range(np.min(dbscan_tsne), np.max(dbscan_tsne)+1):
plt.plot(tsne_scdv[dbscan_tsne == i][:,0],
tsne_scdv[dbscan_tsne == i][:,1],
".",
color=color[i+1]
)
plt.text(tsne_scdv[dbscan_tsne == i][:,0][0],
tsne_scdv[dbscan_tsne == i][:,1][0],
str(i), color="black", size=16
)
plt.savefig("dbscan.png")
# 新たにExcelファイルとしてクラスタリング結果を保存
article_list['x']= tsne_scdv[:, 0]
article_list['y']= tsne_scdv[:, 1]
article_list['cluster']= dbscan_tsne
article_list.to_excel(SRCHTTL + "tsne_scdv" + ".xlsx", index = False, encoding="utf-8_sig")
結果
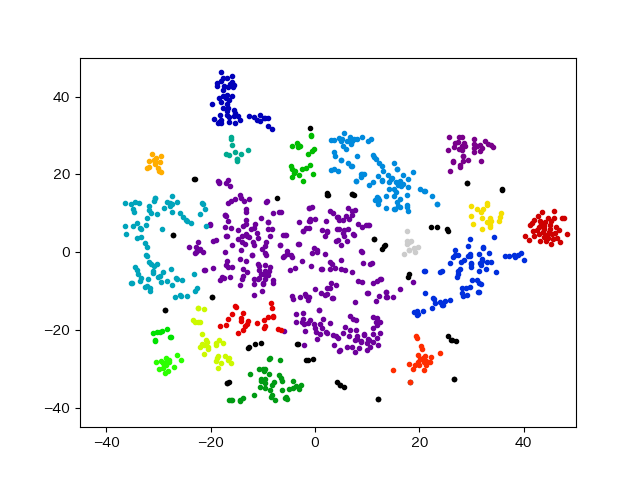
詳細は元データを出せないことから説明ができなくて大変申し訳ないのですが、以下のような形で綺麗にクラスタリングされました。
雑感
word2vec、GMM、DB-scanのパラメーターなど設定しなければならない数値が沢山あって個々に動かして調整する必要がありました。研究要旨を確認しては調整するの繰り返しで一日ぐらいデータと見比べながらパラメーターを調整していきました。データサイエンティストには”その分野の専門性”、”統計学”、”プログラミング力”が必要と言われていますが(ホント?)、私はバックグラウンドが分子生物学なので、この知識が無ければパラメーター調整は不可能だったと思います。
あとGMM(ガウス混合モデル)の部分はVBGMM(変分混合ガウス分布)でクラスタ数を推定しながらやったらどうなるのだろう?と思いました。今後の検討課題としたいと思います。
参考URL
今回のコードを作成するにあたって参考にさせていただいたURLの一覧です。以下URLの記事を執筆してくださった皆様ありがとうございました。
https://murashun.jp/blog/20190215-01.html
https://yukinoi.hatenablog.com/entry/2018/05/29/120000
https://ie110704.net/2018/10/12/%e6%96%87%e6%9b%b8%e5%88%86%e6%95%a3%e8%a1%a8%e7%8f%bescdv%e3%81%a8%e4%bb%96%e3%81%ae%e5%88%86%e6%95%a3%e8%a1%a8%e7%8f%be%e3%82%92%e6%af%94%e8%bc%83%e3%81%97%e3%81%a6%e3%81%bf%e3%81%9f/#Doc2Vec
https://onemuri.space/note/1ceozcpdt/
https://qiita.com/fufufukakaka/items/a7316273908a7c400868
http://www.ie110704.net/2018/10/12/%E6%96%87%E6%9B%B8%E5%88%86%E6%95%A3%E8%A1%A8%E7%8F%BEscdv%E3%81%A8%E4%BB%96%E3%81%AE%E5%88%86%E6%95%A3%E8%A1%A8%E7%8F%BE%E3%82%92%E6%AF%94%E8%BC%83%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F/#SCDV-2