背景
とあるテーブルへのクエリタイムアウトが突然多発したので調査したところ、変更の追跡を設定したことが関係していました。
どのような原因でタイムアウト多発に至ったのか、再発防止策としてどういったことを検討したのかについて紹介します。
調査
調査には、こちらで紹介されている、SQL Serverロギングの情報を使いました。
sys.dm_exec_requestsのダンプデータを、エラー多発時点に絞り込むと以下の結果が返ってきました。
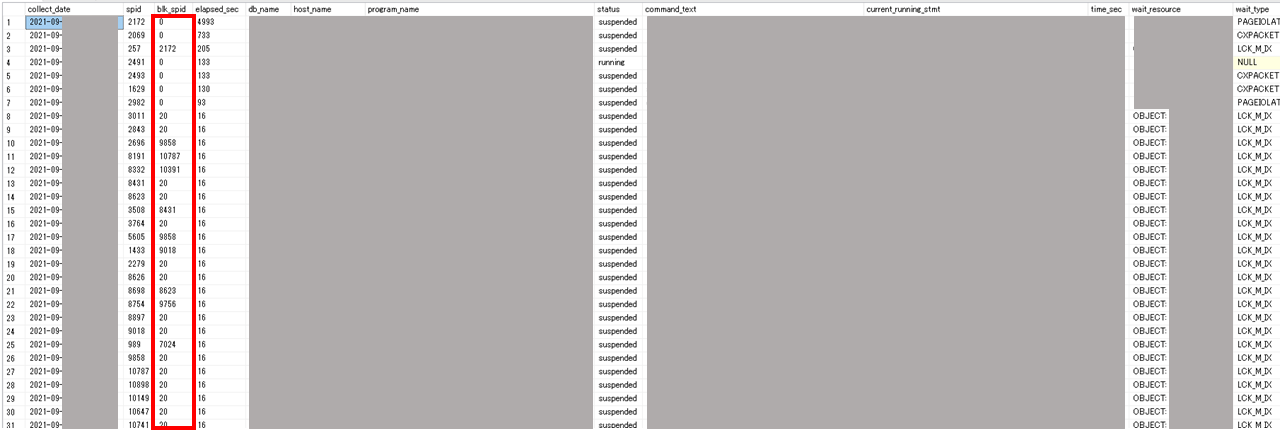
blk_spid <> 0なリクエストが大量発生しており、ブロッキングが多発していることが確認できました。
拡張イベントの[blocked_process_report]を保存しているxevent_dumpテーブルからブロッキングの情報を確認したところ、以下の画像のように、特定のobjectへのロック獲得待ちを待っているリクエストが大半であることが分かりました。
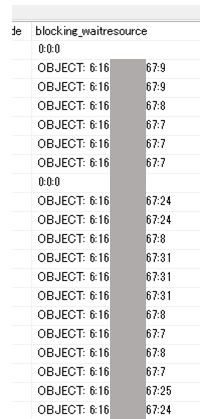
このOBJECTの名前を解決するために以下のクエリを実行しました。
select object_name(16****67)
すると、以下のように変更の追跡用の内部テーブルであることが分かりました。
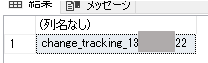
この内部テーブルの命名規則は[change_tracking_変更の追跡を設定した元テーブルのobjectid]という形式になっているため、再度オブジェクト名を解決ました。
select object_name(13****22)
これで元テーブルの名前(以下、テーブルA)が分かりました。
変更の追跡に関する内部テーブルは、テーブルAを更新する場合は一緒にロックを獲得する必要があります。change_tracking_xxxテーブルへのIXロックに獲得で一律待っていたため、ヘッドブロッカーはchange_tracking_xxxテーブル全体にXロックを書けていると推測しました。
拡張イベントのブロッキング情報から、ブロッカーのexecutionStackを確認しました。

spid=20ということで、システムプロセスのようです。sqlhandleをそれぞれ解決してみたところ、「sp_changetracking_remove_tran」という内部生成されたストアドプロシージャであることが分かりました。
このストアドプロシージャは以下の定義となっておりました。
CREATE PROCEDURE sys.sp_changetracking_remove_tran (
@objid INT
,@csn BIGINT
,@batch_size INT
,@stat_value BIGINT OUTPUT
)
AS
BEGIN
SET NOCOUNT ON
DECLARE @stmt NVARCHAR(1000)
SELECT @stat_value = 0
IF object_name(@objid) IS NOT NULL
AND @csn IS NOT NULL
BEGIN
IF @csn IS NOT NULL
BEGIN
SELECT @stmt = N'delete top(@batch_size) from sys.' + quotename(object_name(@objid)) + ' where sys_change_xdes_id in (select xdes_id from sys.syscommittab ssct where ssct.commit_ts <= @csn)'
EXEC sp_executesql @stmt = @stmt
,@params = N'@csn bigint, @batch_size int'
,@csn = @csn
,@batch_size = @batch_size
SELECT @stat_value = @@rowcount
END
END
END
バッチサイズを指定して、ある程度のバッチに分けて削除しているようです。
一応、ロックエスカレーションが該当時間帯で発生したのかも確認しました。
dm_db_index_operational_stats_dumpをチェックすることで判断できます。

画像の赤丸内が示すように、ロックエスカレーションの発生(index_lock_promotion_count)が確認できました。
バックグラウンドで定期的に実行されるクリーンアップタスクによる、変更の追跡用の内部テーブルの削除ストアドがロックエスカレーションによってテーブル全体をロックし、そのロックを長時間保持し続けたのがエラー多発の原因であると分かりました。
ただ、なぜ5000件の削除なのに他のクエリをタイムアウトさせるほど長時間実行され続けたのかが分かっていません。
そこもできる限り調査しました。
dm_exec_query_stats_dumpを使って、平均の実行時間とCPU使用時間を比較してみました。
select
cast(total_elapsed_time*1.0 / execution_count / 1000 as int) as avg_elapsed_time_ms
,cast(total_worker_time*1.0 / execution_count / 1000 as int) as avg_worker_time_ms
,cast(max_elapsed_time / 1000. as int) as max_elapsed_time_ms
,cast(max_worker_time / 1000. as int) as max_worker_time_ms
,cast(total_rows*1.0 / execution_count as int) as avg_total_rows
,cast(total_grant_kb*1.0 / execution_count as int) as avg_grant_kb
,cast(total_logical_reads*8.0 / execution_count as int) as avg_logical_reads_kb
,cast(total_physical_reads*8.0 / execution_count as int) as avg_physical_reads_kb
,*
from
dm_exec_query_stats_dump with(nolock)
where parent_query like '%delete top(@batch_size) from sys.%'
and parent_query like '%13****22%'
order by collect_date
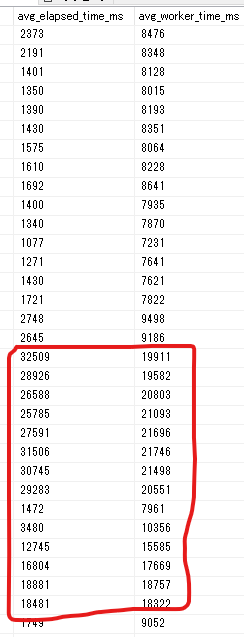
↑のように、実行時間とCPU時間にそこまで大きな差が無いことから、削除ストアドはほとんどstatus=runningであったことが推測できます。つまり、削除ストアドは他のプロセスにブロックされていた等の理由で実行時間が長引いたわけではなく、単純に実行に時間がかかっていたということのようです。
ここまで調査した内容を踏まえて解決策をいくつか検討しました。
解決策の検討
①sys.sp_changetracking_remove_tranのパラメータに指定する削除バッチサイズを小さくする
sys.dm_exec_query_statsを使って、キャッシュされている実行プランのXMLの中からコンパイル時に指定されたバッチサイズを確認してみました。

このように、5000件ずつDELETEしているようです。
dm_exec_query_stats_dumpから、過去の削除処理のレコード数も確認しました。
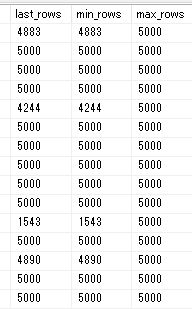
↑の画像のように、5000より少ないレコード数を削除したときがあっても、最大の行数は必ず5000で固定でした。
この値を明示的に変更する方法を調査しましたが、見つからずバッチサイズは5000からは変えられないと判断しました。
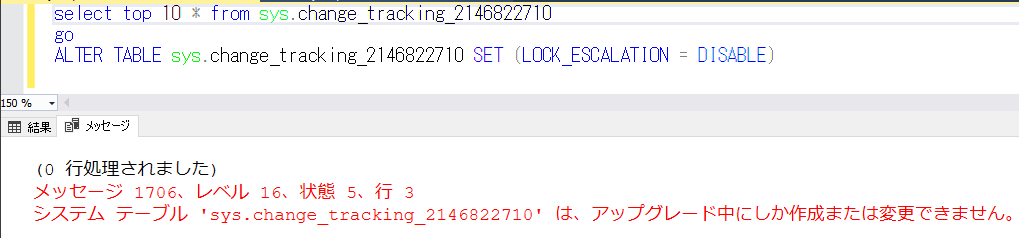
②change_tracking_xxxのロックエスカレーションの無効化
クリーンアップのストアドプロシージャがアクセスするのは古いデータ、テーブルAの更新クエリがアクセスするのは新しいデータのはずなので、ロックエスカレーションさえ発生しなければ、クリーンアップストアドとの競合によるブロッキング発生はなくなるのではと予想しました。
そこでchange_tracking_xxxのロックエスカレーションを無効化できないか検証したのですが、無理であることが分かりました。
③changetable経由で共有ロックを保持することでロックエスカレーションを防止
かなり細かい作業ですが、change_tracking_xxxテーブルに1レコードだけでも共有ロックをかけ続けられればロックエスカレーションを防止できます。change_tracking_xxx系のテーブルはDACでないと直接SELECTができず、以下のようなクエリを発行することで内部的にchange_tracking_xxxテーブルにアクセスできます。
SELECT top (1) * FROM CHANGETABLE(CHANGES テーブルA, 0) AS CT
しかし、↑のクエリはフルスキャンになってしまうようで、うまいこと1行だけにロックをかける、といった制御が難しいと判断しこの方法も断念しました。
④サーバー単位でロックエスカレーションを無効化する
テーブル単位でロックエスカレーションを無効化するのは難しいとの結論になりましたが、サーバー単位であればトレースフラグを設定することで制御できます。以下のクエリを実行することで、「ロック数に基づいたロックエスカレーション」をサーバーレベルで無効化できます。
DBCC TRACEON(1224, -1)
対応は局所的にとどめておきたかったのですが、テーブル単位での制御が難しいと判断したことから、今回は案④を採用することにしました。
まとめ
変更の追跡を設定したテーブルに対する、クリーアップタスクによる内部のストアドプロシージャ起因でブロッキングが発生してエラーが多発する事例をご紹介しました。また、再発防止策としてサーバーレベルでロック数に基づいたロックエスカレーションを無効化する案を採用しました。
まだ対応策は実施していないので、実際にトレースフラグをセットした後に結果をご報告したいと思います。