パーティション分割について調べてみたことをまとめます。
公式ドキュメントはこちら
パーティションについて
上記公式ドキュメントによると、以下の3つのメリットがある
- データのサブセットへのアクセスや転送が高速化
- メンテナンス操作(削除やインデックス再構築など)の高速化
- クエリのパフォーマンス改善
クエリレベルでの実施方法
①パーティション関数の作成
データを「どのようにパーティショニングするか」という定義
CREATE PARTITION FUNCTION PF_Sample(datetime2) --datetime2 : VALUESに指定する値のデータ型
AS RANGE RIGHT --設定している値をパーティションの右側に置くのか、左側に置くのか、という設定。今回は「右」にしており、2021/1/31より昔のデータがpartition_number=1となる。
FOR VALUES('2021/02/01', '2021/03/01', '2021/04/01') --パーティションの区切りとなる値を指定
GO
※パーティション関数の定義において、「どのようにパーティショニングするか」(パーティションの区切りとなる値)については、一つ一つ直接値を明示的に指定する必要がある
※VALUESで指定する値の数は、1000がパフォーマンスへのオーバーヘッドの閾値と言われている。上限値としては15000までは作れる。
参考:パフォーマンスに関するガイドライン
②パーティション構成の作成
「各パーティションのデータをどのファイルグループに配置するか」を定義
CREATE PARTITION SCHEME PS_Sample
AS PARTITION PF_Sample
ALL TO ([PRIMARY]) --ALL : 全部PRIMARYファイルグループにいれる
GO
③パーティションテーブルの作成
作成したパーティション構成を指定する。
また、「どのカラムをもとにパーティションを分割するか」を「パーティション分割列」として指定する。
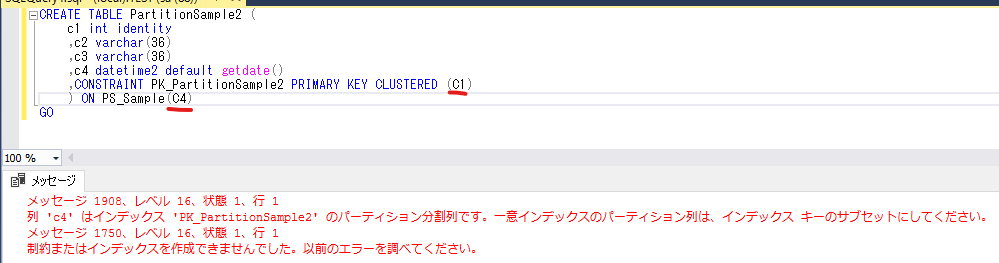
CREATE TABLE PartitionSample (
c1 int identity
,c2 varchar(36)
,c3 varchar(36)
,c4 datetime2 default getdate()
,CONSTRAINT PK_PartitionSample PRIMARY KEY CLUSTERED (C1 ,C4)
) ON PS_Sample(C4) --C4:パーティション分割列 / パーティショニングキーと呼ばれる
GO
注意点
主キーやユニーク制約などの一意インデックスに対してパーティショニングする場合、キー項目をパーティション分割列に含める必要がある。
メリット / デメリット
メリット
- パーティション単位でデータメンテナンスが可能
- パーティション単位の再構成 / 再構築
- パーティション単位の Truncate
- パーティション単位でデータのアーカイブ可能
- パーティションのスイッチによる別テーブルへのアーカイブ
- 物理 I/O の分散
- パーティション単位でファイルグループを指定することができるため、データを格納する物理ファイルをパーティション単位に分散させることができる
- ※ファイルグループを統一(例:All to PRIMARY)していた場合はこの効果は見込めない。
-- パーティション分割列を使用した検索の効率化 - パーティション分割列を使用した検索によるスキャンが発生した場合、該当するパーティションのみがアクセスされるため、パーティション分割列を使用した検索については、スキャンのオーバーヘッドを抑えることができる
デメリット
- パーティション分割によるオーバーヘッドの発生
- 通常のテーブルと比較すると、テーブルの構成が複雑となるため、ミリ秒またはそれ以下の処理時間でのオーバーヘッドは発生する
- パーティションのメンテナンスが必要となる
- 時系列でパーティショニングした場合、必要となるパーティションが存在しているかのメンテナンスが必要となる
- 例えば月ごとの値でパーティションの範囲を決めている場合、10年先まで(120個くらい)最初に入れておく、とかはありだが、10年後に再度メンテする必要がでてくる
- インデックスと実データのパーティションを固定化する必要がある
- インデックスと実データのパーティションの構成が同一になっていないと、Truncate やパーティションのスイッチを行うことができない。
- ※片方はパーティション化されていて、片方はパーティション化されていない、っていうのでもNG
- そのため、インデックスを新規に作成する際には、適切なパーティション構成で作成を行う必要がある
- パーティション分割列を変更した場合のオーバーヘッドの発生
- UPDATE をした際には、DELETE / INSERT により、他のパーティションへのデータ移動をする
- ※上記の例だとc4をUPDATEした場合がこれに該当。registerDTとかだと基本UPDATEされないため、このオーバーヘッドは気にしなくてもOK
用途
- パーティション分割列で検索された場合のスキャン範囲の限定
- パーティション単位のデータの削除
-パーティション単位のデータのアーカイブ - パーティション単位のデータのメンテナンス (再構成 / 再構築)
- パーティション単位の物理データ格納領域 (ファイルグループ) の分散
運用例
テストデータのINSERT
set nocount on
insert into PartitionSample (c2, c3, c4)
values (newid(), newid(), dateadd(day, cast(rand() * 100 as int), '2021/1/1'))
go 1000
パーティション分割列で検索された場合のスキャン範囲の限定
select count(*) from PartitionSample
where c4 between '2021/03/01' and '2021/03/31'
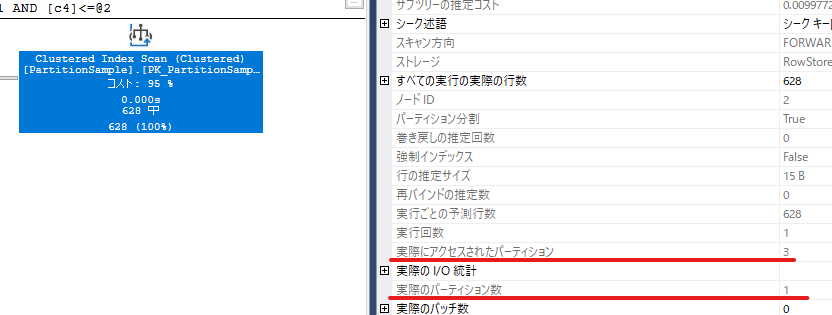
「実際にアクセスされたパーティション」アクセスが発生したパーティション番号
「実際のパーティション数」アクセスが発生したパーティションの数
今回の例だと、パーティション番号3のパーティション1つだけを読み取っているのでIndex Scanの読み取りページ数が通常時よりも削減できていることが分かる。
パーティション単位のデータの削除
インデックスを一つ作ってみる
create index ix_PartitionSample_c2 on PartitionSample(c2)
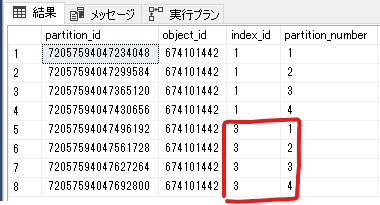
作成したインデックスがパーティショニングされるか確認
select * from sys.dm_db_partition_stats where object_id = object_id('PartitionSample')
↓パーティション番号が1から4までバラけているため、特に指定しなくても自動でパーティショニングされていることが分かる。このように、parittion_numberがクラスタ化インデックスと同じ構成のものを「固定されたインデックス」と呼ぶ
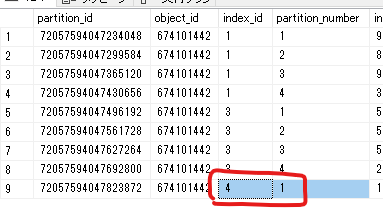
わざとON PRIMARYつけてみる
create index ix_PartitionSample_c3 on PartitionSample(c3) on [primary]
再度確認すると、1つのパーティションしか使われていないインデックスになっている(=パーティション分割されていない)
パーティション指定のTRUNCATEしてみる
truncate table PartitionSample with (partitions(2)) --2:任意のpartition_number

失敗する。
パーティショニングされていないインデックスをDROPしてからtruncateすると成功する
drop index ix_PartitionSample_c3 on PartitionSample
truncate table PartitionSample with (partitions(2))
値を入力すると、その値がどのパーティション番号に該当するか返してくれる関数
select $PARTITION.[PF_Sample]('2021-01-01')
select $PARTITION.[PF_Sample]('2021-02-01')
この関数を使って以下のようにTRUNCATEを書き換えられる
truncate table PartitionSample WITH (PARTITIONS($PARTITION.[PF_Sample]('2021-01-01'))) --2021/1/1のデータが入っているパーティションの全データをtruncate
パーティション単位のデータの削除(バージョン2016より前の場合)
ドキュメントによると、TRUNCATE TABLEの構文でwith (partitions())がサポートされていない。
したがって、以下の手順で代替する必要がある。
1.アーカイブ用テーブルを作成 ※パーティションはされておらず、それ以外のスキーマは同じものでもOK
CREATE TABLE PartitionSample_Archive (
c1 int identity
,c2 varchar(36)
,c3 varchar(36)
,c4 datetime2 default getdate()
,CONSTRAINT PK_PartitionSample_Archive PRIMARY KEY CLUSTERED (C1 ,C4)
)
GO
2.削除したいパーティション番号を特定し、アーカイブ用テーブルにスイッチ(移し替え)
DECLARE @PartitionNo INT
SELECT @PartitionNo = $PARTITION.[PF_SAMPLE]('2021/04/01')
SELECT @PartitionNo
--この時点で元テーブルからはデータが消える
ALTER TABLE [dbo].[PartitionSample] SWITCH PARTITION @PartitionNo TO [dbo].[PartitionSample_Archive];
※同時に2パーティション以上スイッチしたい場合はアーカイブ用テーブルもパーティション化が必要。
※アーカイブ用テーブルをパーティション化しておらず、かつ空じゃないときはスイッチ時に以下のエラーがでるので、空にしてから実施

いずれにせよ、同一ファイルグループに属している必要はある。SWITCHはファイルグループ内でポインタをつけかえるだけなので。ファイルグループをまたぐとmdf/ndfの物理ファイルが変わってしまうためポインタの移動ができない。
スイッチ実行により指定パーティションのデータがArchive側に移ったことを確認。
select * from sys.dm_db_partition_stats where object_id = object_id('PartitionSample')
select * from sys.dm_db_partition_stats where object_id = object_id('PartitionSample_Archive')
3.アーカイブ用テーブルをTRUNCATE
TRUNCATE TABLE [dbo].[PartitionSample_Archive]
パーティション単位のデータのメンテナンス
alter table PartitionSample rebuild partition=2
既存テーブルをパーティション化したい場合
1.普通のPKのクラスタ化インデックスがPRIMARYファイルグループに存在するとする
CREATE TABLE Sample (
c1 int identity
,c2 varchar(36)
,c3 varchar(36)
,c4 datetime2 default getdate()
,CONSTRAINT PK_Sample PRIMARY KEY CLUSTERED (C1)
)
GO
2.一度PK制約を削除
ALTER TABLE Sample DROP CONSTRAINT PK_Sample
3.パーティションキー含めた主キーで作り変え
-- not null制約追加
ALTER TABLE Sample ALTER COLUMN c4 datetime2 not null
--主キー作り変え
ALTER TABLE Sample
ADD CONSTRAINT PK_Sample PRIMARY KEY CLUSTERED (c1, c4) ON PS_Sample(c4)
ということで、既存のテーブルをパーティション化するハードルは高めな印象。PK制約の削除時にデータ量が多いテーブルだと長時間Sch-Mロックがかかるはず。
データ量少なければいけそうだが、そもそもデータ量少ないテーブルにパーティション化するメリットも無いと思われる。
パーティション関数のALTER
SPLIT
月ごとに区切った場合、月が枯渇した場合に未来の年月をパーティション関数に追加する必要がでてくる。
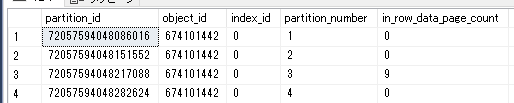
select * from sys.dm_db_partition_stats where object_id = object_id('PartitionSample')
--レンジを分割する(パーティションの区切りを追加)
ALTER PARTITION FUNCTION [PF_Sample]() SPLIT RANGE ('2021/05/01')
select * from sys.dm_db_partition_stats where object_id = object_id('PartitionSample')
パーティション番号が一つ追加されていることが分かる。
↓
MERGE
パーティションの区切りを削除したい場合はMERGEを使う。
ALTER PARTITION FUNCTION [PF_Sample]() MERGE RANGE ('2021/02/01')
パーティション番号が一つ減る。
パーティション化の注意事項
パーティション分割列との複合キーになるため、IDの重複が許容される。(だからといってIDに別途UQ制約をつけるとパーティションのメリットを享受できない)
IDENTITYとしておけば基本的には重複発生しないが、SET IDENTITY_INSERT ONの状態でINSERTすると重複レコードを挿入できてしまうので、IDカラムの一意性についてはアプリケーション側で担保する。
パーティション作成のガイドライン
前提として、パーティションは全テーブルに対して作成するようなものではない。
パーティション作成のメリットを享受したい場合にのみ、パーティションの作成を検討する。
注意点
1.パーティションを作成する際は、パーティション関数に指定する領域値が枯渇しないように指定する
一番右側のパーティションのレコード数は常にゼロ。月単位であれば、30年分(12*30=360)くらいを事前に入れておくのはあり。
2.基本的に1テーブルにつき1パーティション関数を用意
SPLITやMERGEを別々に管理できるため。でもこのメリットを享受する必要がなければ1パーティション関数を共通で使う方があり。