SQLのクエリを実行するとき、ボトルネックになりがちな演算の1つにソートがあります。
全レコードを並び替えるため、レコード数が多ければ多いほどそのコストも増大していきます。
ソートが発生するケースはいろいろありますが、代表的なのは「Order BY」句で明示的にデータの並び替えを指定する場合ですね。
-- int型のカラムが5つのテーブル 100万レコードINSERT済
-- SQLServerで実行
SELECT
column4
,column5
FROM SomeTable
WHERE column2 = 2
ORDER BY column3 -- 並び替え
実行プラン

100万レコード中、40万レコードくらいを返すSQLです。レコードをあまり絞り込めないWhere句のため、Sortに大きなコストがかかっています。
そこでインデックスを追加します。
CREATE NONCLUSTERED INDEX [IX1] ON [dbo].[SomeTable]
(
[column2] ASC
,[column3] ASC
)
INCLUDE ([column4], [column5])
GO
実行プラン
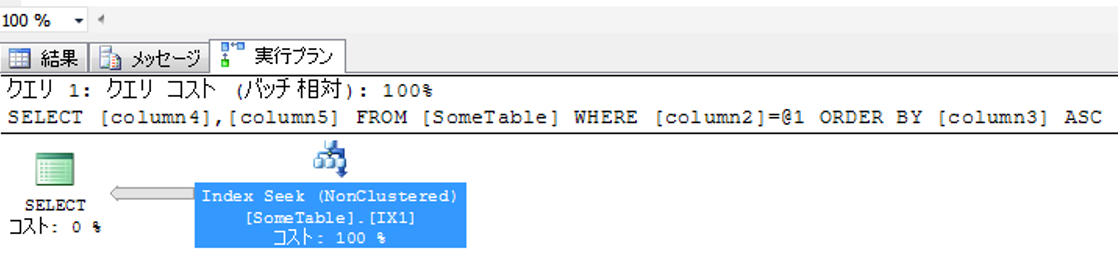
実行プランがIndexSeekに変化しました。高速に処理できています。
ポイントは以下の3点です。
- OrderByで使うカラムを、OrderByで指定するときと同じ並び順でインデックスに格納
- 付加列ではない、インデックスに存在するカラムが全てWHERE句で指定されている(今回の例でいうと、column2でインデックス並び替えてるのに、Where句で指定しなかったら結局column3でのソートが発生しちゃうので)
- クエリ内のカラムは全てインデックス内に存在する(=ルックアップが不要)
今回はわざとソートにコストがかかるようなクエリを発行していますが、実際はOrderByをつけていてもWhere句で絞込んだ結果10レコードとかになるのであれば、ソートのコストは無視できます。
最終的には発行するクエリの性質から最適なインデックスを導く必要がありますが、OrderByなどによってソートが発生するようなクエリでは今回の設計方針が役にたつケースがあると思います。