Are You Well-Architected?
みなさん、Well-Architectedしてますか?
本記事では、Amazon Bedrockを用いたシステムに対して、どのようにAWS Well-Architected Frameworkを適用したらよいのかを解説します。
本記事は Amazon BedrockをWell-Architectedしてみたシリーズ の 信頼性編 です。
対象読者
- AWS Well-Architected Frameworkに興味がある方
- Amazon Bedrockに興味がある方
- Amazon Bedrockを扱う際のベストプラクティスを知りたい方
なぜこの記事を書こうと思ったのか
昨今、生成AIが活況でAWS界隈でもAmazon Bedrockが注目を集めており、各種メディアや技術ブログでも様々な活用事例が紹介されています。
しかし、実際にそれらをプロダクト化しようとすると、セキュリティや信頼性、運用など様々な課題に直面します。
それらの課題を解決するには、AWS Well-Architected Frameworkが役に立ちます。
ただし、Amazon Bedrockは比較的新しいサービスであるため、それに対して、AWS Well-Architected Frameworkをどのように適用するのかについては、まだあまり語られていないと思います。
であれば、自分でやってみようじゃないか!ということで、この記事の執筆に至った次第です。
あとはまぁ、Amazon Bedrockに関する活用事例なんかはすでに山ほど出ているので、いまさら似たような話を書いても新鮮味はないので、別の切り口にしたほうがブログ的にも面白いかな、と。笑
シリーズ化
本記事を書くにあたり、以下の理由からAWS Well-Architected Frameworkの6つの柱ごとに記事を分け、シリーズ化しました。
- 1つの記事にまとめると結構なボリュームになるので読みづらくなる
- 柱ごと分かれていたほうが優先するテーマを確認しやすい
本記事は、その内の 運用上の優秀性 編に当たります。
他の柱を参照したい方は記事冒頭のリンクからどうぞ。
基礎知識
最初に本記事を読む上での基礎知識を説明します。
すでにご存じの方は読み飛ばしても構いません。
本章の内容は、他の柱の記事も同じ内容です。
すでに他の柱の記事を読んでいただいた方は読み飛ばしてください。
AWS Well-Architected Framework
AWS Well-Architected Frameworkとは、一言で表すなら AWSのベストプラクティスをまとめたフレームワーク です。
AWS Well-Architected Frameworkの6つの柱
AWS Well-Architected Frameworkは以下の 6つの柱 で構成されています。
- 運用上の優秀性 (Operational Excellence)
- セキュリティ (Security)
- 信頼性 (Reliability)
- パフォーマンス効率 (Performance Efficiency)
- コスト最適化 (Cost Optimization)
- 持続可能性 (Sustainability)
AWS Well-Architected Tool
AWS Well-Architected Frameworkには AWS Well-Architected Tool と呼ばれるツールが含まれています。
AWS Well-Architected Toolは、AWSマネジメントコンソールから利用可能です。
AWS Well-Architected Toolを利用し、ワークロードの定期的な評価やリスクを管理することができます。
AWS Well-Architected レビュー
AWS Well-Architected Frameworkに基づいて、アーキテクチャを評価するプロセスを AWS Well-Architected レビュー と呼びます。
Amazon Bedrock
Amazon Bedrockは、Amazon TitanやClaudeなど、Amazonや様々なAI企業が提供する基盤モデル (FM: Foundation Model)を統合APIを通じて利用できるようにするフルマネージドサービスです。
Amazon Kendra
Amazon Kendraは、機械学習を用いて最適されたエンタープライズ検索エンジンです。
RAG (Retrieval-Augmented Generation)
RAG (Retrieval-Augmented Generation)とは、大規模言語モデル (LLM: Large Language Models)によるテキスト生成に、外部情報の検索を組み合わせることにより回答精度を向上させる技術のことです。
日本語では「検索拡張生成」のように訳されます。
サンプルアーキテクチャ
本記事では、AWS Well-Architected Frameworkに基づいて、Amazon Bedrockを活用したシステムにおいて、考慮すべきベストプラクティスを解説していきます。
そのためにはレビュー対象となるアーキテクチャを定義する必要があります。
そこで、今回はAWS公式が提供している以下の AWS workshop studio 生成AI体験ワークショップ のアーキテクチャをサンプルとして進めていきます。
このアーキテクチャの肝は、Amazon BedrockとAmazon Kendraを用いたRAGの提供です。
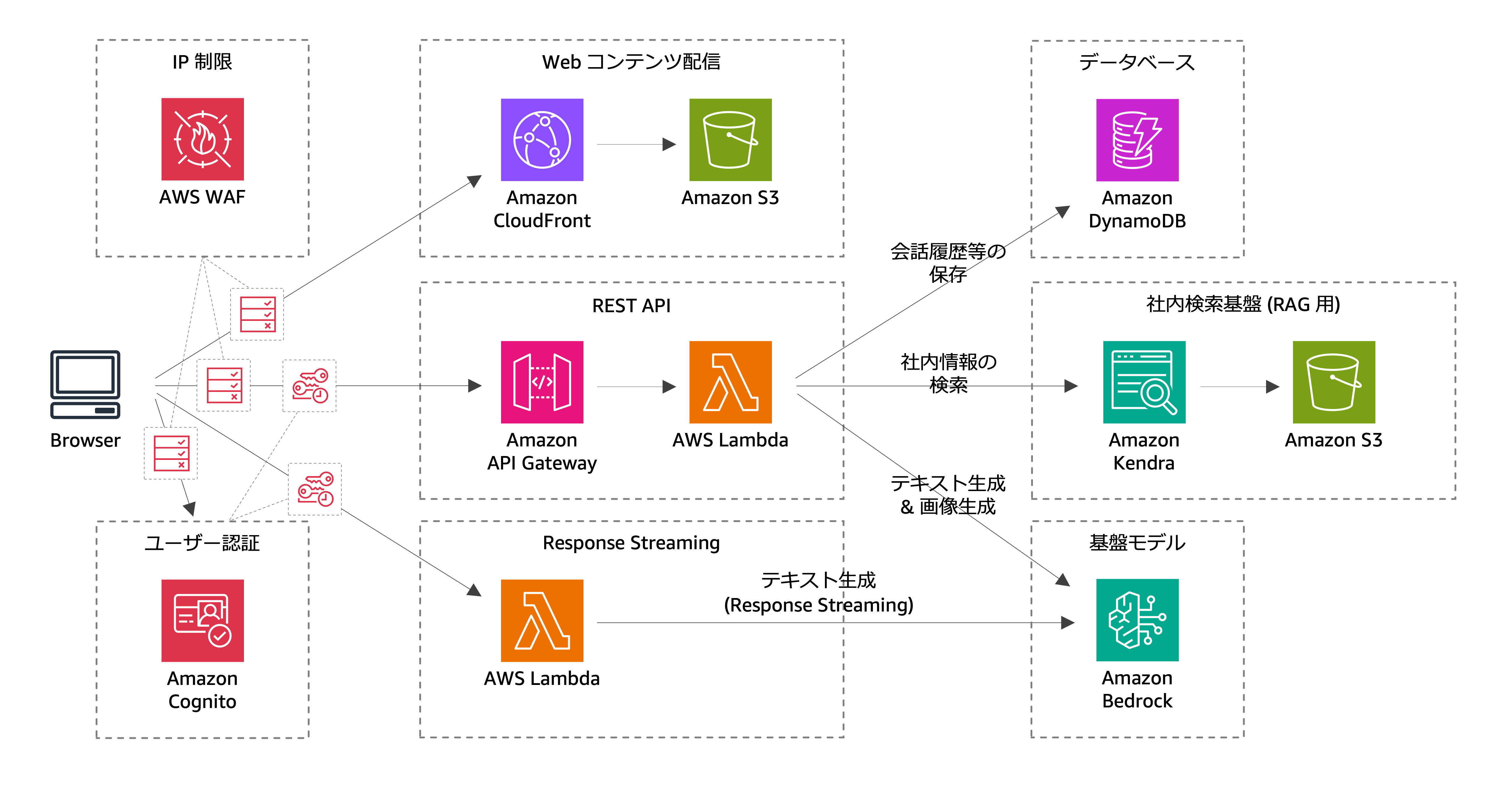
Amazon BedrockやAmazon Kendraを用いたRAGに興味のある方は、ぜひこちらのワークショップもやってみてください。
Amazon BedrockやRAGを理解する上でとても良いコンテンツだと思います。
AWS Well-Architected レビューの実施
前置きが長くなりましたが、ここからが本題です。
先ほどのサンプルアーキテクチャを題材として、AWS Well-Architected レビューを実施≒AWS Well-Architected Frameworkに基づいたベストプラクティスのポイントを確認していきます。
本来、AWS Well-Architected レビューはシステム全体のアーキテクチャを評価するものであり、特定のサービスに着目して実施するものではありません。
しかし、本記事ではAmazon Bedrockに着目して進めていきます。(それが本記事のテーマなので)
信頼性 (Reliability)
基盤 (REL 1-2)
REL 1-2では、サービスの制約やネットワークの信頼性に関するベストプラクティスが定義されています。
Amazon Bedrockのクォータは以下に詳しく記載されています。
基盤モデル毎に1分間で処理できるリクエスト数やトークン数が定義されています。
特に、Amazon Bedrockのクォータの多くは ハードリミット=上限を引き上げることができない制約 となっている点に注意する必要があります。
十分に余裕を持ってクォータの範囲内で運用できるのであれば問題はありません。
しかし、クォータを超える可能性がある場合、上限を引き上げることができないため、サービス提供に支障を来すリスクがあります。
ただし、これらのクォータの多くは、AWSアカウント内のリージョン毎の制約です。
つまり、マルチリージョンやマルチアカウント構成とすることにより、回避できる可能性がある点は覚えておきましょう。
また、Amazon BedrockのSLA(サービスレベルアグリーメント)も把握しておく必要があります。
Amazon BedrockのSLAは以下で定義されています。
Amazon Bedrockのリージョン毎のサービスコミットメントは 月間稼働率99.9% となっています。
つまり、99.9%以上の稼働率が求められる場合、マルチリージョンやマルチアカウント構成とすることが必須となります。
REL 1. サービスクォータと制約はどのように管理しますか?
クラウドベースのワークロードアーキテクチャには、サービスクォータ (サービスの制限とも呼ばれます) というものがあります。このようなクォータは、誤って必要以上のリソースをプロビジョニングするのを防ぎ、サービスを不正使用から保護することを目的として API 操作のリクエスト頻度を制限するために存在します。リソースにも制約があります。たとえば、光ファイバーケーブルのビットレートや、物理ディスクの記憶容量などです。
REL 2. ネットワークトポロジをどのように計画しますか?
多くの場合、ワークロードは複数の環境に存在します。このような環境には、複数のクラウド環境 (パブリックにアクセス可能なクラウド環境とプライベートの両方) と既存のデータセンターインフラストラクチャなどがあります。計画する際は、システム内およびシステム間の接続、パブリック IP アドレスの管理、プライベート IP アドレスの管理、ドメイン名解決といったネットワークに関する諸点も考慮する必要があります。
ワークロードアーキテクチャ (REL 3-5)
REL 3-5では、ワークロードアーキテクチャに関するベストプラクティスが定義されています。
信頼性を担保する上で重要な項目ですが、Amazon Bedrockを含め個々のAWSサービス単位ではなく、システム全体のアーキテクチャに関する内容となるため、ここでは割愛します。
REL 3. どのようにワークロードサービスアーキテクチャを設計すればよいですか?
サービス指向アーキテクチャ (SOA) またはマイクロサービスアーキテクチャを使用して、拡張性と信頼性の高いワークロードを構築します。サービス指向アーキテクチャ (SOA) は、サービスインターフェイスを介してソフトウェアコンポーネントを再利用できるようにする方法です。マイクロサービスアーキテクチャは、その一歩先を行き、コンポーネントをさらに小さくシンプルにしています。
REL 4. 障害を防ぐために、分散システムの操作をどのように設計しますか?
分散システムは、サーバーやサービスなどのコンポーネントを相互接続するために通信ネットワークを利用しています。このネットワークでデータの損失やレイテンシーがあっても、ワークロードは確実に動作する必要があります。分散システムのコンポーネントは、他のコンポーネントやワークロードに悪影響を与えない方法で動作する必要があります。これらのベストプラクティスは、故障を防ぎ、平均故障間隔 (MTBF) を改善します。
REL 5. 障害を緩和または耐えるために、分散システムの操作をどのように設計しますか?
分散システムは、サーバーやサービスなどのコンポーネントを相互接続するために通信ネットワークを利用しています。このネットワークでデータの損失やレイテンシーがあっても、ワークロードは確実に動作する必要があります。分散システムのコンポーネントは、他のコンポーネントやワークロードに悪影響を与えない方法で動作する必要があります。これらのベストプラクティスに従うことで、ワークロードはストレスや障害に耐え、より迅速に復旧し、そのような障害の影響を軽減できます。その結果、平均復旧時間 (MTTR) が向上します。
変更管理 (REL 6-8)
REL 6-8では、変更管理に関するベストプラクティスが定義されています。
REL 6のモニタリングについては、運用上の優秀性編を参照してください。
REL 7はスケーラビリティに関する内容ですが、Amazon Bedrockはフルマネージドサービスであり、キャパシティやスケールに関する設定もないため、対象外とします。
ただし、Amazon Bedrock以外の部分については、スケーラビリティを考慮する必要があるので、その点は留意しましょう。
REL 8はシステム全体のデプロイ方式に関する内容なので割愛します。
REL 6. ワークロードリソースをモニタリングするにはどうすればよいですか?
ログとメトリクスは、ワークロードの状態についての洞察を得るための強力なツールです。ワークロードは、しきい値を超えたり重大なイベントが発生したりしたときに、ログとメトリクスがモニタリングされて通知が送信されるように構成できます。モニタリングにより、ワークロードは、低パフォーマンスのしきい値を超えたときや障害が発生したときにそれを認識できるため、それに応じて自動的に復旧できます。
REL 7. 需要の変化に適応するようにワークロードを設計するには、どうすればよいですか?
スケーラブルなワークロードには、リソースを自動で追加または削除する伸縮性があるので、リソースは常に、現行の需要に厳密に適合します。
REL 8. 変更はどのように実装するのですか?
変更制御は、新しい機能をデプロイしたり、アプリケーションと運用環境で既知のソフトウェアが実行されており、予測できる方法でパッチを適用または置換できることを確認したりするために必要です。変更が制御されていないと、変更の影響を予測したり、変更によって発生した問題に対処したりすることが困難になります。
障害管理 (REL 9-13)
REL 9-13では、障害管理に関するベストプラクティスが定義されています。
バックアップや災害対策(DR)に関する内容が記載されていますが、Amazon Bedrockに関して特に リージョン を意識しておく必要があります。
Amazon Bedrockは比較的新しいサービスであるため、本記事執筆時点(2024年3月)では提供されるリージョンが限られており、さらに、サービス自体は提供されているリージョンでも特定の機能やモデルが制限されています。
そのため、遠隔地バックアップや災害対策のDR構成を実現することができない場合があることは留意しておきましょう。
REL 9. データはどのようにバックアップするのですか?
目標復旧時間 (RTO) と目標復旧時点 (RPO) の要件を満たすように、データ、アプリケーション、設定をバックアップします。
REL 10. ワークロードを保護するために障害分離をどのように使用しますか?
障害部分を分離した境界は、ワークロード内の障害の影響を限られた数のコンポーネントに限定します。境界外のコンポーネントは、障害の影響を受けません。障害部分を切り離した境界を複数使用すると、ワークロードへの影響を制限できます。
REL 11. コンポーネントの障害に耐えるようにワークロードを設計するにはどうすればよいですか?
高い可用性と低い平均復旧時間 (MTTR) の要件を持つワークロードは、回復力を考慮した設計をする必要があります。
REL 12. どのように信頼性をテストしますか?
本番環境のストレスに耐えられるようにワークロードを設計した後、ワークロードが意図したとおりに動作し、期待する弾力性を実現することを確認する唯一の方法が、テストを行うことです。
REL 13. 災害対策 (DR) はどのように計画するのですか?
バックアップと冗長ワークロードコンポーネントを配置することは、DR 戦略の出発点です。RTO と RPO は、ワークロードを回復するための目標です。これは、ビジネスニーズに基づいて設定します。ワークロードのリソースとデータのロケーションと機能を考慮して、目標を達成するための戦略を実装します。ワークロードの災害対策を提供することのビジネス価値を伝えるには、中断の可能性と復旧コストも重要な要素となります。
あとがき
最後まで読んでいただき、ありがとうございました。
本記事が、これからAmazon Bedrockを活用していこうと考えている方やAWS Well-Architected Frameworkの導入を検討している方の一助になれば幸いです。
いいねやストックをいただけると励みになりますm(_ _)m