こんにちは。おじろ(@ozro_223)です。
今日は自分のTweetをTwitterから取得して、前処理、形態素解析、固有表現抽出を行なってWordCloudで可視化する流れを紹介します。
自分のtweetを文字列でみると恥ずかしさのあまり○ぬことがあるので、ご注意ください
データの取得
Twitter apiを利用する方法もあると思いますが、自分はこの記事を参考に自分のtweetが格納されているtweets.jsを取得しました。
取得方法に関しては下記の記事を読んでください。何も難しいことはありませんので、すぐ取得できると思います。
tweet数が多い場合は取得まで一日以上かかる場合があります
実装
データの読み込み
まず初めに、データの読み込みを行います。
今回、環境としてはGoogle Colabratoryを使用しました。
まず初めに先ほど取得したtweets.jsを読み込むと、tweetの情報以外にも色々な情報が含まれていることがわかります。よって、tweetした内容のみを抽出します。以下のコードは同様の処理をしている記事と、shoku-panさんの記事を参考にさせていただきました。
with open('data/tweets.js') as f:
data = f.read()
# 参考: https://oku.edu.mie-u.ac.jp/~okumura/python/tweetdata.html
import json
from dateutil.parser import parse
from pytz import timezone
tw = json.loads(data[data.find('['):])
text_list = []
for t in tw:
full_text = t['tweet']['full_text']
created_at = t['tweet']['created_at']
text_list.append(full_text)
試しに、text_listの中身を見てみるとこのようになっています。
print(f'直近のツイート5件: \n {text_list[:5]}')
#['RT @johannyjm1: AI作曲のコンテストを開催します🙌🙌\nチェックしてくれ!!!!!🥳🥳🥳🥳🥳🥳', '足元ヒーターが機能してない寒さ', 'Twitterのデータ全然届かないな', '暖房入れても室温上がらん\n興奮してきた', 'さむい']
初っ端から自分のツイートではなく@johannyjm1さんのtweetですね。また、読み込み方法が悪いからか、ところどころツイートが抜けている気がしますが、厳密な分析をするわけではないので一旦スルーします。
RT情報は必要ないので、一旦元データを眺めてどのような前処理をするかを考えます。
with open('output/original_data.txt', mode='w') as f:
f.write('\n'.join(text_list))
前処理
データを見てみると

のように表示されるRTと
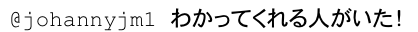
のように表示されるリプライがあります。
そのほかにも引用リプライやurl、画像を挿入した時に出てくる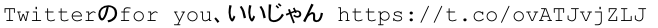
のようなhttpsから始まるような文字列も不要なので削除します。
@から始まるリプライは個性が出ると捉えられるので残そうか迷いましたが、一旦消します。
import re
import unicodedata
def preprocess_tweet(text):
#改行されることによって一部が前処理されない状態になるのを防ぐ
text = text.replace('\n', '')
text = re.sub('@.+', '', text)
text = re.sub('http.+', '', text)
text = re.sub('RT.+', '', text)
#日本語は半角全角が混合しているので整理
#参考:https://tex2e.github.io/blog/python/unicodedata-normalize
text = unicodedata.normalize('NFKC', text)
return text
preprocecced_text = [preprocess_tweet(tweet) for tweet in text_list]
preprocecced_text = [tweet for tweet in preprocecced_text if tweet != '']
形態素解析
今回はWordCloudなど色々使って可視化したい、ということで単語に分割します。
今回は文分割を行いませんが、行う場合はpysdbがオススメです。
今回はSudachiのPython版SudachiPy という形態素解析ツールを使用します。
%pip install sudachipy sudachidict_core
from sudachipy import tokenizer
from sudachipy import dictionary
tokenizer_obj = dictionary.Dictionary().create()
- Sudachiにおいて、単語分割の分割基準は以下の3種類があります。
- A: 短単位
- B: 中間
- C: 固有表現相当
Aが一番細かくて、Cが一番大雑把という感じです。
正直どれが一番いいかわからないので、それっぽい文章で全部試してみます。
mode_a = tokenizer.Tokenizer.SplitMode.A
mode_b = tokenizer.Tokenizer.SplitMode.B
mode_c = tokenizer.Tokenizer.SplitMode.C
test_tweet = preprocecced_text[9] # 【悲報】この時間に黒子のバスケ、決勝突入。夜更かし不可避
result_a = [m.surface() for m in tokenizer_obj.tokenize(test_tweet, mode_a)]
result_b = [m.surface() for m in tokenizer_obj.tokenize(test_tweet, mode_b)]
result_c = [m.surface() for m in tokenizer_obj.tokenize(test_tweet, mode_c)]
print(f'result mode A: {result_a}')
print(f'result mode B: {result_b}')
print(f'result mode C: {result_c}')
#result mode A: ['【', '悲報', '】', 'この', '時間', 'に', '黒子', 'の', 'バスケ', '、', '決勝', '突入', '。', '夜更かし', '不可避']
#result mode B: ['【', '悲報', '】', 'この', '時間', 'に', '黒子', 'の', 'バスケ', '、', '決勝', '突入', '。', '夜更かし', '不可避']
#result mode C: ['【', '悲報', '】', 'この', '時間', 'に', '黒子', 'の', 'バスケ', '、', '決勝', '突入', '。', '夜更かし', '不可避']
えー、まさかの完全一致.
他の文章でも試したましたが、A, B, Cどれも一致しました。
異なる例は以下のようになります。(SudachiPyから引用)
# 複数粒度分割
mode = tokenizer.Tokenizer.SplitMode.C
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# => ['国家公務員']
mode = tokenizer.Tokenizer.SplitMode.B
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# => ['国家', '公務員']
mode = tokenizer.Tokenizer.SplitMode.A
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# => ['国家', '公務', '員']
Cで十分ですね。Cで処理しましょう。
splited_text = []
for tweet in preprocecced_text:
result = [m.surface() for m in tokenizer_obj.tokenize(tweet, mode_c)]
splited_text.append(result)
print(splited_text[0])
#['足元', 'ヒーター', 'が', '機能', 'し', 'て', 'ない', '寒', 'さ']
試しに単語を数えてみましょう。こういう時に競プロでよく用いるdefaultdictが便利ですね。
from collections import defaultdict
word_dict = defaultdict(int)
for para in splited_text:
for word in para:
word_dict[word] += 1
#上位10位を表示
print(sorted(word_dict.items(), key=lambda x: x[1], reverse=True)[:10])
#下位10位を表示
print(sorted(word_dict.items(), key=lambda x: x[1])[:10])
#[('の', 3264), ('て', 2385), (' ', 2101), ('に', 1912), ('で', 1844), ('た', 1733), ('が', 1469), ('か', 1141), ('し', 1116), ('、', 1105)]
#[('足元', 1), ('ヒーター', 1), ('室温', 1), ('さむい', 1), ('片付か', 1), ('カッフェ', 1), ('MoT', 1), ('コネヒト', 1), ('Kanmu', 1), ('語る', 1)]
WordCloudで可視化
WordCloudで可視化を行ってみましょう。
# 日本語フォントをダウンロード
!apt-get -y install fonts-ipafont-gothic
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
import random
def create_word_cloud(word_seq):
res = WordCloud(
font_path = '/usr/share/fonts/truetype/fonts-japanese-mincho.ttf',
width=800, height=600, background_color='white',
#regexp=r"[\w']+"
).generate(word_seq)
plt.figure(figsize=(10, 8))
plt.imshow(res)
plt.axis('off')
plt.show()
text = []
for para in splited_text:
text += para
random.shuffle(text)
text = ' '.join(text)
create_word_cloud(text)

予想通りですが、「の」とか「が」とか機能語ばかりで全然面白くないですね。
WordCloudの引数としてstopwordsがあり、リストとして表示して欲しくない単語を渡すと表示せずに出力してくれます。
ただ、今回は品詞解析や固有表現抽出を行い、これらを改善したいと思います。
品詞解析
品詞解析と章立てをすべきか分からないほど、簡潔に行います。
機能語を消すために名詞のみを抽出して可視化したらいい感じになりそうだと考え、名詞のみを取り出して単語と同時に格納するコードを書きます。
品詞解析はsudachipyで可能です。
# 単語と品詞のタプルをリストに格納
word_pos = []
for para in preprocecced_text:
for m in tokenizer_obj.tokenize(para, mode_c):
word_pos.append(
(m.surface(), m.part_of_speech()[0])
)
print(preprocecced_text[0])
print(word_pos[:9])
#足元ヒーターが機能してない寒さ
#[('足元', '名詞'), ('ヒーター', '名詞'), ('が', '助詞'), ('機能', '名詞'), ('し', '動詞'), ('て', '助動詞'), ('ない', '助動詞'), ('寒', '形容詞'), ('さ', '接尾辞')]
以上のように品詞、単語を格納したので名刺のみを取り出して可視化してみましょう。
#名詞のみをwordcloudで可視化
nouns = []
for (word, pos) in word_pos:
if pos=='名詞':
nouns.append(word)
create_word_cloud(' '.join(nouns))

いい感じですね。めちゃくちゃ勉強してる人みたいになってますね(笑)
全然やってないkaggleや統計検定が入っていて、WordCloud上では優秀に見えます。
固有表現抽出
最後に固有表現抽出を行なって可視化してみましょう。
日本語解析ライブラリのGiNZAを用いて解析を行い、固有表現を抽出します。
ホームページ
論文
%pip install -U ginza ja_ginza_electra
import spacy
from ginza import *
nlp = spacy.load('ja_ginza_electra')
# from https://ja.wikipedia.org/wiki/Twitter_(%E4%BC%81%E6%A5%AD)
text = 'Twitter, Inc.は、カリフォルニア州サンフランシスコを拠点とする、アメリカ合衆国のIT企業である。'
doc = nlp(text)
spacy.displacy.render(doc, style='ent', jupyter=True) #entity->固有表現

たしか220種類くらいタグがあって、可視化も今回は全部灰色ですが、カラフルです。
では固有表現を抽出して可視化してみましょう!
# 30分かかる
ent_dict = defaultdict(int)
for doc in nlp.pipe(preprocecced_text):
for ent in doc.ents:
ent_dict[ent.text] += 1
ents = []
for ent_text, count in ent_dict.items():
ents += [ent_text] * count
random.shuffle(ents)
create_word_cloud(' '.join(ents))

さんって固有表現なんですね(?)
だいぶいい感じになりました。kaggleやTOEIC、英語など自分が全然できないものが大きく表示されていますね。これは何でだろう?(笑)
また、自分が好きな野球に関係するオリックス 山本由伸 大谷なども出てきてますね。
Twitterのアカウント名ではクルトンさん(@kuruton456)さんが大きく表示されていますね。クルトンさんのファンなのかもしれない。
終わりに
最後まで見ていただきありがとうございます。
WordCloudだけでなく@takapy0210さんのnlplotなどで可視化しても色々と発見があるかもしれません。
今回用いたコードはNAIST DSC summer seminarで用いられたコードを参考にさせてもらっています。
有料ですが値段以上に有益なことが多かったので来年も参加しようと思います。
今回用いたコードはgithub上で公開しますので、ご自由にいじってください。
またモチベーションが高まったら色々いじってみようと思います。
ありがとうございました〜。