はじめに
Kubeflowとは何なのか。
どんな知識が必要でどんなメリットがあるの?
エコシステムなんかはどうなっているの?
現状これらの問いの答えとなるような記事を見つけることができなかったため、本記事を執筆しました。
本記事ではKubeflowとは何なのか。そしてどのようなツールで構成されているのか図を交えながらできる限りわかりやすくまとめました。(本記事で使用している図に関してはご連絡いただければ元データをお送りできます。)
MLOps、Kubeflowについての日本語の学習リソースがほとんどないですが、MLOpsの概念や技術が日本で広まる一助になればいいなと思っています。
Kubeflowとは

近年の機械学習の急速な発展に伴って、機械学習を本番運用する機会が増えてくる中、てデータサイエンティストと開発者の連携やモデルのバージョン管理などの課題が重要視されてきています。そんな中で出てきた概念がMLOpsという考え方で、簡単に説明するとDevOpsを機械学習開発に応用しようというようなものです。
詳しくはこちらの記事を参照していただくとわかりやすいかと思います。
MLOpsを実現する上での重要な考え方としてML Pipelineとがあり、これはデータ抽出、特徴長エンジニアリング、モデル学習、モデルデプロイといった機械学習タスクを一連のパイプラインとして定義します。
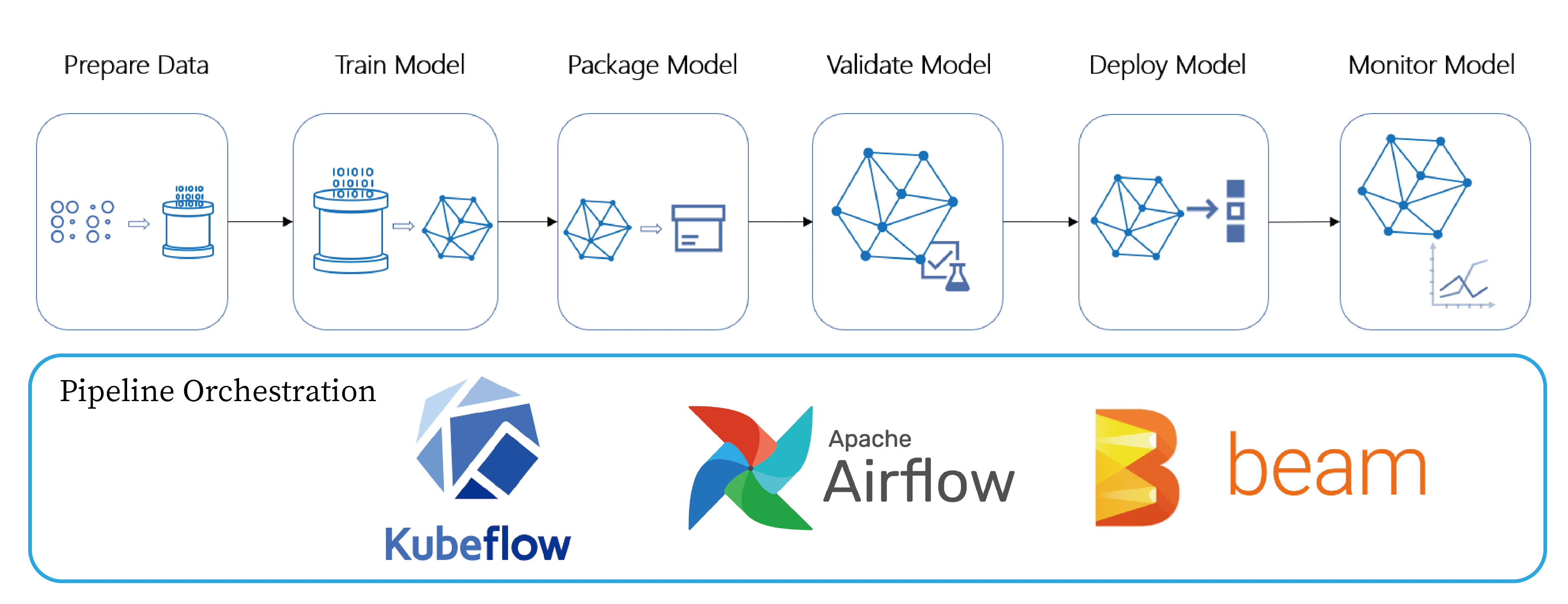
MLOpsではこのパイプラインをワークフローとして自動化し効率的に管理を行います。
そして、これらのパイプラインを定義しそれらを管理、統合するためのツールがKubeflowです。
KubeflowはKubernetes上でML Pipelineワークフローを管理するためのオープンソースツール群です。
元々はGoogleが社内でTensorFlowを用いたMLワークフローを管理するために使用していましたが、それを一般化しオープンソースにしました。
Kubeflowを用いてML Pipelineを実現することには以下のメリットがあります。
-
スケーラビリティ
Kubernetesのスケーリング機能を活かして、データ処理やモデル学習などを必要に応じてスケーリング可能です。 -
再利用性
コンテナベースなKubernetesを用いることで1度作成したパイプラインや環境をクラウドオンプレミス問わず実現可能です。 -
柔軟性
必要に応じて様々なツールと統合でき、柔軟なワークフローを定義可能です。また、Kubeflowツールの中でKubeflow Pipelineのみを既存のk8sクラスターに適応するといったこともできます。
また、上に記した図にある通り、パイプラインの管理にBeamやAirflowを用いることが可能です。そのほかにもMLflowなどのツールがありますが、前述のメリットから現状KubeflowがMLOpsのstate of artなようです。
Kubeflowの構成
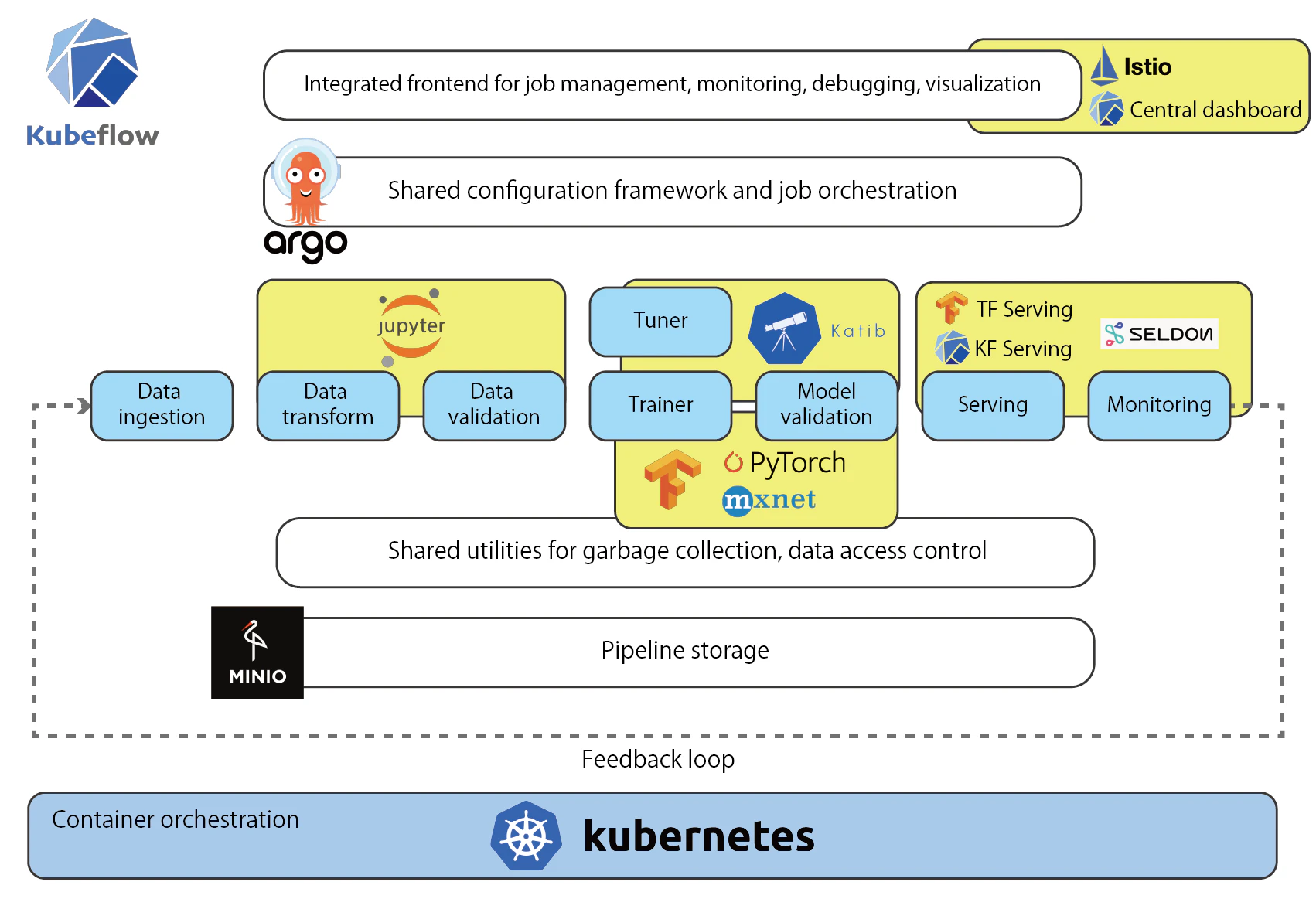
Central Dashboard
Central dashboardはKubeflowのWebフロントエンドです。パイプラインの作成やKatibを使ったモデルの最適化、Jupyter Notebooksを使った分析、Artifact(パイプラインによって生成されたモデルやデータ)の管理などをWeb UIで行うことができます。
JupyterHub
MLプロジェクトは最初はデータの分析、MLモデルのプロトタイプの作成などの実験を行うことから始まります。
KubeflowではJupyterHubという複数人で共同で実験を進めるためのツールを提供しています。JupyterHubは複数人のJupyter Notebookを一元管理することができます。また、各ノートブックごとにGPUやCPUメモリを設定でき、ノートブックごとのリソースの最適化を行うことができるようになっています。
JuypterHubで実行されるノートブックはコンテナインスタンス上で動作しており、インスタンスにはデフォルトでkubectlがインストールされているので、ノートブックからkubectlコマンドの実行ができます。
Jupyterインスタンスはdefault-editorというサービスアカウントで実行されており、以下のnamescopeのk8sリソースへの権限を持っています。
- Pods
- Deployment
- Services
- Jobs
- TFJobs
- PyTorchJobs
ちなみに、 ノートブックからkubectlを実行するには!kubectl apply -f <YAML_FILE>みたいな感じにします。
Training Operators
JupyterHubはプロトタイピングなどには有効ですが、本番運用の際にはKubeflowが提供するコンポーネントを利用してモデルの学習を自動化します。
モデル学習における分散処理だとかはOperatorと呼ばれるコントローラによって管理、実行されます。
例えば、TensorFlowの学習を実行する際には学習パラメータとWorker数を定義することでOperatorが自動で調整してくれます。以下はTFXを利用してパイプラインを定義する例です。
from tfx.orchestration import pipeline
from tfx.orchestration.kubeflow import kubeflow_dag_runne
pipeline_name ='example_pipeline'
direct_num_workers = 2
# 省略
pipeline_root = ...
components = ...
runner_config = ...
output_dir = ...
output_filename = ...
beam_arg = [f"--direct_num_workers={direct_num_workers}"]
p = pipeline.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
components=components,
beam_pipeline_args=beam_arg,
)
kubeflow_dag_runner.KubeflowDagRunner(
config=runner_config,
output_dir=output_dir,
output_filename=output_filename,
).run(p)
TensorFlow以外にも、Pytorch、MXNet、MPI、Chainerなどの学習をサポートしています。
Kubeflow Pipelines
Kubeflow PipelinesはML Pipelineの実行をオーケストレートします。
Kubeflow PipelinesはコンテナネイティブなワークフローエンジンであるArgo Workflowsをベースとしていて、**有向非巡回グラフ(DAG)**で定義します。
以下はKubeflow Pipelineの例です。
Kubeflowではそれぞれのパイプラインコンポーネントに対し、Kubernetesがコンテナを割り当て実行しています。
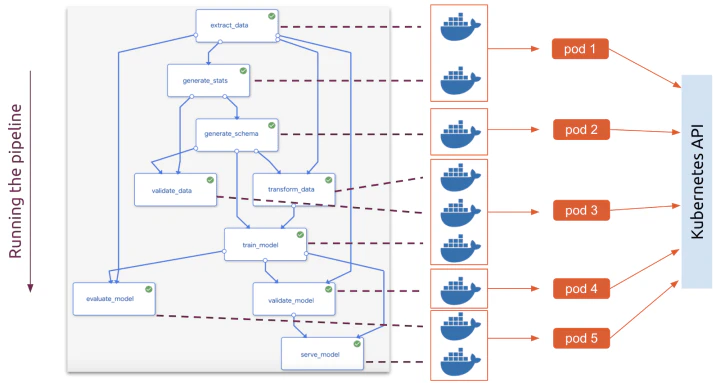
Demystifying Kubeflow pipelines: Data science workflows on Kubernetes – Part 1 by CANONICAL
Kubeflow Pipelinesは以下のコンポーネントから構成されています。
-
Python SDK
パイプラインをdomain-specific-language(DSL)を用いて定義できます。 -
DSL compiler
Pythonコードからパイプラインの設定をYAMLへと変換します。 -
Pipeline Service
YAMLから設定を読み取りパイプラインの実行を作成します。 -
k8s resources
Pipeline Serviceがk8s APIを呼び出し。必要なcustome resource definitions(CRDs)を作成します。 -
Orchestration controller
Orchestration controllerはCRDsに応じてコンテナの実行をおこないます。Orchestratin controllersは実行するパイプラインの設定に応じていくつか用意されており、例としてtask-drivenなワークフローではArgo Workflowが用いられています。 -
Artifact storage
MetadataとArtifactsの2種類のデータを管理します。
MetadataはExperiments、ジョブ、Runのスカラー情報でMySQLなどのDBに保存します。Artifactはパイプラインのパッケージなどであり、MinIOサーバーやGCSなどバケットを保存先として使用します。
MetadataやArtifactはKubeflowにより追跡され、デバッグやパイプラインJobを把握するために利用されます。
Hyperparameter Tuning
現在公開されているハイパーパラメータチューニングのツールは特定のMLライブラリへの依存が強かったり、サポートされている手法の数が少ないという課題があります。
Kubeflowの提供するKatlibはGoogle Vizierをベースとして作られたツールで幅広い要件に柔軟に対応でき、ベイズ最適化などの強力な手法をサポートしています。
KatlibはPytorch、TensorFlow、MXNetなど主要なライブラリをサポートしています。
Kubeflowでは本番運用のためにモデル提供ツールの利用をサポートしており、TFServing、Seldon serving、PyTorch serving、TensorRTなど多数のモデル提供ツールを利用可能です。
Model Inference
本番運用で機械学習モデルを提供する場合、基本的に機械学習モデルをAPIとして提供することになります。
機械学習モデルはデータやモデル構造、ハイパーパラメータの変更があったときに、提供しているモデルを更新する必要があります。それらを人手により管理するのは大きな人的コストがかりますし、予期せぬバグにつながってしまう可能性があります。そこでモデルのバージョニングやルーティングを提供してくれるのかモデル提供ツールです。
KFServing
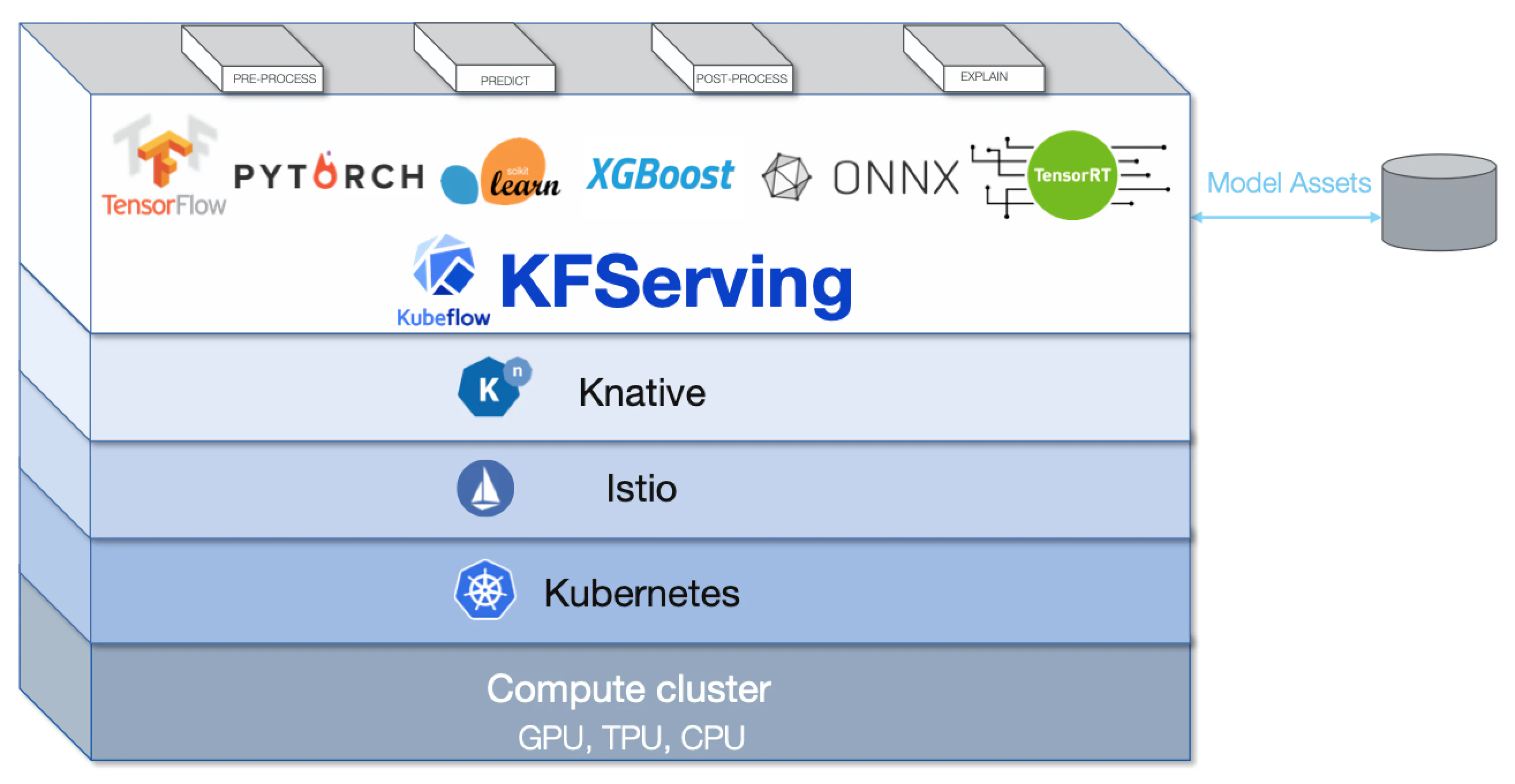
Kubeflowはモデル推論、自動スケーリング、ネットワーキング、ヘルスチェックを一般化した包括的モデル提供ツールであるKFServingを提供しています。KFServingはIstioとKnative servingをベースとしてサーバレスコンテナとして実装されており、高速化つスケーラビリティに優れた実装を実現しています。
KFServingはPreprocessor、Predictor、PostProcessorの3つのコンポーネントから構成されています。Preprocessorでは学習時に用い前処理と同様の処理を適応することができ、Postprocessorでは推論結果をユーザに返すときに必要な処理(例えばフォーマットの変換など)をオプションで指定できます。
Metadata
Metadata管理は日々MLモデルを構築していく中で、それぞれのモデルに関係する情報を管理、追跡するのに非常に便利です。
Metadetaには以下の情報を登録可能です。
- 学習に利用したデータソース
- それぞれのパイプラインで生成されたArtifact
- パイプラインコンポーネントの実行情報(ログなど)
- パイプラインと関係するその他の情報
これらの情報は、例えば、今までに生成された全てのモデルの表示、パイプラインの実行状況の表示などセントラルダッシュボードを通して有益な情報を提供してくれます。
その他のコンポーネント
これまでに説明してきたコンポーネント以外にもMinIOやIstio、Knative、Apach Sparkなど表面上見えていませんが、陰で活躍してくれているコンポーネントのおかげでKubeflowは成り立っています。
それぞれのコンポーネントの詳しく説明したいところですが、1つのコンポーネントで1つの記事が書けてしまうくらいなのでKubeflowではどのように貢献しているのかを簡単に説明して、詳しい説明は他の記事に譲ることにします。
簡単に説明すると、MiniIOは特定のクラウドに依存しないMLワークフローの構築のためのストレージを提供し、Istioはロードバランシングからサービスディスカバリ、モニタリングなど幅広くサービスメッシュとしての機能を提供しています。
Knativeは前述の通りKFServingなどのモデル提供の部分をサーバレスに実行するために使われていて、Apach Sparkをサポートすることにより大規模なデータ処理をDataprocやElastic Map Reduceなどをバックエンドに用いて実装することができます。
終わりに
本記事で紹介したKubeflowコンポーネントはそれぞれが相互作用しあってKubeflowエコシステムを支えています。本記事を通して、Kubeflowの概要を掴んでもらえれば嬉しいです。
学習リソースは日本語では現状ほとんど見つけることができないので、本記事が学習者の助けになれば幸いです。
参考記事