皆様こんにちは、
NTTデータ先端技術の尾崎遼太郎と申します。
私は普段、クラウド上にビッグデータ分析基盤を作る案件に携わっており、
最近は、AWSマネージドサービス(SageMaker, Glue, QuickSight, Lambda)を使ったデータ分析環境を提供する業務などをしています。
今回は、 「AWS CloudTrail Lake」 というサービスを利用してみましたのでご紹介します。
まだ登場して1年程度の新サービスです。↓what's Newの日本語は2022/01/05のようです。
ググると意外に記事が見つかるので、注目度がうかがえますね。
AWSの機能追加ペースからすると、1年以上経っている機能は新サービスとは呼ばないのか…!?
というのは冗談で、AWSの機能追加に負けないよう、私たちもどんどん新サービスを触っていきましょう!
それでは本編です。
CloudTrail Lakeの背景
機能の内容に入る前に、まずはこの機能が必要となった背景から簡単に考えていきましょう。
AWS上での様々なAPI操作の記録であるCloudTrailは、セキュリティ確保・監査の目的で非常に重要です。
ログは、単に収集・蓄積することはもちろんのこと、 必要に応じて調査のために検索ができる ということが大事です。
CloudTrailログの検索というと、これまでは以下の二つのパターンがよく使われる方式でした。
- CloudTrailのコンソールのイベント履歴ページで確認する
- S3に保管したログに対してAthenaで検索を行う
1の場合は複雑な検索ができず、期間の制約や、S3のデータイベント等が確認できないというデメリットがありました。
そのため多くの方が2の方式をとっていたかと思うのですが、Athenaの初期構築(DBやテーブルの作成)は意外と面倒で、
また「デフォルトのjson形式だと思ったよりも検索が遅い」というような課題に悩んだ方も多いのではと思います。
2022年に登場したCloudTrail Lakeは、そんな課題に対して非常に効果的な新サービスで、
非常に簡単な操作で、ログの集約・検索のための環境が構築できるサービスです。
では早速試してみましょう。
CloudTrail Lakeを使ってみる
イベントデータストアの作成
CloudTrailの画面の左に、「Lake」というメニューがありますので、そちらをクリックします。
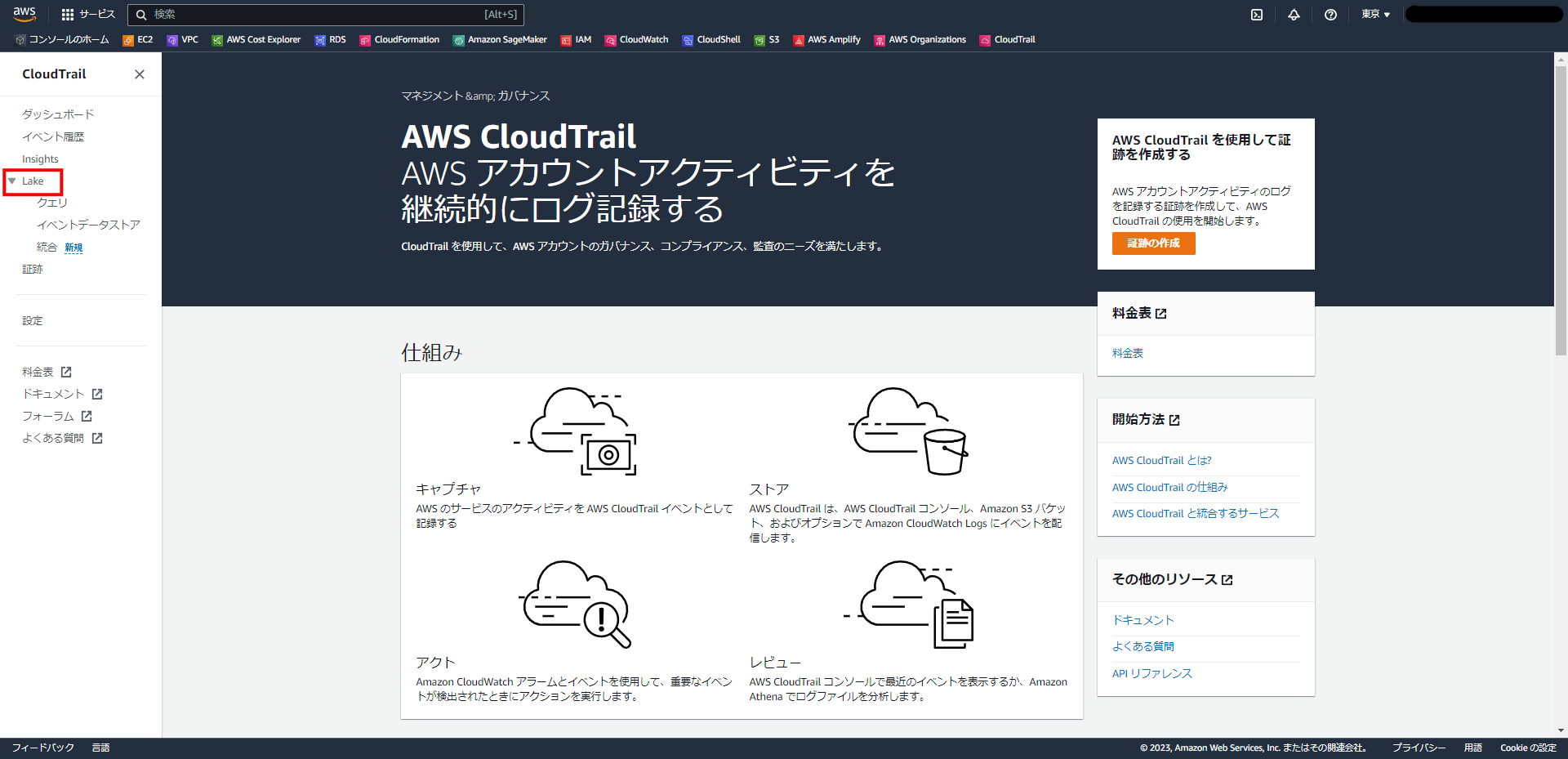
「CloudTrail Lakeの開始方法」というページの案内通り進めればよいようです。非常にわかりやすいですね。
「イベントデータストアを作成」を選択します。
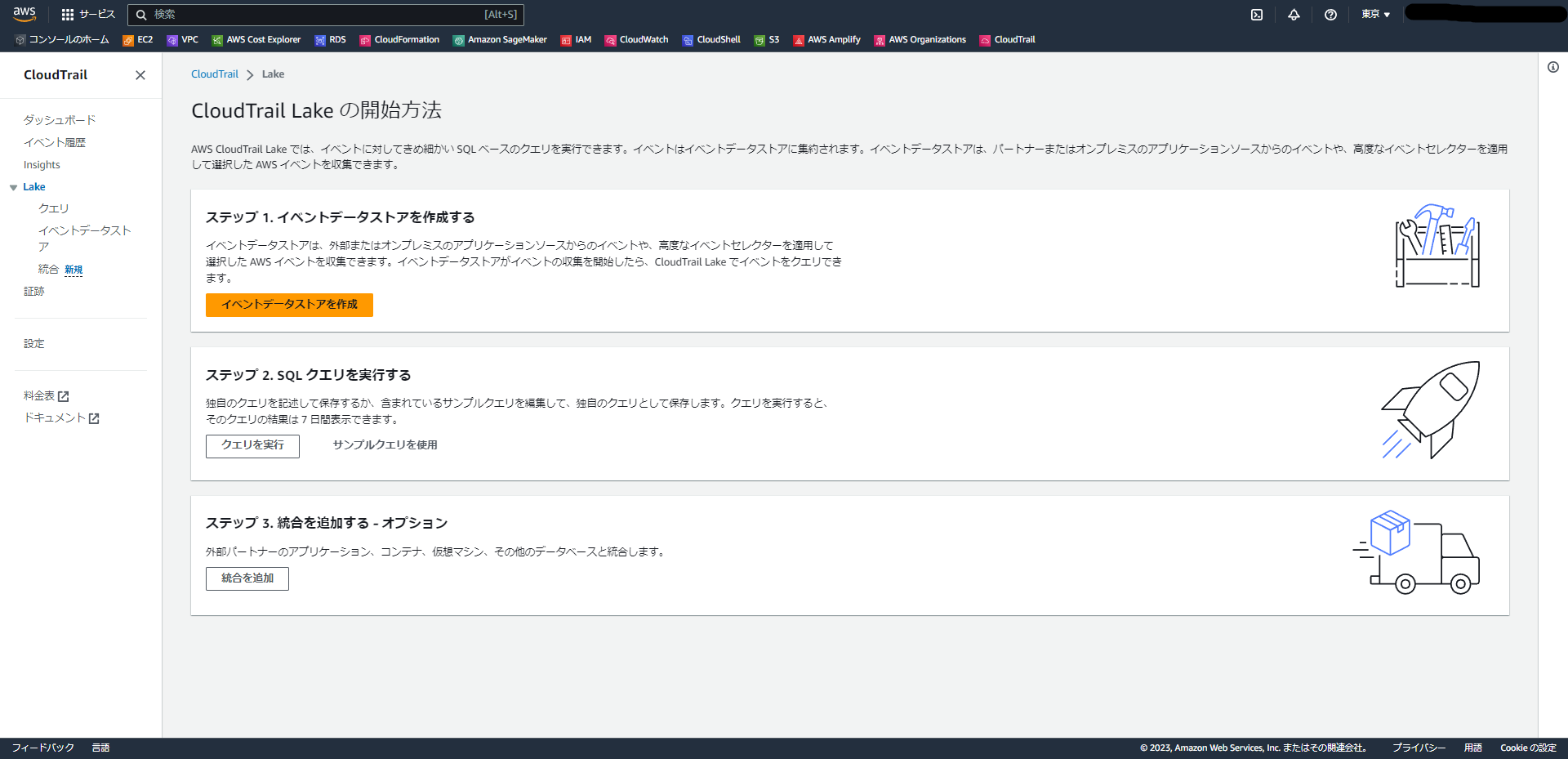
イベントデータストアの設定
「イベントデータストアの設定」という画面に遷移します。
以下を設定します。
- イベントデータストア名:任意。(今回は「my-event-data-store」という名前を選択しました。)
- 保存期間:最長7年を選択できるようです。今回はデフォルトの7年を選択しました。
- 暗号化:KMSによる暗号化を選択できるようですが、今回はチェックしませんでした。
- タグ:特に選択せずに次へ進みます。
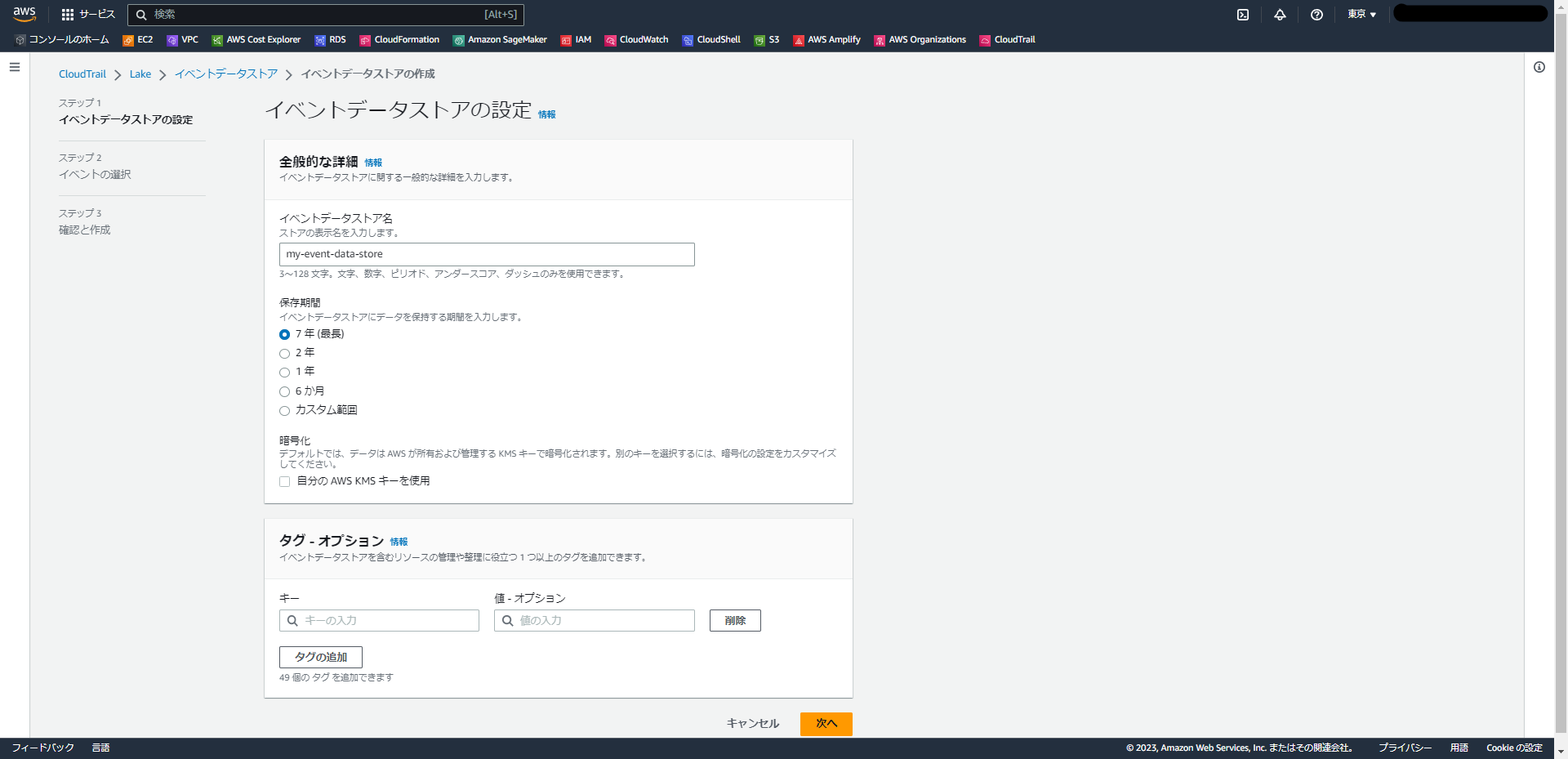
イベントの選択
「イベントの選択」という画面で以下を選択します。
- イベントタイプ:「AWSイベント」「統合からのイベント」のどちらかを選択できます。
今回は「AWSイベント」を選択します。
補足:「統合」は以下のドキュメントに記載があるのですが、AWS外のイベントを取り込む機能のようです。
AWS 外のイベントソースとの統合を作成する
- AWSイベントのタイプ:「CloudTrailイベント」「設定項目」のどちらかを選択できます。今回は「CloudTrailイベント」を選択します。
補足:「設定項目」ではAWS Configによるリソースタイプの変更情報を取得できるようです。
AWS Config 設定項目用に一意のイベントデータストアを作成する
- CloudTrailイベント
取得するイベントタイプを選択します。- 管理イベント:デフォルトでチェックされています。当然ながらチェックしたままにしておきます。
- データイベント:S3オブジェクトの操作などのアクティビティがデータイベントです。
こちらはデフォルトでチェックされていない状態になっています。
こちらを有効化するかは要件によりますが、今回はチェックしようと思います。
(チェックした場合ログ量が増え、コスト面への影響がある点にご留意ください。) - 証跡イベントをコピー:過去のイベントログを取得するかのチェックです。有効にしてみようと思います。
- イベントデータストアに現在のリージョン (ap-northeast-1) のみを含める:
ちょっとわかりづらいのですが、チェックしない状態(デフォルト)だとすべてのリージョンのログが集められる状態になっており、
チェックをすると他リージョンのログを収集しなくなるようです。
今回はチェックせず、全リージョンのログを集約しようと思います。 - 組織内のすべてのアカウントについて有効化:
Organizationsを利用している場合に、子アカウントのログを集約する機能のようです。
本アカウントではOrganizationsを利用しているため、今回は有効化してみようと思います。
補足:ちなみに、「過去イベントの取得」の機能は2022年9月のアップデートで登場した新機能のようです。
AWS CloudTrail Lake が Amazon S3 からの CloudTrail ログのインポートをサポート
-
管理イベント
取り込むイベントの詳細設定です。今回はデフォルトのままにしておきます。- 読み取り:有効
- 書き込み:有効
- AWS KMS イベントの除外:無効
- Amazon RDS のデータ API イベントを除外:無効
-
データイベント
先ほどデータイベントを有効化したため、データイベントの対象を選択する項目が表示されています。
今回は以下の一つを指定します。- データイベントタイプ:S3
- ログセレクターテンプレート:すべてのイベントをログに記録する
- セレクター名 - オプション:(空欄のまま)
※「データイベントタイプの追加」をクリックすれば、複数種類のデータイベントを選択することも可能のようです。
- 既存の証跡イベントをコピー
先ほど証跡イベントのコピーを選択したため、コピーのための設定項目が表示されています。
以下を選択します。- 証跡イベントのソースを選択:既存の証跡を選択します。
(こちらの環境では「management-events」という名前で作成済みでした。) - CloudTrail データの S3 の場所 (S3 URI):上で証跡を選択した場合は自動で対象バケットが入力されるようです。
- イベントの時間範囲を指定 - オプション:
取り込む証跡の範囲を選択できるようですが、今回は指定せずに全期間をインポートします。 - IAM ロールを選択:イベントのコピーに使うIAMロールを選択するようです。
デフォルトの「新しいロールを作成(推奨)」のままにしておきます。 - IAMロール名を入力:上で作成するIAMロールの名前を入力する箇所のようです。
説明によれば「新しいロール名の前に CloudTrailLake-ap-northeast-1- が付加されます」とのことだったので、
名前としてはそれで十分な気もしましたが、「role-202303」とだけ入力しました。
- 証跡イベントのソースを選択:既存の証跡を選択します。
補足:作業後にIAM画面から確認したところ、「CloudTrailLake-ap-northeast-1-role-202303」というロールが作成されていました。
作成されるロールに付与されるポリシーは、単に対象S3へのList・Get関連の権限のようです。
各項目の設定が終わったら「次へ」を選択します。
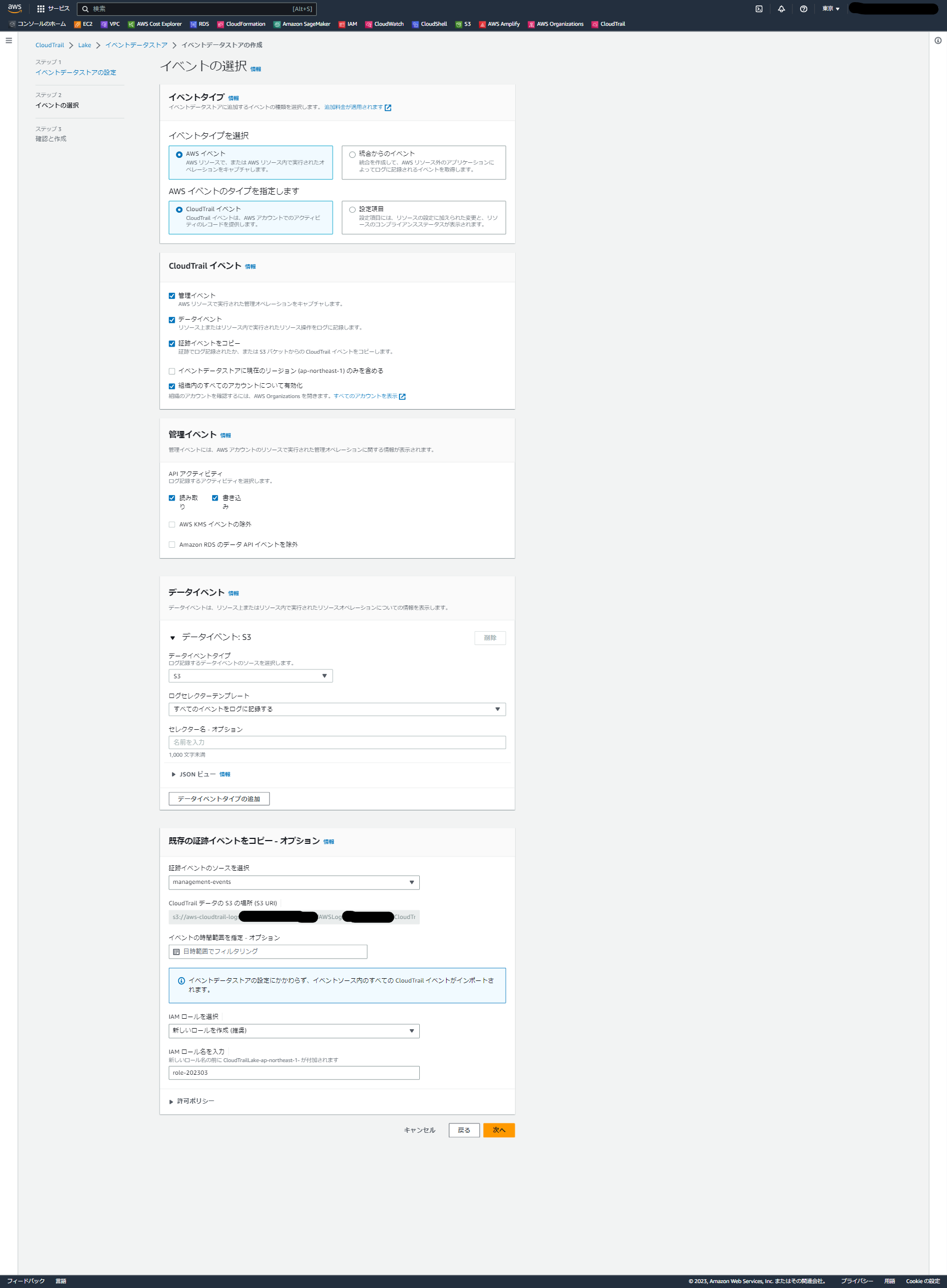
イベントデータストアの作成
確認画面で設定値を確認し、問題なければ「イベントデータストアの作成」を選択します。
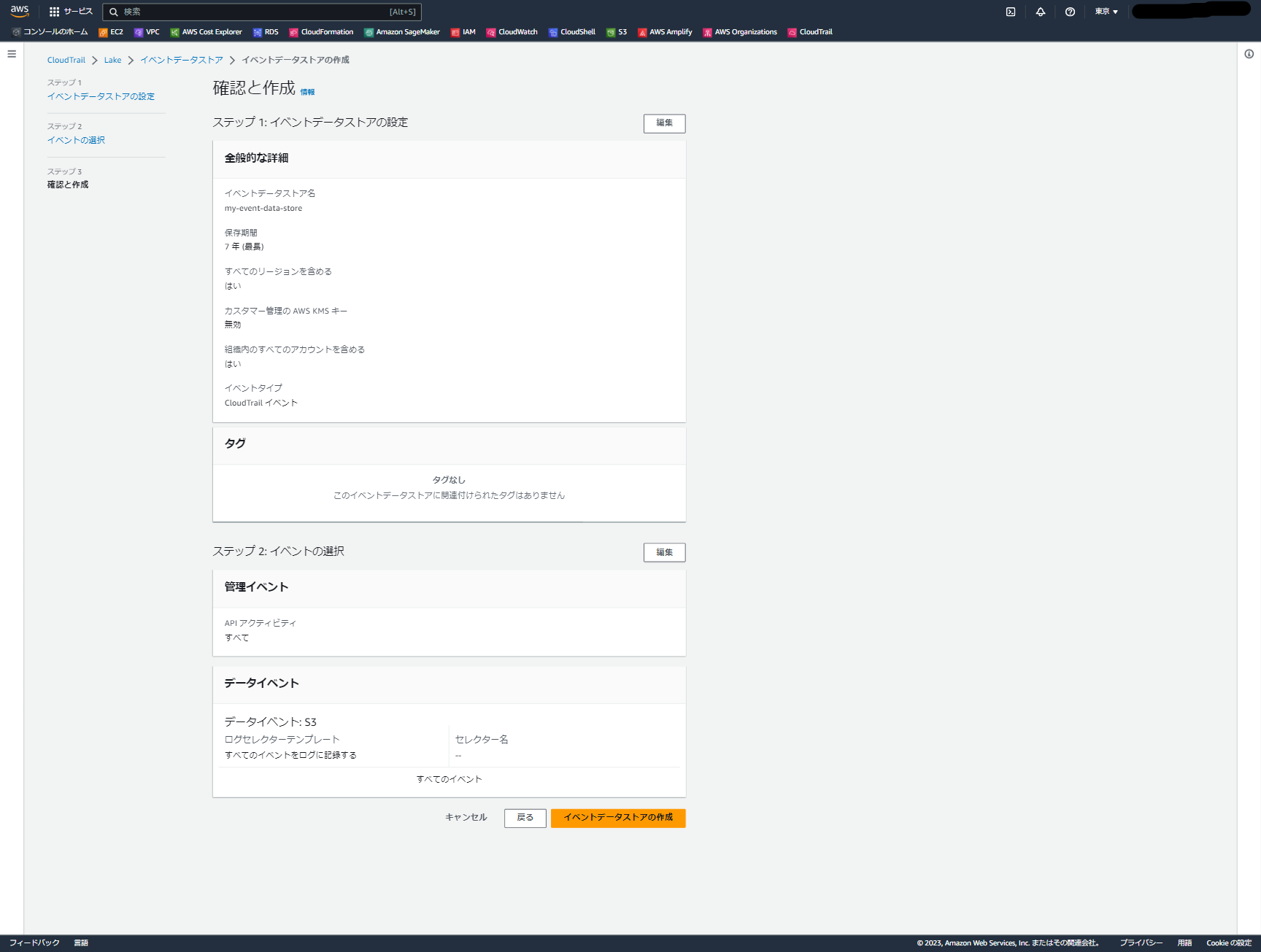
少し待つと画面が遷移し、「インポートリクエストを正常に作成しました」という表示が出ます。
上では細かく各項目を説明したため長く感じたかもしれませんが、デフォルト設定がほとんどなので、実際に操作してみると数分程度で選択しきれると思います。とても簡単です。
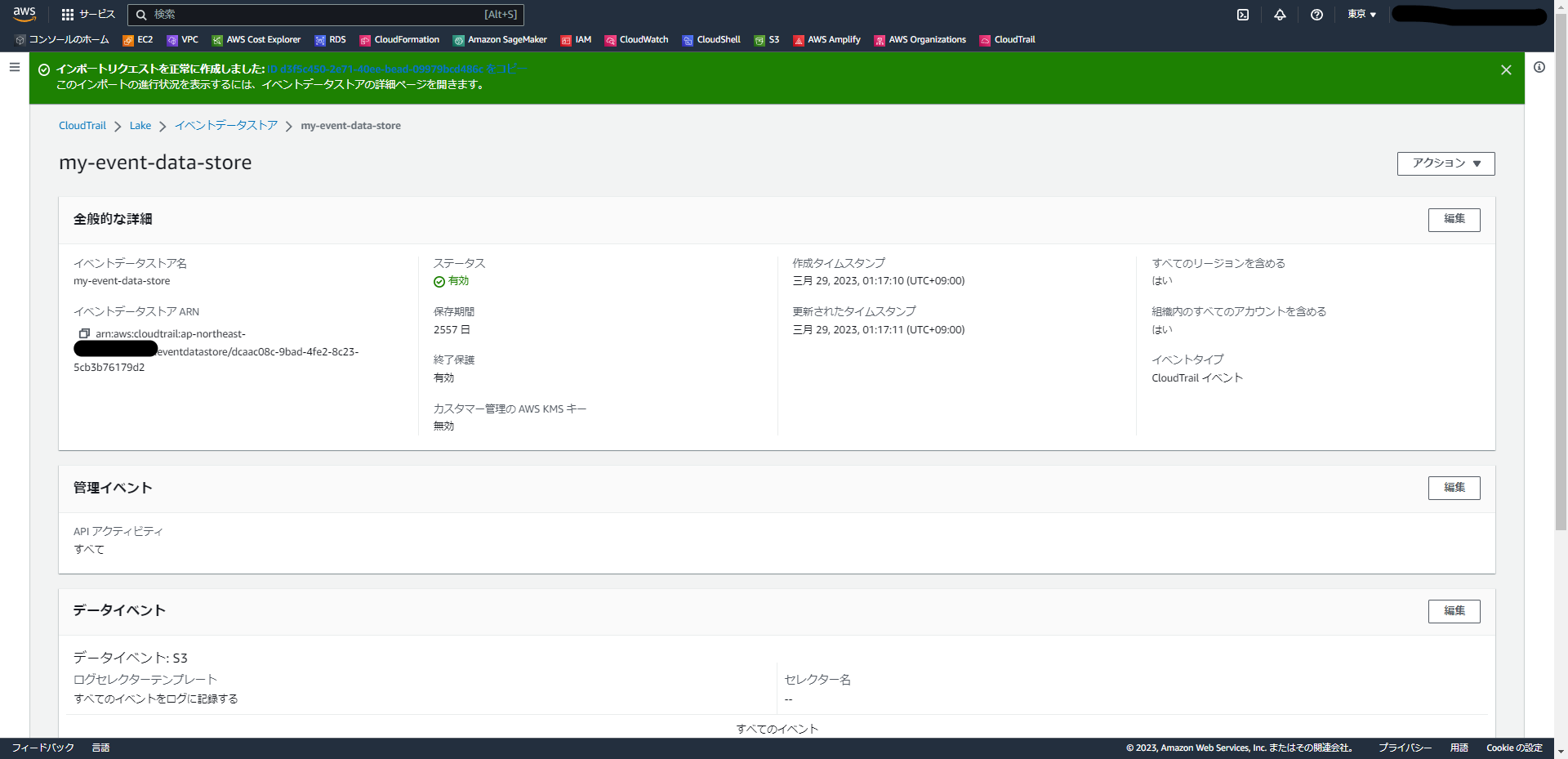
補足:
こちらの画面の下で、「イベントのコピーステータス」という箇所があります。
最初は「開始中」になっていますが、その後すぐに「進行中」になります。その後、私の環境では15分程度ですべてのコピーが完了し、「完了済み」になります。
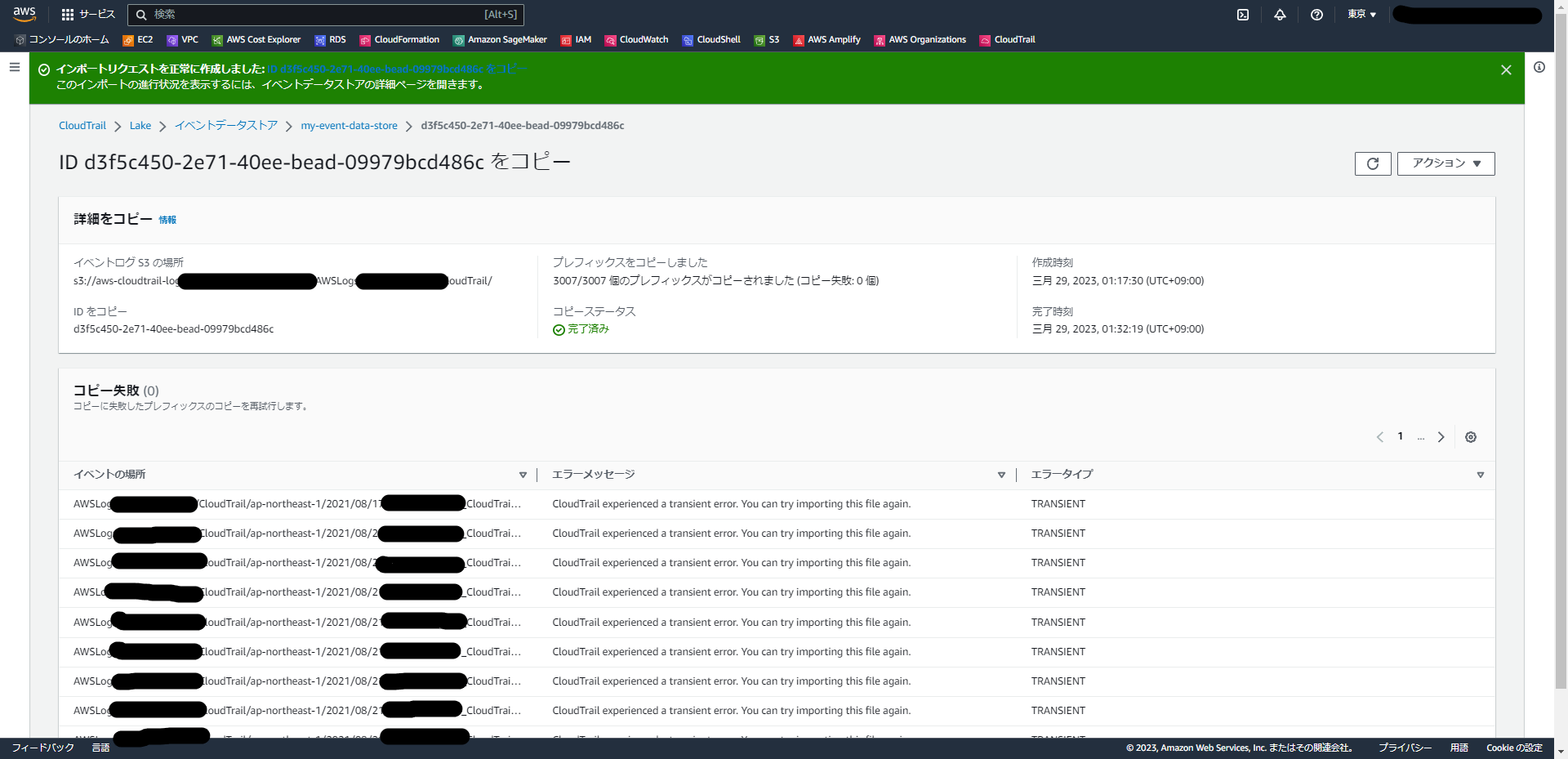
こちらは、クリックすることで詳細を見ることができました。「コピー失敗」というエラーが多く出て焦りましたが、再試行してエラーなしで完了しているようです。
クエリ画面
ログ
それではログを確認してみましょう。
「クエリを実行」という画面からクエリ実行ページに移動できます。
クエリ実行ページはAthenaによく似た画面で、もともとAthenaを使ってログ検索を実施していた方であればすんなり使い始められそうです。
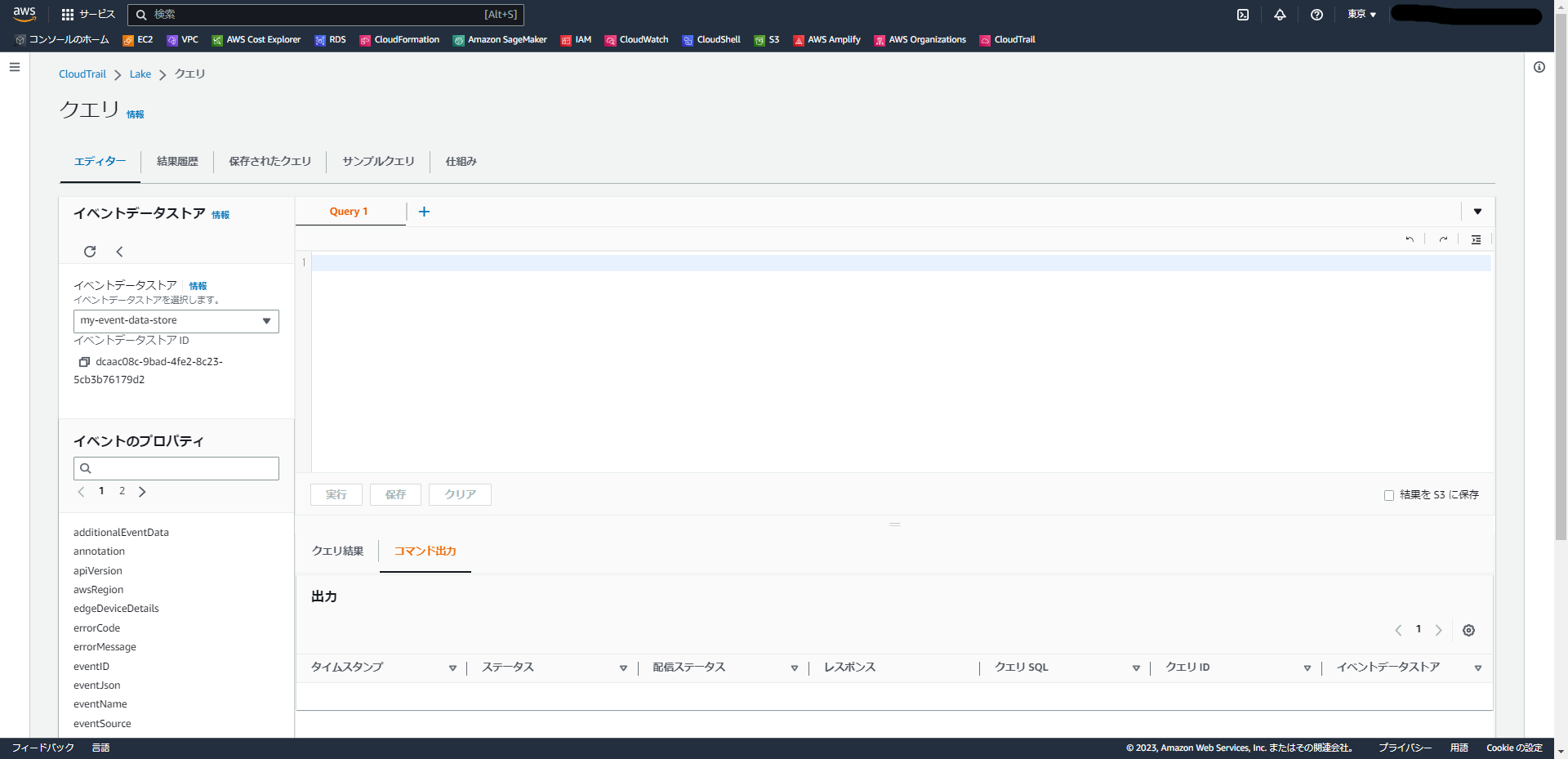
利用するクエリは「CloudTrail Lake SQL」という言語を用いるようです。
公式ドキュメントを読む限り、ログ検索で使い慣れたSELECT文は一通りサポートされていそうですね。
まずはログを見てみないことには始まりませんので、新しいいくつかのイベントを取得してみようと思います。
こういったときついつい気軽に SELECT * FROM テーブル名 を投げたくなってしまうところなのですが、ドキュメントにこんな記載があります。
無制限のクエリ (SELECT * FROM edsID など) は、イベントデータストア内のすべてのデータをスキャンします。
コストを抑えるため、クエリに開始および終了 eventTime タイムスタンプを追加することで、クエリを制限することをお勧めします。
ということで、直近数日に絞って検索をしてみましょう。
SELECT *
FROM eds-ID -- イベントデータストア IDは各環境でIDを指定してください。
WHERE
eventtime >='2023-03-27 00:00:00'
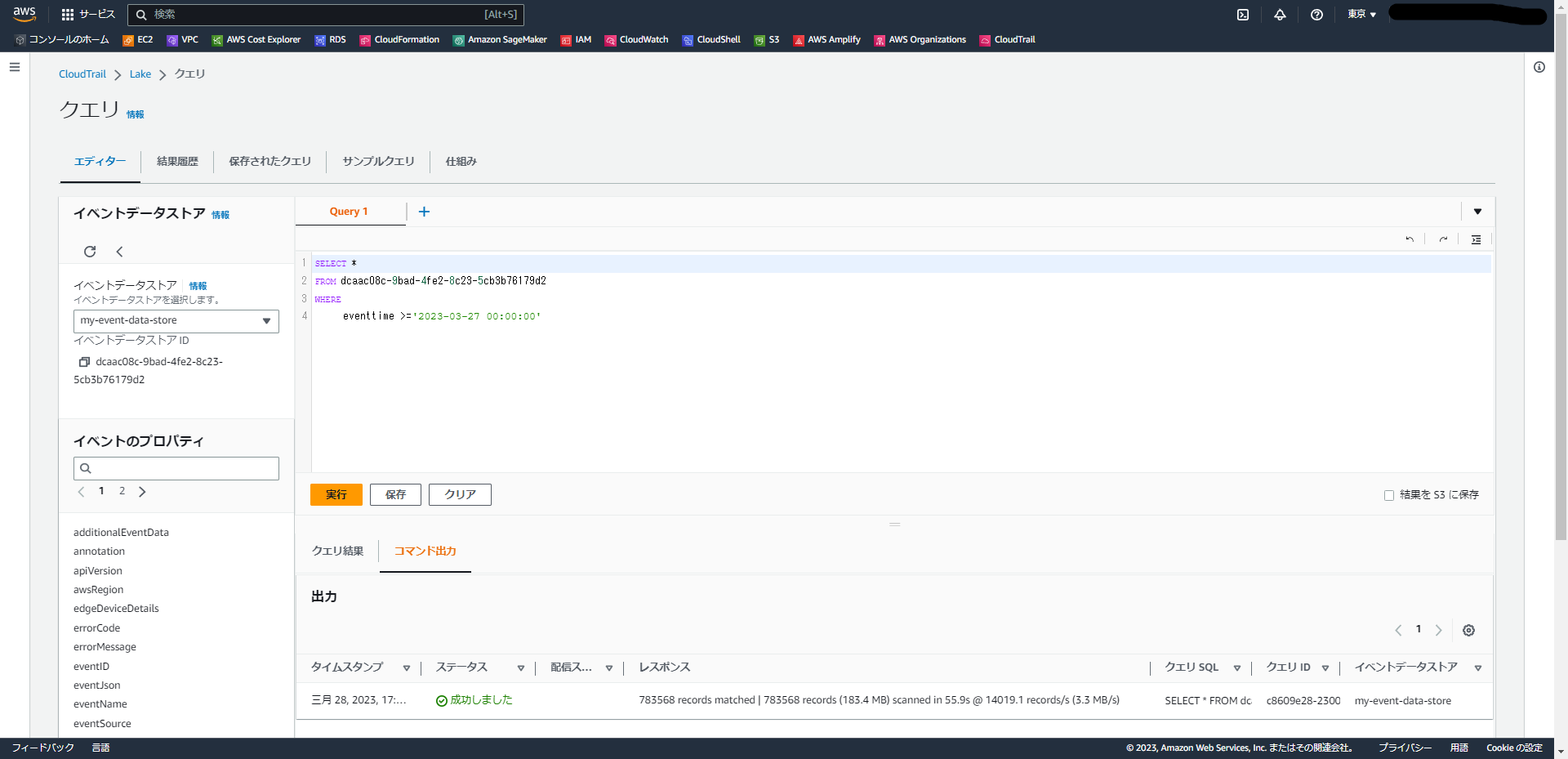
この環境ではデータイベントを有効にしているためか、数日間のログに絞ってもかなりの量がありますね。
ですが、一分ほどで結果が帰ってきまして、ログを検索することができました。
となりの「クエリ結果」タブで結果を確認することができます。とても簡単ですね。
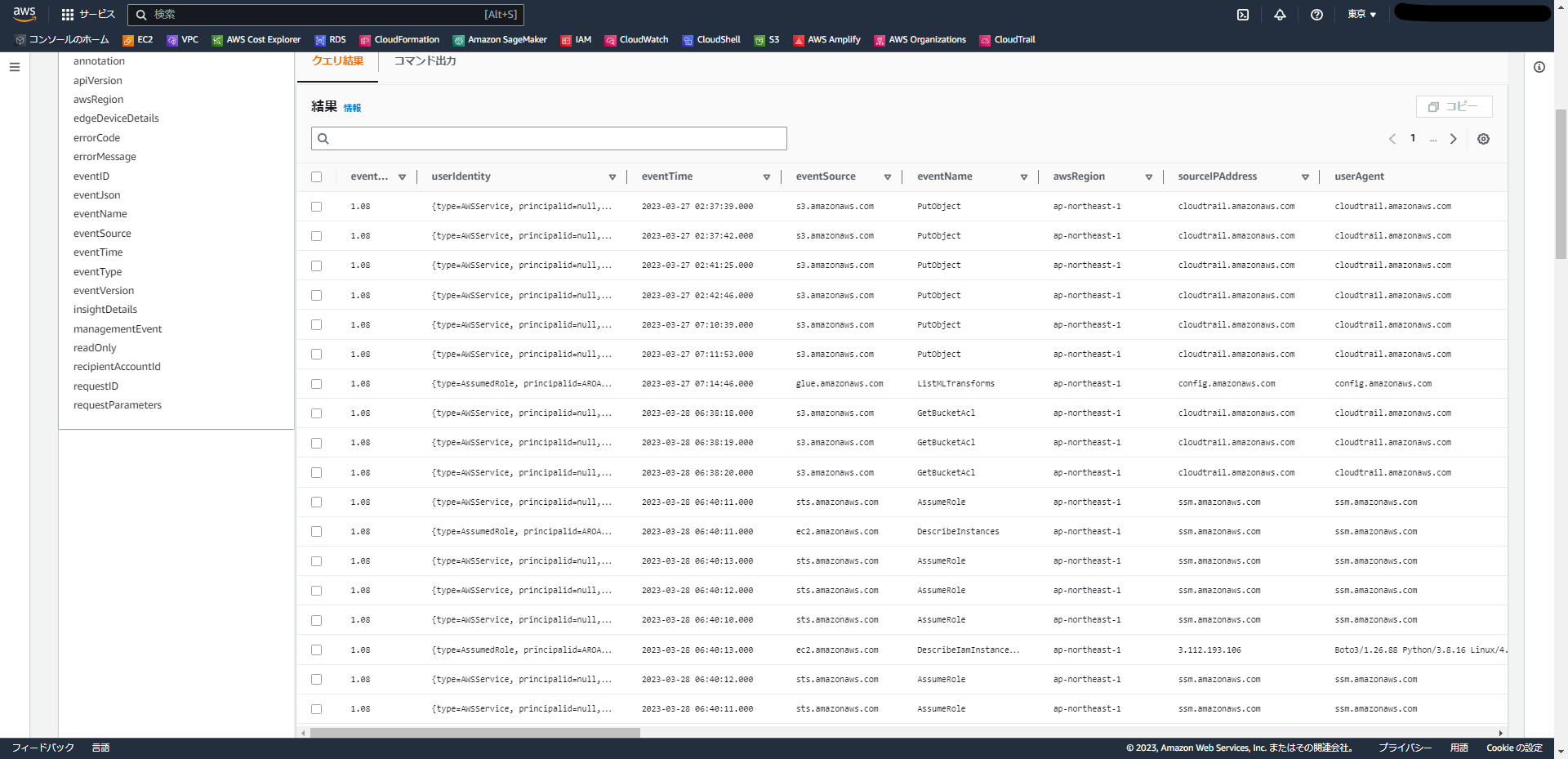
画面上「サンプルクエリ」タブの中には様々なシチュエーションで使えるサンプルクエリが格納されています。
また、公式ドキュメントでもいくつかのサンプルクエリが案内されていますので、そちらをご参照いただければと思います。
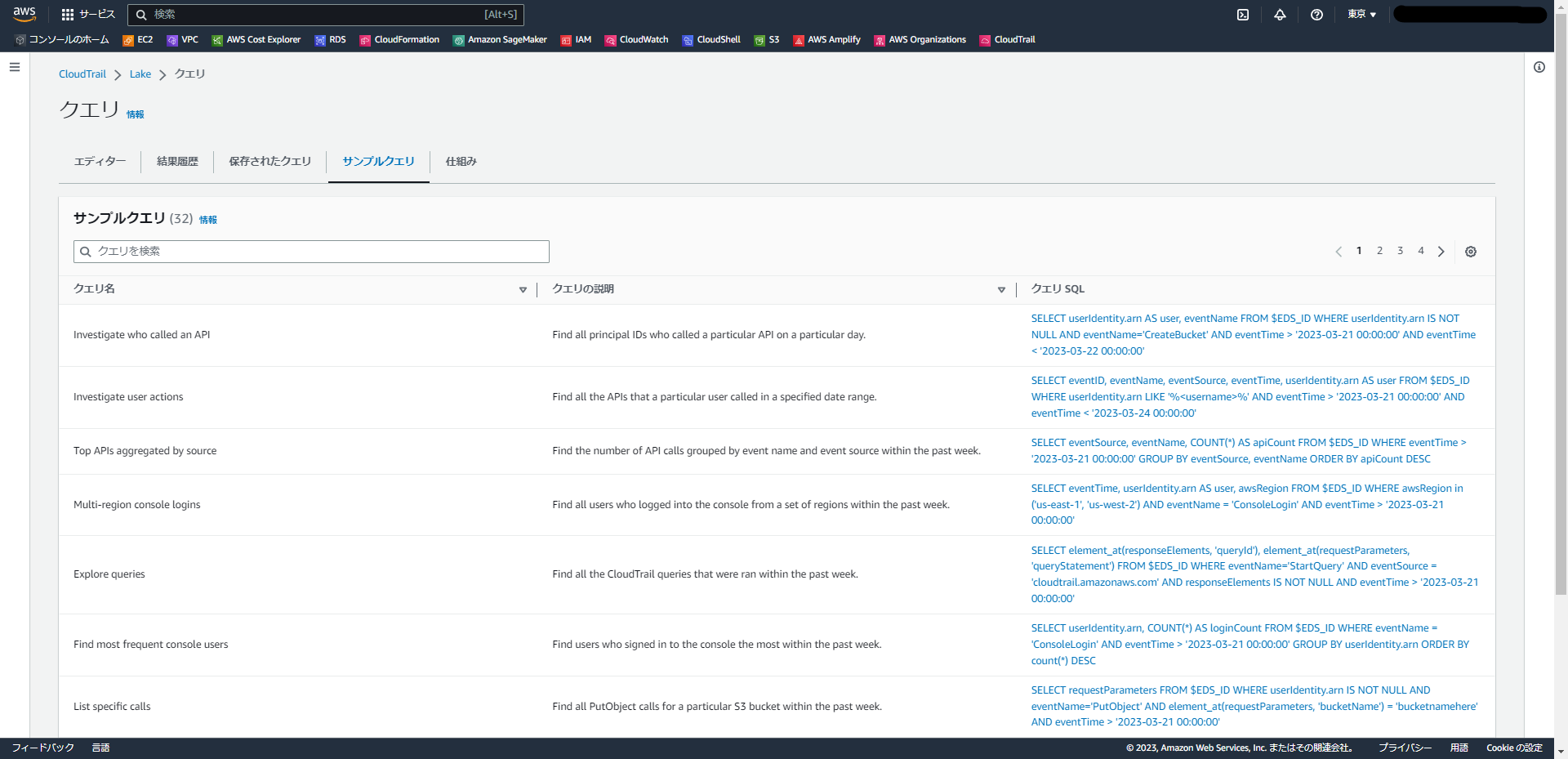
ということで、簡単でしたが使い方の紹介は以上になります。
おまけ:SELECT句の違いによってスキャン量・クエリ時間が変わるか実験してみる
ログ集約・検索のサービスということでやはり気になるのが スキャン量の削減 と クエリ時間の高速化 ですよね。
AthenaによってCloudTrailのログを検索していた方からすると、CloudTrailログのパーティショニングといえば
「リージョン」「年・月・日」(+ マルチアカウント構成であれば「アカウント」)のようなケースが多いのではないかと思います。
CloudTrail Lakeにおけるログファイルの格納方法、特にパーティショニングについては、公式ドキュメントを確認する限りでは明確な情報がなさそうです。
ただ、公式ドキュメントには「Apache ORC形式に変換」というような記載がありましたので、少なくとも列形式では保管されているのではというところから、こんな実験をしてみました。
実験内容
①先ほど投げた「SELECT * 」のクエリを3回投げてみる
②FROM句・WHERE句は変更せず、SELECT句で抽出する列を絞ったクエリを用意し、そちらも3回投げてみる。
この二つのクエリで、データスキャン量/クエリ時間がどの程度変わるのか調べてみました。
※2~3回投げてみるのは、頻繁に投げられるクエリに対するキャッシュなどの仕組みがあるのでは?という点も併せて確認したい意図でした。
①のクエリ
SELECT *
FROM eds-ID -- イベントデータストア IDは各環境でIDを指定してください。
WHERE
eventtime >='2023-03-27 00:00:00'
②のクエリ
SELECT userIdentity, eventSource, eventName, errorMessage
FROM eds-ID -- イベントデータストア IDは各環境でIDを指定してください。
WHERE
eventtime >='2023-03-27 00:00:00'
結果
①のクエリ(SELECT *)
| クエリ | スキャン量 | 実行時間 |
|---|---|---|
| 1回目 | 183.5 MB | 51.6s |
| 2回目 | 183.5 MB | 54.3s |
| 3回目 | 183.8 MB | 56.2s |
| 平均 | 183.6 MB | 54.0s |
②のクエリ(SELECT userIdentity, eventSource, eventName, errorMessage)
| クエリ | スキャン量 | 実行時間 |
|---|---|---|
| 1回目 | 95.3 MB | 11.5s |
| 2回目 | 95.3 MB | 11.9s |
| 3回目 | 95.4 MB | 12.0s |
| 平均 | 95.3 MB | 11.8s |
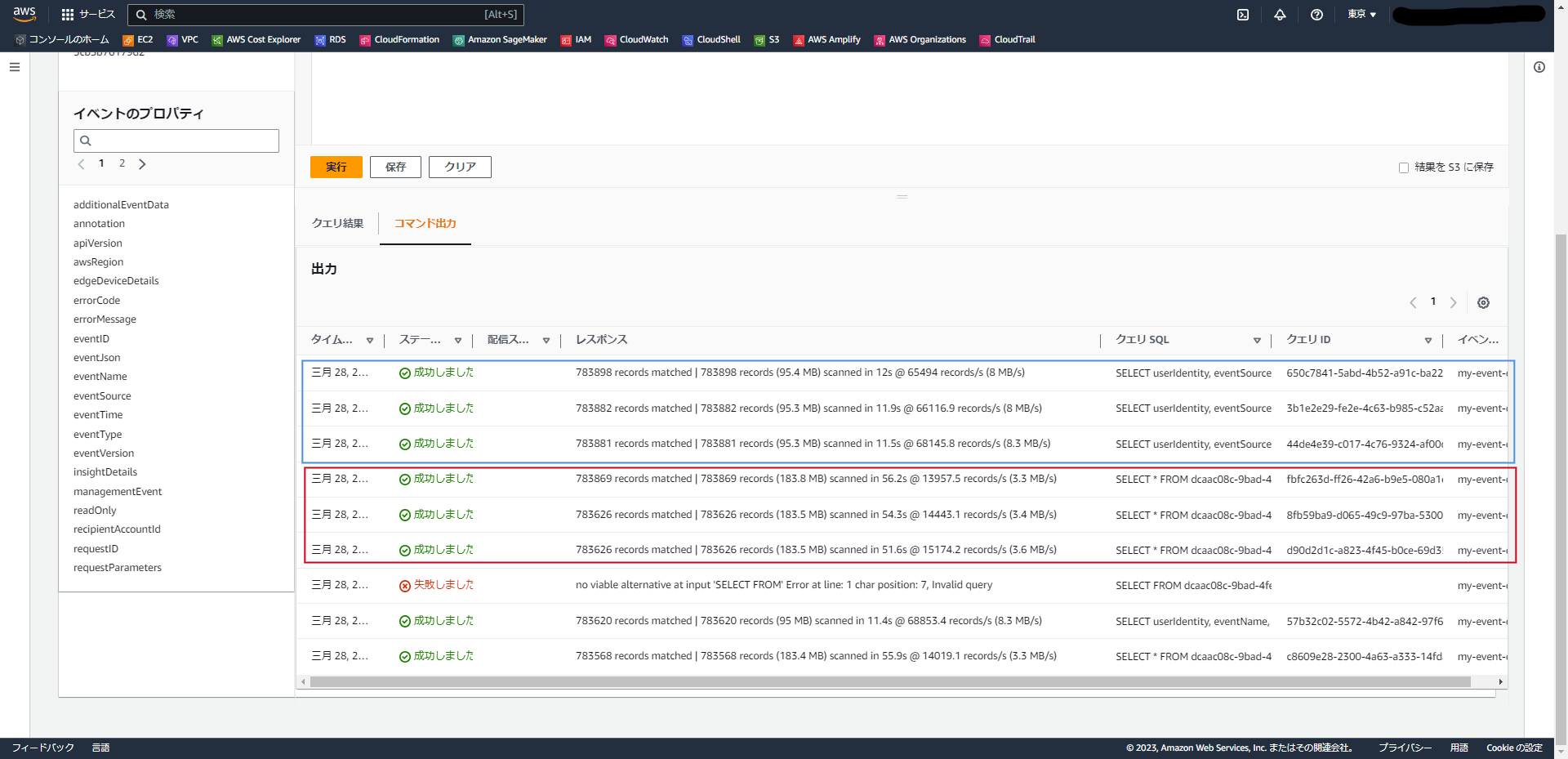
ということで、私の環境で調べた限りでは、SELECT句で表示する列を絞り込んだほうがスキャン量が削減でき、クエリ時間も短くなりそう という結果となりました。
※後になればなるほどスキャン量が増加・時間が伸びているのは、単にログが追加で発行されたためであると思います。
あくまでも簡易的な実験の結果ですし、AWS社公式の見解ではございませんので、ご参考までにとどめていただければと思います。
また、クエリの高速化に関してナレッジ等がある方がいらっしゃいましたら、ぜひコメントにて教えていただければと思います。
おわりに
今回は、CloudTrail Lakeというサービスを利用してみました。
非常に簡単に使えるサービスで、今後AWSの環境を構築する際の監査目的で、真っ先に検討に上がるサービスではないかと思います。
とはいえ、実運用上という面ではまだまだ見切れていない部分もありますので、実際に業務として利用できるかは今後も調査が必要ではないかと思います。
それでは、今回は以上にしたいと思います。
お読みいただきありがとうございました。
皆様もよきAWSライフをお過ごしください。
参考文献