はじめに
本記事では東京23区の人口の推移を可視化してみます。
筆者が東京都民のため対象を東京都としていますが、コードの一部を変えるだけであらゆる地域の人口推移を可視化することができます。
今回のコードはヘルシンキ大学が公開しているGISに関する教材を元にしています。
筆者はそちらの教材を勉強した後のアウトプットでこの記事を書いています。
GISについて勉強してみたい方はぜひそちらを使ってみてください。そちらの教材についての質問があればQiitaのコメントで議論させていただけると、筆者も勉強になり大変嬉しいです。
※本記事はGoogle Colab上で使用することを想定しています。ローカル環境でのコード実行時には事前に必要なライブラリのインストールが必要になります。
東京都の人口データとポリゴンデータをダウンロードする
夜間光と相関を調査する統計データはe-Statから取得します。
e-Statは日本の統計が閲覧できる政府統計のポータルサイトです。各省庁が公表する統計データがまとまっており、検索したり地図上に表示できたりします。
今回は以下のページから取得できる、市区町村ごとの人口データを使います。
地域選択で東京の23区、表示項目選択で「A1101 総人口(人)」を選択し、データをダウンロードします。ダウンロードするデータの形式を選択する画面で、「全ての調査年」を選択してください。
https://www.e-stat.go.jp/regional-statistics/ssdsview/prefectures
ダウンロードしたcsvは下の画像のようなデータになっています。

次に東京都の市区町村ごとのポリゴンデータを取得します。
ポリゴンデータとは、簡単に言えば緯度経度を持った形状のデータのことで、日本の市区町村ごとのポリゴンデータは国土交通省のサイトからダウンロードすることができます。令和4年の東京都のファイルをダウンロードし、zipを解凍すると下の画像のファイルが入っています。今回使うのはこの中でも拡張子が”.geojson”のもののため、このファイルをGoogle Driveにアップロードしてください。

東京23区の人口推移のグラフを作成する
必要なライブラリをインポートします。
!pip install geopandas
!pip install japanize_matplotlib
!pip install download
!pip install mapclassify
import mapclassify
import download
import japanize_matplotlib
import geopandas as gpd
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import folium
import os
上でe-Statからダウンロードした人口データのcsvをpandasで読み込みます。
fp = '人口データのCSVのファイルパスを入力してください。'
data = pd.read_csv(fp, encoding="CP932", skiprows=1)
data = data.loc[:, ["調査年", "地域", "地域 コード","A1101_総人口【人】"]]
data
下の画像のようなデータフレームを作成できました。
このままではグラフを作成する際の不都合が多いので、データを整えていく必要があります。例えば、デフォルトでは人口のcolumnは文字列として認識されており、グラフで扱うことができないため、型を変更する必要があります。

データフレームを整えていきます。
column名の変更、型の変更、”年度”の除去、”,”(カンマ)の除去を行っています。
# カラム名を変更する
data = data.rename(columns={'調査年': 'year', '地域': 'city', '地域 コード':'code','A1101_総人口【人】': 'pop'})
# 調査年のカラムの型に文字列を指定する
# "〜年度"を除去する
data['year'] = data['year'].astype(str)
data["year"] = data["year"].apply(lambda x:x[:-2])
# 地域のカラムの型に文字列を指定する
# 地域コードのカラムの型に文字列を指定する
data['city'] = data['city'].astype(str)
data['code'] = data['code'].astype(str)
# 人口のカラムの","(カンマ)を除去する
# 人口のカラムの型に整数型を指定する
data["pop"] = data["pop"].apply(lambda x:x.replace(',',''))
data['pop'] = data['pop'].astype(int)
data.head()
下の画像のようなデータフレームが完成しました。

次にグラフを表示するために、下の表のような、地域名がindexで調査年がcolumnのデータフレームを作成していきます。

“data”データフレームの”city”列と”code”列のユニークのデータフレーム(df_unique)を作成します。indexには”city”列を指定します。
df_unique = data[['city', 'code']].drop_duplicates().set_index('city')
df_unique
”city”列と”code”列のユニークのデータフレームが作成できました。

上で述べたように、地域名がindexで調査年がcolumnのデータフレームを作成していきます。元のデータフレーム(data)を順々に参照していき、対象の地域名と調査年のセルに人口の値を与えていきます。
for i in range(len(data)):
year = data.iloc[i]["year"]
city = data.iloc[i]["city"]
df_unique.loc[city,year] = data.iloc[i]["pop"]
df_unique
望んでいたデータフレームを作成することができました。

地域ごとの人口の時系列変化を折れ線グラフで表示します。
時系列で表示するために、yearのユニークを逆順に変換したり、df_uniqueを.transpose()で軸を入れ替えたりと処理を行っています。
years = data['year'].unique()[::-1]
fig, ax = plt.subplots(figsize=(12, 8))
df_unique[years].transpose().plot(ax=ax)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=10)
折れ線グラフを表示することができました。
1980年以降人口が変化していない地域が複数ある、2000年周辺から人口の増加が顕著になっている地域が複数ある、等の全体的な傾向は読み取れますが、このグラフから一つ一つの地域がどのような時系列変化をしているか読み取るのは少々骨が折れます。そこで、どの地域で人口が増加しているのかをわかりやすくするために、変化率を計算して地図に重ねて表示してみます。

人口データを地図に表示する
以下の3つを地図に表示してみます。
①1980年の人口
②2000年の人口
③2015年の人口
④1980年から2015年までの人口の増加率
⑤2000年から2015年までの人口の増加率
それらの値を格納するための空のデータフレーム(df)を作成しておきます。
df = pd.DataFrame(columns=['code', '1980', '2000', '2015', '1980-2015[%]', '2000-2015[%]'], index=cities)
df

作成しておいた空のデータフレーム(df)に値を与えていきます。
“code”は.unique()で取得したcodesから、①〜③の人口データは上で作成したデータフレーム(df_unique)から取得します。
for i in range(len(df)):
df.iloc[i]["code"] = codes[i]
df.iloc[i]["1980"] = df_unique.iloc[i]["1985"]
df.iloc[i]["2000"] = df_unique.iloc[i]["2000"]
df.iloc[i]["2015"] = df_unique.iloc[i]["2015"]
df.iloc[i]["1980-2015[%]"] = (df_unique.iloc[i]["2015"] - df_unique.iloc[i]["1980"]) / df_unique.iloc[i]["1980"]
df.iloc[i]["2000-2015[%]"] = (df_unique.iloc[i]["2015"] - df_unique.iloc[i]["2000"]) / df_unique.iloc[i]["2000"]
df
値を取得できました。

地図に表示する前に、それぞれの値を棒グラフで表示してみます。
この可視化方法であれば、どの地域がどの程度変化しているかはわかりやすいですね。
df.plot.barh(y="1980")

df.plot.barh(y="2000")

df.plot.barh(y="2015")

df.plot.barh(y="1980-2015[%]")

df.plot.barh(y="2000-2015[%]")

地図に表示するために、ポリゴンデータを取得します。
fp2 = "東京都のポリゴンデータ(.geojson)のファイルパスを貼り付けてください"
geo = gpd.read_file(fp2)
geo.head()
このように各地域ごとのポリゴンデータが取得できました。

上で表示した結果を見てみると、港区の行が3つあります。これは港区に飛び地があり、一つのポリゴンでは表せない形状をしているためです。これらを1つのポリゴンデータにまとめるためにデータを結合する必要があります。このような場合はGeopandasの.dissolve()を適用することでデータを結合できます。今回は行政区域コード(N03_007)をキーとしてデータを結合します。.dissolve()ではキーとしたcolumn列がindexとなってしまうため、.reset_index()でindexから外します。
dissolved = geo.dissolve(by="N03_007")
dissolved.reset_index(inplace=True)
dissolved
港区のgeometryがマルチポリゴンになり、1行にまとめられたことがわかります

人口のデータフレーム(df)とポリゴンデータのデータフレーム(dissolved)をマージします。地域コードであるdfのcodeとdissolvedのN03_007をキーにします。dissolvedのうち必要なのは”geometry”列のみのため、”geometry”列と”N03_007”列を抜き出してマージし、マージ後に”N03_007”列を削除します。
geodata = pd.merge(df, dissolved.loc[:, ["geometry", "N03_007"]], left_on="code", right_on="N03_007").drop(columns="N03_007")
geodata = gpd.GeoDataFrame(geodata)
geodata.head()
マージできました。

試しにプロットしてみると、東京23区のgeometryを取得できていることがわかります。
geodata.plot()
人口データのcolumnの型を変更します。
2015年の人口はint型、人口の増加列はfloat型にします。
geodata['1980'] = geodata['1980'].astype(int)
geodata['2000'] = geodata['2000'].astype(int)
geodata['2015'] = geodata['2015'].astype(int)
geodata['1980-2015[%]'] = geodata['1980-2015[%]'].astype(float)
geodata['2000-2015[%]'] = geodata['2000-2015[%]'].astype(float)
地図に人口データを表示します。
まずは各年の人口を表示します。
fig, ax = plt.subplots(1, figsize=(10, 8))
geodata.plot(ax=ax, column="1980", legend=True)

fig, ax = plt.subplots(1, figsize=(10, 8))
geodata.plot(ax=ax, column="2000", legend=True)
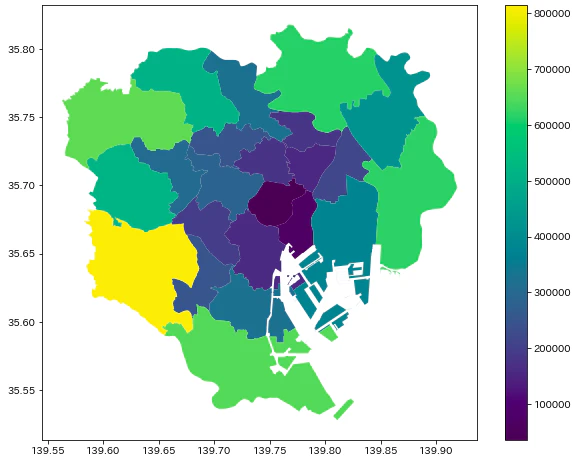
fig, ax = plt.subplots(1, figsize=(10, 8))
geodata.plot(ax=ax, column="2015", legend=True)

fig, ax = plt.subplots(1, figsize=(10, 8))
geodata.plot(ax=ax, column="1980-2015[%]", legend=True)

fig, ax = plt.subplots(1, figsize=(10, 8))
geodata.plot(ax=ax, column="2000-2015[%]", legend=True)

2015年の人口とは逆の傾向で、増加率は都心部ほど高いという結果になりました。
ここでは詳細な考察は行いませんが、都心部に高層マンションが増えていますし、不思議ではない気もします。
まとめ
今回は東京23区の人口データを地図に可視化してみました。
2015年の人口は都心部ほど少ないが、1980年と2000年から2015年の人口の増加率は都心部ほど高いという結果でした。今回取得したe-Statのデータは5年間隔で2015年までのデータしかなかったですが、2020年以降のデータも取得してみるとコロナウィルスの人口への影響が見られて面白いかもしれません。
今回も可視化したデータを使って何かを考察するといったことは行いませんでしたが、今後何か目的を決めて考察できればと思っています。
これからも勉強しながら成果を記事にしていこうと思うので、よろしくお願いします。