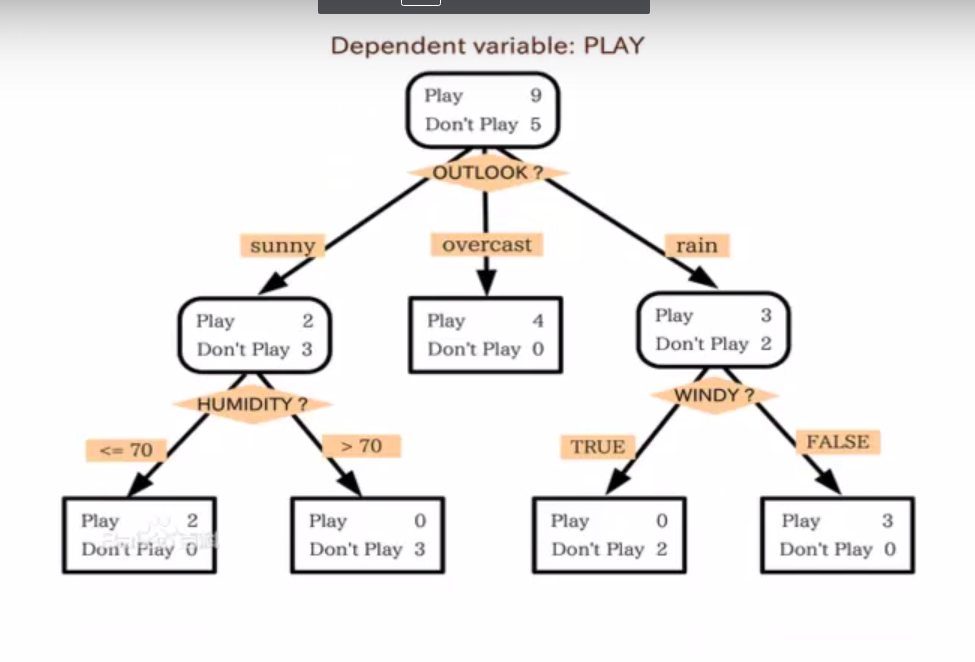
- 決定木を描いてみる。
お客さん情報によりもの買うか買わないかを予測します。
-
分析データ
分析データcsvファイルです。
項目はRID,age(年齢),income(収入),student(学生),credit_rating(信用度),Class_buys_computer(買う結果)
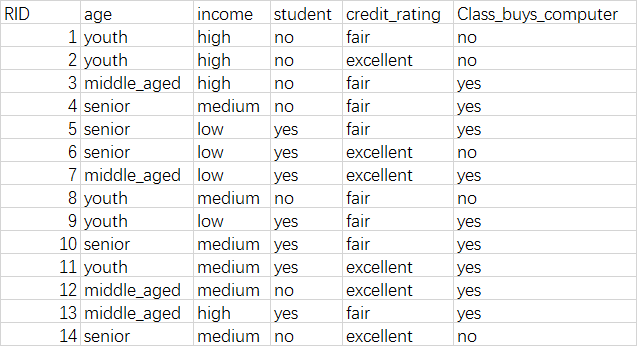
sklearnに分析ために転換が必要です。 -
計算方式
葉(端点)と根(root)の選択は重要でそれぞれの計算方法があります。
例: c4.5 cart id3
本例計算方式はid3です。参考:https://ja.wikipedia.org/wiki/ID3 -
利用したツール
python3 sklearn(機械学習計算用)
Graphviz (分析結果dotからpdf図に転換する)
作成されたPDF
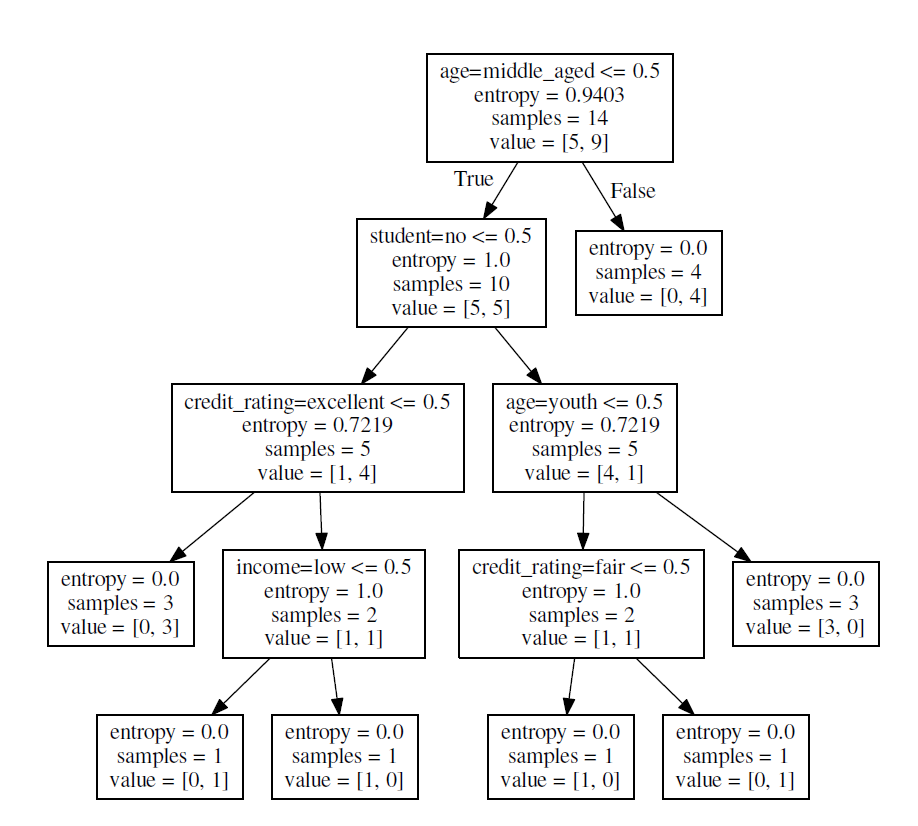
ソースコード
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO
with open('test_data.csv') as f:
f_csv = csv.reader(f)
headers = next(f_csv)
# csvデータを分析データに転換用
labelList = [] # 結果データ
featureList = [] # 属性データ
for row in f_csv:
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1, len(row) - 1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(labelList)
print(featureList)
# sklearnの分析データに転換する
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:" + str(dummyX))
print(vec.get_feature_names())
print("labellist: " + str(labelList))
# sklearnの結果データに転換する
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
# 計算方法を決まり、treeを構築する
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf:" + str(clf))
with open("test.dot", 'w') as f2:
# 結果データを出力する
f2 = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file = f2)
# dot ファイルからpdfに転換 コマンド: dot -T pdf test.dot -o output.pdf
# 仮に予想データを作成する
oneRowX = dummyX[0, :]
print("oneRowX:" + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX:" + str(newRowX))
# 予想データの結果
predictedY = clf.predict(newRowX)
print("predictedY:" + str(predictedY))