pandasでDataFrameを加工しているとindexを振り直す必要に出くわします。indexが定義されてないとかで怒られたり、またはテーブルの形がイビツになっていたり。index再設定のための備忘録です。
ライブラリとデータの準備
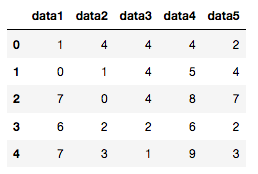
numpyの乱数処理で適当な値をDataFrameに入れる。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(low=0, high=10, size=(5, 5)), columns=['data1', 'data2', 'data3', 'data4', 'data5'])
別のcolumnをindexに指定する方法
このデータだとあまり違和感はないですが、csvから適当にreadしたデータだとkeycodeとなる値がindexではなく一つのcolumnとして入ってしまいます。そんな列を明示的にindexとして扱いたい場合には、set_index()を使います。
df.set_index("data1")
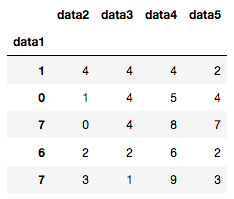
すると、set_index()で指定したcolumnをindexとして定義し直したDataFrameを作成することが可能になります。
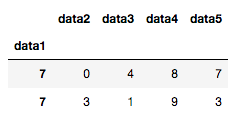
ただし、indexとして指定する列が一意かには注意が必要です。今回指定したdata1はそうではないため、index番号を呼び出してみると、以下のように複数のレコードが呼ばれてしまいます。
df.set_index("data1").loc[7,:]
indexを0から振り直す方法
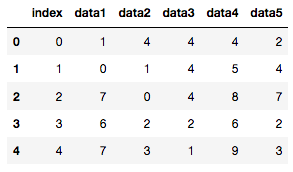
reset_index()を使えば良い。この場合には、これまでのindexが"index"という新しいcolumnとしてDataFrme内に加わることになる。
df.reset_index()
indexを1から振り直す方法
0からではなく1始まりのindexが欲しい時。例えば、DataFrameをキャプチャした結果をパワポに貼りたい時など。
他にも色々方法があるようですが(https://stackoverflow.com/questions/20167930/start-index-at-1-when-writing-pandas-dataframe-to-csv
)、以下の方法が最も簡単で忘れにくそうだなと感じました。
df.index = df.index + 1
indexといえども一つのobjectですので、単に1足す作業をするだけす。ただし、indexが数値として定義されている必要があります。reset_index()で作ったidnexなら良いですが、set_index()である列をindexに設定していた場合などは、その新しいindexが数値であるかをきにする必要があります。