pytorchで画像認識のモデルを作って。テストデータを評価する、って記事はたくさんありましたが、JPEGとかPNGとかの画像を実際に読み込んで予測してみた記事があんまりない気がしたので、まとめてみました。
今回のゴール
PNG画像をPyTorchで作った学習モデルに通して予測してみます。
モデルはMNISTの手書き数字認識を使います。
学習モデルの構築
Google ColaboratoryでPyTorchでMNISTを学習したモデルを保存し、それを読み出して使う簡単サンプル - 人工知能プログラミングやってくブログ
この記事を参考に学習モデルを作ります。
動かすと1,725,616バイトのmnist_cnn.ptができました。
機械学習モデルを使って予測する
PyTorch 1.1 Tutorials : 画像 : PyTorch を使用した画風変換 – PyTorch
この記事を参考にコードを書きました。
mnist_cnn.ptと手書き数字の画像ファイルを準備したら以下のコードを実行します。
モデルの定義・ロード
まずはモデルを定義してロードする
# 必要なモジュールを読み込む
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import datasets, transforms
from PIL import Image, ImageOps
# モデルの定義
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
device = torch.device("cpu")
model = 0
model = Net().to(device)
# 学習モデルをロードする
model.load_state_dict(torch.load("/適当なPath/mnist_cnn.pt", map_location=lambda storage, loc: storage))
model = model.eval()
画像の読み込み
次に画像を読み込みます。JPEGでもPNGでも大丈夫なはず。
# 画像ファイルを読み込む
image = Image.open("/適当なPath/mnist_9_70x70.png")
# convert('L')でグレースケールに変換する。
# そして画像のサイズを28ピクセル四方にリサイズします。
# さらにinvertで白黒変換する。画像は文字部分が0(黒)、背景が白(1)で学習元のデータと反対のため。
image = ImageOps.invert(image.convert('L')).resize((28,28))
# データの前処理の定義
# transforms.Normalize((0.1307,), (0.3081,)は学習元データと同様の正規化を行ってる。
# 0.1307を平均、0.3081を標準偏差に指定しています
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 元のモデルに合わせて次元を追加
image = transform(image).unsqueeze(0)
予測
最後に予測(Predict)します
# 予測を実施
output = model(image)
_, prediction = torch.max(output, 1)
# 結果を出力
print("result=" + str(prediction[0].item()))
実行するとこのように結果が表示されます。
入力画像
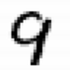
結果
result=9
まとめ
Chainerを触ったことあるけど、PyTorchは使い始めて2日の初心者ですが、ググって調べながら画像認識のコードを書いて動かすことができました。
スマートでないことしてるかもしれないので、指摘いただければうれしいです。
ちなみに、Flaskのアドベントカレンダーで画像認識アプリのネタを書こうと思ってPyTorchの部分のコード書いてたら一記事分くらいの量になったのでPyTorchのアドベントカレンダーにも登録してみました。
次はYOLOを動かしてみたい!