AzureのText Analytics APIでセンチメント分析(感情的なネガポジ)を行えることは Azure Text AnalyticsをPythonから使ってみた - Qiita の記事で説明しました。
今回は実際に映画のセリフを使ってセンチメント値がどのように推移するかを検証してみました。
元データ
今回は「風に谷のナウシカ」の全セリフを分析してみます(集め方は自分で考えましょう)
前処理
集めてきたセリフをまずGoogle翻訳で日本語から英語に翻訳します。
(日本語でやってみたけどText Analyticsの判定結果が大半が0.5で中立だったため)
翻訳したセリフをText Analytics APIで読める形に整形します。
各セリフは短かったので適当にシーンごとにまとめた上で、以下のような形に整形します。今回はPythonで作った簡単なスクリプトと手作業の半々で処理しました。
{'id': '1', 'language': 'en', 'text': '\n Another village died.\n \n '}
分析
Text Analytics APIを呼び出します。Pythonを使う場合のスクリプトは Azure Text AnalyticsをPythonから使ってみた - Qiita の記事を参照ください。
今回は映画の全セリフ、140件のテキストを一度に渡しましたが約4秒で結果が返ってきました。速い。
結果
センチメント値の高いトップ3(肯定的)です。
0.993096828
英語:'Whatever\n \n Please become a godparent of this child\n \n Always make a good breeze blow her\n \n Let\'s undertake\n \n I will give you a good name\n \n Thank you\n \n May you grow strong like a princess\n \n '
元の日本語:'どうかこの子の名付け親になって下さい\n いつもいい風がその子に吹きますように\n 引き受けよう\n よい名を贈らせてもらうよ\n ありがとう\n どうか姫様のように丈夫に育ちますように\n'
0.99137938
英語:'Mysterious place\n \n Hi\n \n Finally I came.\n \n How are you?\n \n '
元の日本語:'不思議な所\n やあ\n やっと見つけて来たよ\n 気分はどう?\n '},
0.990973055
英語:'What do you think?\n \n Yupa! It is a ship.\n \n boat?\n \n I will come.\n \n large!\n \n Wow\n \n '
日本語:'何ごとかね\n ユパ様!船です\n 船?\n 来るわ\n 大きい!\n ワ~\n '},
次にセンチメント値の低いトップ3(否定的)です。
0.003649145
英語:'There is no choice but to burn it\n \n This forest is already useless\n \n When it\'s too late\n \n The valley is only got into the rotting sea\n \n What\'s wrong?\n \n Forest who protected the reservoir for 300 years\n \n If you do not come shit down with me\n \n Well then, why not just hold on\n \n Let\'s also go\n \n '
元の日本語:'燃やすしかないよ\n この森はもうだめじゃ\n 手遅れになると谷は腐海にのみ込まれてしまう\n どうにかならんのかのう?\n 貯水池を300年も守ってくれた森じゃ\n くそ あいつらさえ来なければ\n こりゃ このままじゃおさまらんぞ\n わしらも行こう\n '},
0.006181002
英語:'Nausicaa\n \n I am scared of myself\n \n I do not know what to do with hatred.\n \n I do not want anyone to kill any more\n \n '
元の日本語:'ナウシカ\n 私自分が怖い\n 憎しみにかられて何をするかわからない\n もうだれも殺したくないのに\n'
0.006376058
英語:'I do not feel like being fucked like Baba\n \n It is the same thing\n \n I just wish for the mystery of the corrupt sea\n \n I just wish to solve it\n \n We humans are like this\n \n It seems to be ruined by rotting seas\n \n Is it a defined tribe?\n \n I want to find out\n \n to me\n \n I wish I could help Mr. Yupa\n \n '
元の日本語: 'ババ様からかわれては困る\n 同じことじゃろうが\n 私はただ腐海のなぞを解きたいと願っているだけだよ\n 我々人間はこのまま腐海にのまれて滅びるよう定められた種族なのか それを見きわめたいのだ\n 私にユパ様のお手伝いができればいいのに\n '
結構妥当な結果が出ています。
次にセンチメント値の推移をグラフにしてみました。映画中の盛り上がる部分、シリアスな部分の波のようなものが見えそうです。
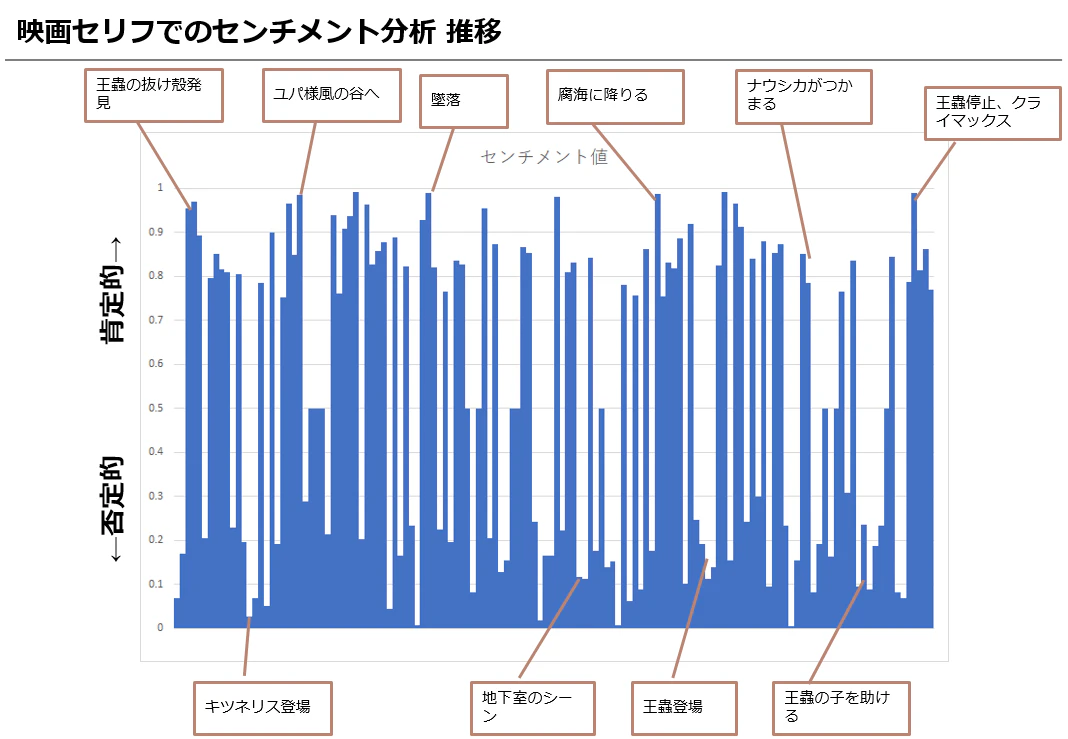
まとめ
今回は検証なのでデータの前処理は手作業の部分が多いですが、ちょっと工夫すれば自動化して、セリフさえあればすぐに何でも分析できそうです。
アイデアとAzureと少しのテクニックがあれば、映画のセリフとその評価の定量分析がすぐに簡単にできてびっくりするくらいでした。また、なにかアイデアを思い付いたら試してみたいです。