強化学習によるCavity Flow環境(CFD)の境界条件の制御 -その1 環境編-
この記事は建築環境/設備 Advent Calendar 2021の18日目の記事です。
本シリーズではタイトルの通り、CavityFlowの環境をCFDで構築し、強化学習で環境側のCavityFlowの任意の領域の流速を制御しようというお話です。強化学習やCFDの説明は長くなるので割愛しますが、強化学習は、ある状態Sにおいて様々な行動(制御)選択肢Aの中から、ある目的(報酬)を達成するための行動を決定するプロセスを学習していくものです。詳しくはWikipedia等を参考にしてください。
本記事では強化学習の環境側の実装を解説します。
QuickLinks
- 環境編(本記事)
エージェント編学習編
問題設定
環境側はbarbagroup/CFDPythonを参考にPythonにて2DのCavityFlowの非定常計算(Step 11 —Solves the Navier-Stokes equation for 2D cavity flow.)を強化学習の環境とします。
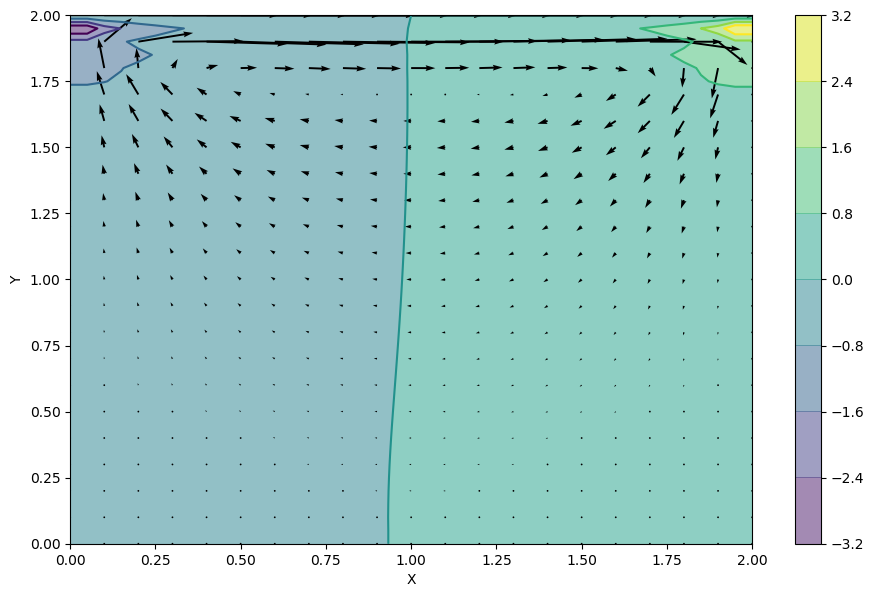
状態(State: s)
- 代表点(7点)の風速(0.0~1.0 m/s)
- TimeStep(0~250)
行動(Action: a)
- CFDの境界条件を操作(0.0 ~ 5.0 m/s) -> MAX_VIN
報酬(Reward: r)
- 中心座標Cの風速
V_centerが0.2m/s±0.02m/sで報酬1がもらえるが、それ以外は報酬0 - 例外的に
Step<=100、までは助走期間とし、その間の報酬は0
実装
CavityFlowのシミュレータ
こちらのipynbファイルを元にクラスを作っていくだけです。
import numpy as np
from sklearn.preprocessing import MinMaxScaler
class CavityFlow:
"""Cavity Flow with Navier-Stokes
https://nbviewer.org/github/barbagroup/CFDPython/blob/master/lessons/14_Step_11.ipynb
"""
MAX_VIN = 5.0
NX = 41
NY = 41
NT = 250
RHO = 1
NU = .1
DT = .005
SENSOR = np.array([[10, 10], [10, 20], [10, 30], [10, 38], [20, 10], [20, 30], [20, 38], ])
STATES_MIN_MAX = np.array([[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, NT]])
ACTIONS_MIN_MAX = np.array([[0.0, 5.0]])
TX = 20
TY = 20
def __init__(self):
self.time = 0
self.u, self.v = np.zeros((self.NY, self.NX)), np.zeros((self.NY, self.NX))
self.p, self.b = np.zeros((self.NY, self.NX)), np.zeros((self.NY, self.NX))
self.X, self.Y = np.meshgrid(np.linspace(0, 2, self.NX), np.linspace(0, 2, self.NY))
self.DX, self.DY = 2 / (self.NX - 1), 2 / (self.NY - 1)
self.PX, self.PY = self.SENSOR.T[0], self.SENSOR.T[1]
self.__scaler_states = MinMaxScaler(feature_range=(-1, 1))
self.__scaler_states.fit(self.STATES_MIN_MAX)
self.__scaler_actions = MinMaxScaler(feature_range=(-1, 1))
self.__scaler_actions.fit(self.ACTIONS_MIN_MAX.T)
def step(self, actions: np.ndarray):
un = self.u.copy()
vn = self.v.copy()
self.b = self.build_up_b(self.b, self.RHO, self.DT, self.u, self.v, self.DX, self.DY)
self.p = self.pressure_poisson(self.p, self.DX, self.DY, self.b)
self.u[1:-1, 1:-1] = (un[1:-1, 1:-1] -
un[1:-1, 1:-1] * self.DT / self.DX *
(un[1:-1, 1:-1] - un[1:-1, 0:-2]) -
vn[1:-1, 1:-1] * self.DT / self.DY *
(un[1:-1, 1:-1] - un[0:-2, 1:-1]) -
self.DT / (2 * self.RHO * self.DX) * (self.p[1:-1, 2:] - self.p[1:-1, 0:-2]) +
self.NU * (self.DT / self.DX**2 *
(un[1:-1, 2:] - 2 * un[1:-1, 1:-1] + un[1:-1, 0:-2]) +
self.DT / self.DY**2 *
(un[2:, 1:-1] - 2 * un[1:-1, 1:-1] + un[0:-2, 1:-1])))
self.v[1:-1, 1:-1] = (vn[1:-1, 1:-1] -
un[1:-1, 1:-1] * self.DT / self.DX *
(vn[1:-1, 1:-1] - vn[1:-1, 0:-2]) -
vn[1:-1, 1:-1] * self.DT / self.DY *
(vn[1:-1, 1:-1] - vn[0:-2, 1:-1]) -
self.DT / (2 * self.RHO * self.DY) * (self.p[2:, 1:-1] - self.p[0:-2, 1:-1]) +
self.NU * (self.DT / self.DX**2 *
(vn[1:-1, 2:] - 2 * vn[1:-1, 1:-1] + vn[1:-1, 0:-2]) +
self.DT / self.DY**2 *
(vn[2:, 1:-1] - 2 * vn[1:-1, 1:-1] + vn[0:-2, 1:-1])))
self.u[0, :] = 0
self.u[:, 0] = 0
self.u[:, -1] = 0
self.u[-1, :] = actions # set velocity on cavity lid equal to 1
self.v[0, :] = 0
self.v[-1, :] = 0
self.v[:, 0] = 0
self.v[:, -1] = 0
self.time += self.DT
def get_info(self):
terminal = self.time + self.DT * 0.05 >= self.NT * self.DT
states = np.zeros(0)
states = np.concatenate([states,
np.linalg.norm(np.vstack((self.u[self.PX, self.PY], self.v[self.PX, self.PY])).T, ord=2, axis=1)])
states = np.hstack([states, np.array(self.time)])
velocity = np.linalg.norm([self.u[self.TX, self.TY], self.v[self.TX, self.TY]], ord=2)
return terminal, states.astype(float).flatten(), float(velocity)
@staticmethod
def build_up_b(b, rho, dt, u, v, dx, dy):
b[1:-1, 1:-1] = (rho * (1 / dt *
((u[1:-1, 2:] - u[1:-1, 0:-2]) /
(2 * dx) + (v[2:, 1:-1] - v[0:-2, 1:-1]) / (2 * dy)) -
((u[1:-1, 2:] - u[1:-1, 0:-2]) / (2 * dx))**2 -
2 * ((u[2:, 1:-1] - u[0:-2, 1:-1]) / (2 * dy) *
(v[1:-1, 2:] - v[1:-1, 0:-2]) / (2 * dx)) -
((v[2:, 1:-1] - v[0:-2, 1:-1]) / (2 * dy))**2))
return b
@staticmethod
def pressure_poisson(p, dx, dy, b):
pn = np.empty_like(p)
pn = p.copy()
for _ in range(N_ITERATION_POISSON):
pn = p.copy()
p[1:-1, 1:-1] = (((pn[1:-1, 2:] + pn[1:-1, 0:-2]) * dy**2 +
(pn[2:, 1:-1] + pn[0:-2, 1:-1]) * dx**2) /
(2 * (dx**2 + dy**2)) -
dx**2 * dy**2 / (2 * (dx**2 + dy**2)) *
b[1:-1, 1:-1])
p[:, -1] = p[:, -2] # dp/dx = 0 at x = 2
p[0, :] = p[1, :] # dp/dy = 0 at y = 0
p[:, 0] = p[:, 1] # dp/dx = 0 at x = 0
p[-1, :] = 0 # p = 0 at y = 2
return p
@property
def scaler_states(self):
return self.__scaler_states
@property
def scaler_actions(self):
return self.__scaler_actions
特筆すべき点は、stepメソッドでactionを受け取ったあとに境界条件となる境界面の流速を固定している点です。これにより強化学習のエージェントが決定した行動を制御値としてCFD側を制御することができます。
self.u[-1, :] = actions
Gym
強化学習のエージェント側は Stable-Baselines3 のライブラリを使用する予定なので、このライブラリに適した環境のクラスを作成していきます。Stable-Baselines3 のカスタム環境のドキュメントにはgym.Envのクラスを継承したカスタムのクラスを定義するように記述されていますので、これに習い実装します。
import numpy as np
import gym
from gym import spaces
class CustomEnv(gym.Env):
def __init__(self):
super(CustomEnv, self).__init__()
self.cavity_flow = CavityFlow()
_, s, _ = self.cavity_flow.get_info()
self.num_action = 1
self.num_states = len(s)
self.max_episode_timesteps = self.cavity_flow.NT
self.action_space = spaces.Box(low=-1.0, high=1.0,
shape=(self.num_action,))
self.observation_space = spaces.Box(low=-1.0, high=1.0,
shape=(self.num_states,))
self.steps = 0
self.TARGET_V_CENTER = 0.2
def reset(self) -> np.ndarray:
self.steps = 0
self.cavity_flow = CavityFlow()
# Return env information
terminal, states, v_center = self.cavity_flow.get_info()
states = np.clip(self.cavity_flow.scaler_states.transform(states.reshape(1, -1)).flatten(), 0.0, 1.0)
self.reward_sum = 0.0
return states
def step(self, actions: np.ndarray):
actions = self.cavity_flow.scaler_actions.inverse_transform(actions.reshape(1, -1)).flatten()
self.cavity_flow.step(actions)
terminal, states, v_center = self.cavity_flow.get_info()
if self.TARGET_V_CENTER * 0.9 <= v_center <= self.TARGET_V_CENTER * 1.1:
reward = 1.0
else:
reward = 0.0
if self.steps <= 100:
reward = 0.0
states = np.clip(self.cavity_flow.scaler_states.transform(states.reshape(1, -1)).flatten(), 0.0, 1.0)
if terminal:
print(f"Accumulated Reward={self.reward_sum}")
self.steps += 1
self.reward_sum += reward
return states, reward, terminal, {}
def render(self, mode='human'):
pass
def close(self):
pass
-
__init__ではCavityFlowのインスタンスの作成や状態S, 行動Aの数やタイプ(離散値 or 連続値)を定義します。 -
resetはエージェント側からメソッドを呼び出されるとCavityFlowのインスタンスの初期化、初期値を取得し初期状態S0を返します。 -
stepはエージェント側から行動aを引数として呼び出され、エージェントが指示した行動をもとにシミュレータへ操作値を送り、1Stepすすめ、その時の状態St+1statesやエピソード終端のブール値terminal、報酬計算に用いる代表点の流速v_centerを取得します。その後、報酬を計算した上で、states,reward,terminalを返します。
最後に
簡素な解説になりましたが、強化学習の環境側の実装は以上となります。次回はエージェント側の実装を記事にしようと思います。尚、最終的にはDockerのコンテナ内で学習や実行テストが行えるように環境構築ファイル等をGithubのリポジトリにて公開予定です。