厚労省の公表値を取得します
取り込みに使ったサイトの表がこちら↓です。
https://www.mhlw.go.jp/stf/covid-19/kokunainohasseijoukyou.html#h2_1
(厚生労働省のサイト)

この表を、Googleスプレッドシート経由でGoogle Data Portalに取り込み、以下↓のように表示させました。

元の表では1つのセルに「累計」と「前日比」の値が入っています。
後で集計に使えるように、それぞれの値を「数字」として別の列に分けています。
簡単にできると思ったのですが、予想以上に手間がかかりました。
正確に言うと、Googleスプレッドシートで関数と正規表現を使い、整形した形で取り込むのに時間がかかりました。
Googleスプレッドシートに取り込みます
IMPORTDATA関数を使いました。
=IMPORTDATA("https://www.mhlw.go.jp/content/current_situation.csv")
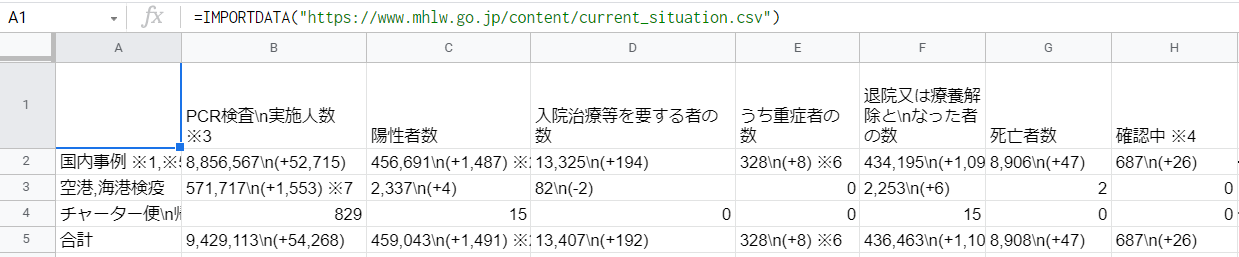
上記の各セルを参照し、以下のように整形します。

最初の列と行の項目は手入力です。
数値の取り出し方は、例えば、「##PCR検査実施人数」列のJ2の値は、IMPORTDATA関数で取り込んだB2セルの値を、関数と正規表現を使い参照しています。
※正規表現を普段あまり使わないので、あまりこなれた方法ではないと思いますが、ご容赦ください。
=REGEXREPLACE(REGEXEXTRACT(B2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
REGEXEXTRACT
正規表現に従って、一致する部分文字列を取り出します。
構文
REGEXEXTRACT(テキスト, 正規表現)
REGEXREPLACE
正規表現を使用して、テキスト文字列の一部を別のテキスト文字列に置き換えます。
構文
REGEXREPLACE(テキスト, 正規表現, 置換)
こういうフローです。
REGEXEXTRACTで 8,856,567\n(+52,715) から「8,856,567\n(+」を取り出します。
REGEXREPLACEで 「\n(+」を「""」に置き換えることで、「8,856,567」を残します。
その他使った関数と正規表現例です
| 正規表現 | 概要 |
|---|---|
| . | 任意の1文字 に一致します。 |
| +? | 直前の文字が 1回以上 繰り返す場合に一致します。条件に合う最短の部分に一致します(最短一致)。 |
| [...] | 括弧に含まれるいずれか1文字に一致します |
| |(使う際は半角で) | いずれかの条件 (OR条件) として使われます。 |
| \ | 直後の文字を「エスケープ」します。 |
最初のパターンを少し変えることで各値を取り出しました。
J2:=REGEXREPLACE(REGEXEXTRACT(B2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
K2:=REGEXREPLACE(REGEXEXTRACT(B2,"(\+.+?[)])"),"[\\|n|(|+|,|)]","")
L2:=REGEXREPLACE(REGEXEXTRACT(C2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
M2:=REGEXREPLACE(REGEXEXTRACT(C2,"(\+.+?[)])"),"[\\|n|(|+|,|)]","")
N2:=REGEXREPLACE(REGEXEXTRACT(D2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
O2:=REGEXREPLACE(REGEXEXTRACT(D2,"((\+|\-).+?[)])"),"[\\|n|(|+|,|)]","")
P2:=REGEXREPLACE(REGEXEXTRACT(E2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
Q2:=REGEXREPLACE(REGEXEXTRACT(E2,"((\+|\-).+?[)])"),"[\\|n|(|+|,|)]","")
R2:=REGEXREPLACE(REGEXEXTRACT(F2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
S2:=REGEXREPLACE(REGEXEXTRACT(F2,"(\+.+?[)])"),"[\\|n|(|+|,|)]","")
T2:=REGEXREPLACE(REGEXEXTRACT(G2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
U2:=REGEXREPLACE(REGEXEXTRACT(G2,"(\+.+?[)])"),"[\\|n|(|+|,|)]","")
V2:=REGEXREPLACE(REGEXEXTRACT(H2,"(.+?[\n(+])"),"[\\|n|(|+|,|)]","")
W2:=REGEXREPLACE(REGEXEXTRACT(H2,"((\+|\-).+?[)])"),"[\\|n|(|+|,|)]","")
ただ、パターンが変わることがあり、これまで2回ほど正規表現の修正をしています。
Google Data Portalでスプレッドシートをインポートし、各項目を配置して冒頭の表を作成しました。

了