ツイート取得
『ドラゴンボール』シリーズの最新映画『ドラゴンボール超 スーパーヒーロー』が6月11日(土)から公開されました。
Twitterのツイートを「R」を使って調べてみました。
まず、「ドラゴンボール」を含むつぶやきを取得します。
library("twitteR")
tweets2 <- searchTwitter('ドラゴンボール', n = 10000, since = "2022-06-11" , lang="ja" , locale="ja")
class(tweets2)
[1] "list"
tweetsdf2 <- twListToDF(tweets2)
nrow(tweetsdf2)
[1] 10000
リツイートを外す
リツイートされたツイートを含めると特定のワードに偏ることが何度かあったので、外しました。
table(tweetsdf2$isRetweet) #◼️
FALSE TRUE
4398 5602
library(dplyr)
tweetsdf3 <- tweetsdf2 %>% filter(isRetweet %in% "FALSE")
nrow(tweetsdf3)
[1] 4398
テキストを形態素解析
テキストだけ抜き出し、結合して形態素解析をかけます。
texts <- tweetsdf3$text
class(texts)
[1] "character"
library(stringr) #◼️
library(magrittr)#◼️
テキストを一時ファイルに保存し、「RMeCab」を使います。
辞書には「NEologd」を使いました。
xfile <- tempfile() #◼️
write(texts3, xfile) #◼️
library(RMeCab)
#neologd利用
frq_Tw2 <- RMeCabFreq(xfile, dic = "//usr/local/lib/mecab/dic/ipadic/mecab-user-dict-seed.20200910.csv.dic")
frq_Tw2 %>% arrange(Freq) %>% tail(50)
フィルターで品詞を指定
いくつか試し、今回は「固有名詞」と「形容詞」に対し、別々に出現ワードををグラフ化することにしました。
#形容詞をピックアップ
frq4_Tw2 <- frq_Tw2 %>% filter(Info1 %in% "形容詞") #◼️
frq4_Tw2 %>% arrange(Freq) %>% tail(50) #確認 #◼️
frq4_Tw2a <- frq4_Tw2 %>% filter(Info2 %in% "自立") #◼️「自立」のみにしました
frq4_Tw2a %>% arrange(Freq) %>% tail(50) #確認 #◼️
10817 すごい 形容詞 自立 73
10848 よい 形容詞 自立 95
10905 楽しい 形容詞 自立 98
10786 いい 形容詞 自立 114
10831 ない 形容詞 自立 183
10869 可愛い 形容詞 自立 195
10940 良い 形容詞 自立 305
10961 面白い 形容詞 自立 379
#固有名詞をピックアップ
frq3_Tw2 <- frq_Tw2 %>% filter(Info2 %in% "固有名詞") #◼️
frq3_Tw2 %>% arrange(Freq) %>% tail(50) #確認 #◼️
#「HTTPS」と1文字を外す
frq3_Tw4 <- frq3_Tw2 %>% filter(Term != "HTTPS")
frq3_Tw4 %>% arrange(Freq) %>% tail() #確認 #◼️
<-
#Termが1文字の行を削除。まず、1文字ワードの行番号を抽出
index <- grep('..', frq3_Tw4[,1]) #◼️
index %>% tail(20) #元のソート順で何行目が選ばれたかを確認できる
frq3_Tw4[index,] %>% arrange(Freq) %>% tail(20) #確認 #◼️
frq3_Tw4a <- frq3_Tw4[index,]
frq3_Tw4a %>% arrange(Freq) %>% tail(20) #確認 #◼️
#突出している「DRAGON BALL 名詞 固有名詞 4528」も外す
frq3_Tw4a <- frq3_Tw4a %>% filter(Term != "DRAGON BALL")
frq3_Tw4a %>% arrange(Freq) %>% tail(20) #確認 #◼️
8991 ネタバレ 名詞 固有名詞 152
9044 ピッコロさん 名詞 固有名詞 190
8975 ドラゴンボール超 名詞 固有名詞 225
8912 チョンロ 名詞 固有名詞 240
7311 FAMILY 名詞 固有名詞 249
7792 SPY 名詞 固有名詞 262
9520 悟飯 名詞 固有名詞 342
8874 スーパーヒーロー 名詞 固有名詞 611
ggplot2
ggplot2でそれぞれ棒グラフを描きました。
#Info2 %in% "固有名詞"
frq4_Tw3 <- frq3_Tw2$Freq >= 20 #Freq20以上。TRUE、FALSEで返す
frq4_Tw4 <- frq3_Tw2[frq4_Tw3,]
frq4_Tw4 %>% arrange(Freq)
frq16_Tw2 <- frq4_Tw4
#この後下記のggplot2実行
#Info1 %in% "形容詞" & Info2 %in% "自立"
frq4_Tw3 <- frq4_Tw2a$Freq >= 20
frq4_Tw4 <- frq4_Tw2a[frq4_Tw3,]
frq4_Tw4 %>% arrange(Freq)
frq16_Tw2 <- frq4_Tw4
#この後下記のggplot2実行
#reorderは並び順指定
#stat="identity"はデータラベルつけるときに必要
#fill=ーFreqにすると値が大きいほど色が濃くなる
#coord_flip()を追加すると、x軸とy軸が入れ替わる
#geom_textとlabelで棒グラフにラベル(Freq)を追加
library(ggplot2)
par(family = "HiraKakuProN-W3")
ggplot(frq16_Tw2, aes(x=reorder(Term, Freq), y=Freq))+
geom_bar(aes(y=Freq,fill=-Freq),stat="identity") +
xlab("")+
theme_gray (base_family = "HiraKakuPro-W3") +
geom_text(aes(x=reorder(Term, Freq), y=Freq, label = Freq), hjust=1.3,colour = " white") +
coord_flip()


SPY FAMILY?
固有名詞の集計をして気になったのは「SPY」「FAMILY」というワードです。
Twitterで「ドラゴンボール」&「SPY FAMILY」と検索して、なんで紛れ込んで来たか察しはついたのですが、数字的な裏付けを取れないか探ってみました。
いろいろな条件で試し、シンプルに「ツイートにSPYを含む」条件で、これまでと同様の集計をすることで落ち着きました。
#「SPY」含む
tweetsdf2S <- tweetsdf2 %>% mutate(spy = str_detect(text, "SPY"))
tweetsdf2ST <- tweetsdf2S[tweetsdf2S$spy == "TRUE", ]
textsT <- tweetsdf2ST$text #◼️
texts3T<- paste(textsT, collapse = "") #◼️
#テキストを一時ファイルに
xfileT <- tempfile() #◼️
write(texts3T, xfileT) #◼️
#形態素解析
frq_Tw2T <- RMeCabFreq(xfileT, dic = "//usr/local/lib/mecab/dic/ipadic/mecab-user-dict-seed.20200910.csv.dic")
frq_Tw2T %>% arrange(Freq) %>% tail(50) #◼️
#使わないワードを外す(見栄えを意識)
frq2_Tw2T <- frq_Tw2T %>% filter(Term != "HTTPS")
frq2_Tw2T <- frq2_Tw2T %>% filter(Term != "co")
#記号を外す
frq3_Tw2T <- frq2_Tw2T%>% mutate(noun=str_match((Term), '[^\\W]+')) #◼️
frq3_Tw2T %>% head(10) #確認
#削除。na.omitでNA含む行を削除。
frq4_Tw2T <- na.omit(frq3_Tw2T) #◼️
frq4_Tw2T %>% arrange(Freq) %>% tail(10) #確認
#1文字ワードを外す
index <- grep('..', frq4_Tw2T[,1]) #◼️
frq5_Tw2T <- frq4_Tw2T[index,]
frq5_Tw2T %>% arrange(Freq) %>% tail(20) #確認 #◼️
#ggplot2のための準備
frqgg_Tw <- frq5_Tw2T$Freq >= 80
frqgg_Tw <- frq5_Tw2T[frqgg_Tw ,]
frq16_Tw2 <- frqgg_Tw
#ggplot2実行
par(family = "HiraKakuProN-W3")
ggplot(frq16_Tw2, aes(x=reorder(Term, Freq), y=Freq))+
geom_bar(aes(y=Freq,fill=-Freq),stat="identity") +
xlab("")+
theme_gray (base_family = "HiraKakuPro-W3") +
geom_text(aes(x=reorder(Term, Freq), y=Freq, label = Freq), hjust=1.3,colour = " white", size = 3) +
theme(axis.text.x = element_text(size=8), axis.text.y = element_text(size=8)) +
coord_flip()
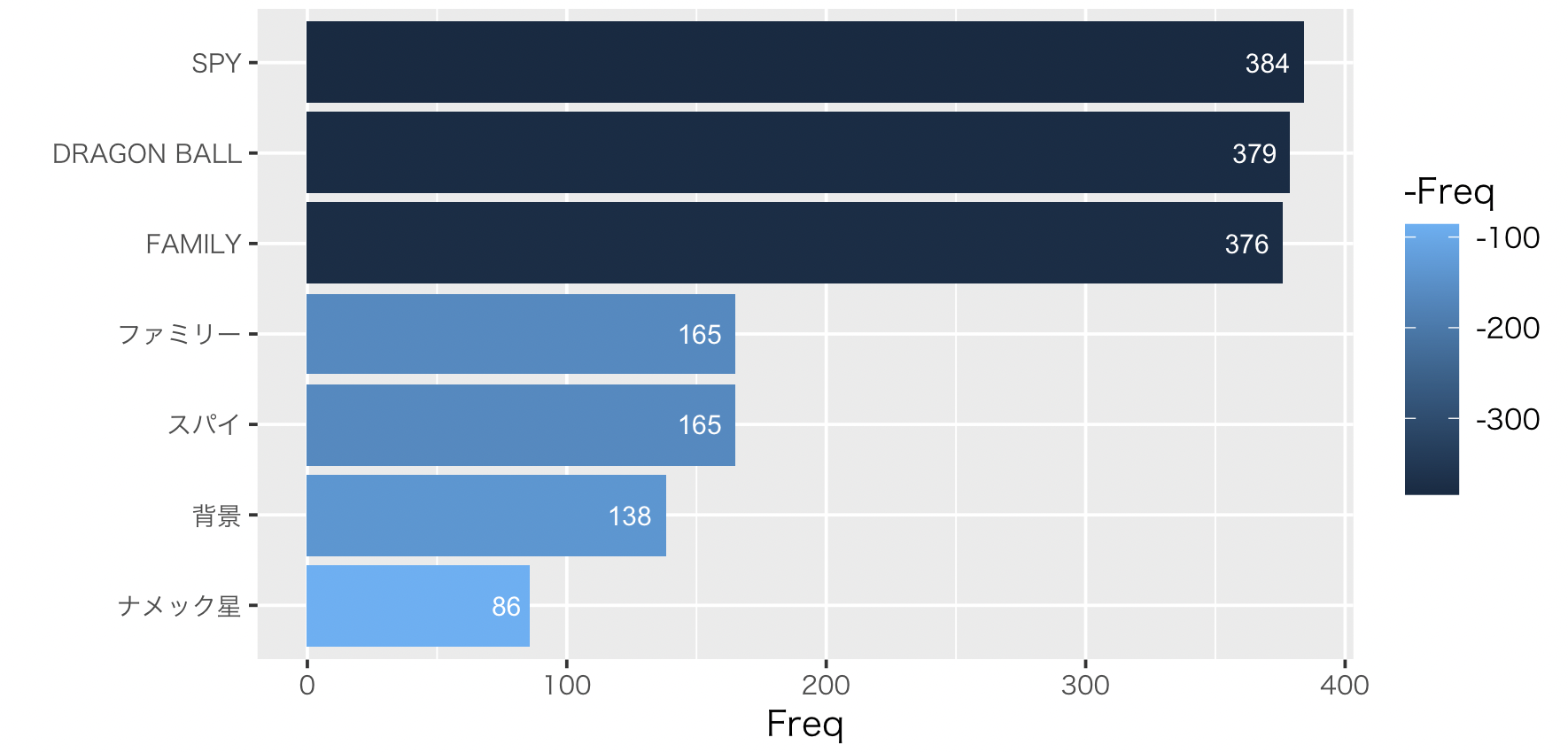
6/11(土)に放送された回で、「あれ?背景がナメック星?」というシーンがあったのです。
了