こんにちは。
scikit-learnを使ってアヤメ分類をしてみましたので軽くメモをまとめます。
今回は環境構築不要の開発環境 Google Colaboratory を使ってます。
今回やること
機械学習ライブラリであるscikit-learnを使って元々サンプルデータが用意されているアヤメデータを使って、がく片や花びら幅や長さを数値化してどこのアヤメなのか機械学習で判別します

必要なライブラリなどインポートしておく
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
データをセット
dataSet = load_iris()
irisData = pd.DataFrame(dataSet.data, columns=["がく片の長さ","がく片の幅","花びらの長さ","花びらの幅"])
irisData['花の種類'], irisData['Target'] = dataSet.target_names[dataSet.target], dataSet.target
irisDataの中身を確認するとこんな感じのデータが出てくると思います。
| がく片の長さ | がく片の幅 | 花びらの長さ | 花びらの幅 | 花の種類 | Target | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa | 0 |
| ... | ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica | 2 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | virginica | 2 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica | 2 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica | 2 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica | 2 |
学習用(訓練用)とテスト用を作成
モデルにデータを学習用させる(訓練用)とテスト用にデータ分割を作ります。
デフォルトはtest_size=0.25で25%がテスト用、残りの75%が訓練用となるが0.3のほうがバランス的に良さそうなので設定する(要出典?)
irisDataTarget = pd.DataFrame(dataSet.target, columns=["Target"])
X_train, X_test, y_train, y_test = train_test_split(irisData.loc[:, ["がく片の長さ", "がく片の幅", "花びらの長さ", "花びらの幅"]], irisDataTarget, test_size=0.3)
データを可視化
import seaborn as sns
import japanize_matplotlib
sns.set(font="IPAexGothic") #ラベル名に日本語が入っていると文字化けするので設定する
sns.pairplot(irisData.loc[:, ["がく片の長さ", "がく片の幅", "花びらの長さ", "花びらの幅", "花の種類"]], hue="花の種類")
可視化した結果
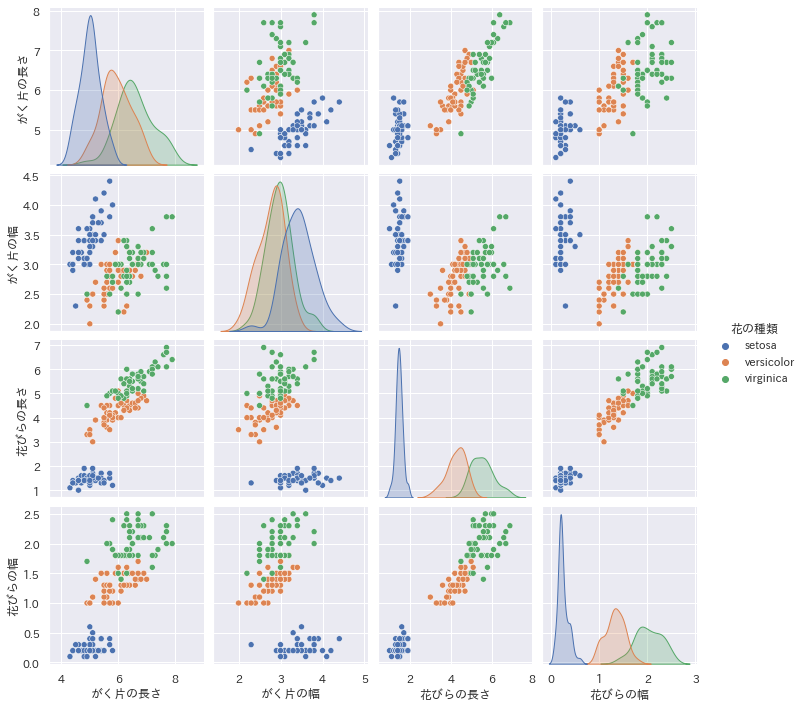
花びらの長さと花びらの幅、特徴量がうまく分別できてそうなので問題なさそうですね!
モデル化
scikit-learnには様々なアルゴリズムをありどれを選べばいいのかチートシートがあるのでこちらの記事を参考して最適なアルゴリズムを決定します。
https://qiita.com/sugulu_Ogawa_ISID/items/e3fc39f2e552f2355209
今回は教師あり学習なのでチートシートに沿ってYES or No を進めていくとLinerSVCというアルゴリズムを使うことにします。
パラメータチューニングは一旦デフォルトのままでモデル化します。
model = LinearSVC()
model.fit(X_train, y_train)
a = model.score(X_train, y_train)
結果
0.9619047619047619
実行すると約96%ぐらい正解していますね。かなりの精度でしょうか。 パラメータチューニングをすればもっと良くなるんじゃないかなと思ったりしています。
構築したモデルにデータを投げてみる
構築したモデルにがく片の長さなどを入れてどこのアヤメなのか予測してみます。
| がく片の長さ | がく片の幅 | 花びらの長さ | 花びらの幅 | 花の種類 | Target | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa | 0 |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica | 2 |
testData = [
[6.7, 3.0, 5.2, 2.3],
[5.1, 3.5, 1.4, 0.2]
]
model.predict(data)
結果
array([2, 0])
うまく行ってそうですね。(小並感)
とこんな感じにサクッと構築してみましたが、 ド素人でも簡単に実装することができました。