
(この記事は先日2019年9月22日に開催された技術書典7にて頒布した『りあクト! Firebaseで始めるサーバーレスReact開発』の「4-6. Firestore だけで全文検索を実現する」の内容を紹介したものです)
やっぱりまだ Firestore で提供されない全文検索機能
昨日(2019年9月26日)、スペインのマドリードで開催された Firebase Summit 2019 ですが、新機能が大量にリリースされて開発者は嬉しい悲鳴を上げているようです。詳しくは公式ブログやセッションの動画を参照していただくとして、個人的には Firebase Extension に可能性を感じてて、分散カウンターや Firestore コレクションの BigQuery 同期が手軽に使えるようになったの嬉しいですね。これからめっちゃ活用していきたいです。
しかしそれでも今回も、Firestore の全文検索機能は提供されませんでした。公式ドキュメントは「Algolia を使え。以上」となってて取り付く島もない。古参の開発者はおとなしくそれに従っているようですが、最近 Firebase を使い始めた私としてはどうにも納得がいきませんでした。
いちばんの理由は値段。月額 29ドルでかつそれに含まれるのは 5万件までのレコードと 25万回までの読み書きだけ。以降は従量制です。会社として使うには安いのでしょうが、個人開発に使うサービスとしては痛い。
さらに、Cloud Functions で Firestore トリガー関数を用意して随時必要なデータを同期させる必要があるのもわずらわしい。
そこで、シンプルでいいので Firestore 単体で全文検索機能を実現できないか模索しました。
Firestore だけの全文検索、やってみたらできてしまった
結果から言うと可能でした。今回の執筆にあたって「Mangarel」というコミック情報アプリを開発したのですが、そこで作った全文検索機能を提供しているので、まずはどんなものか使ってみてください。
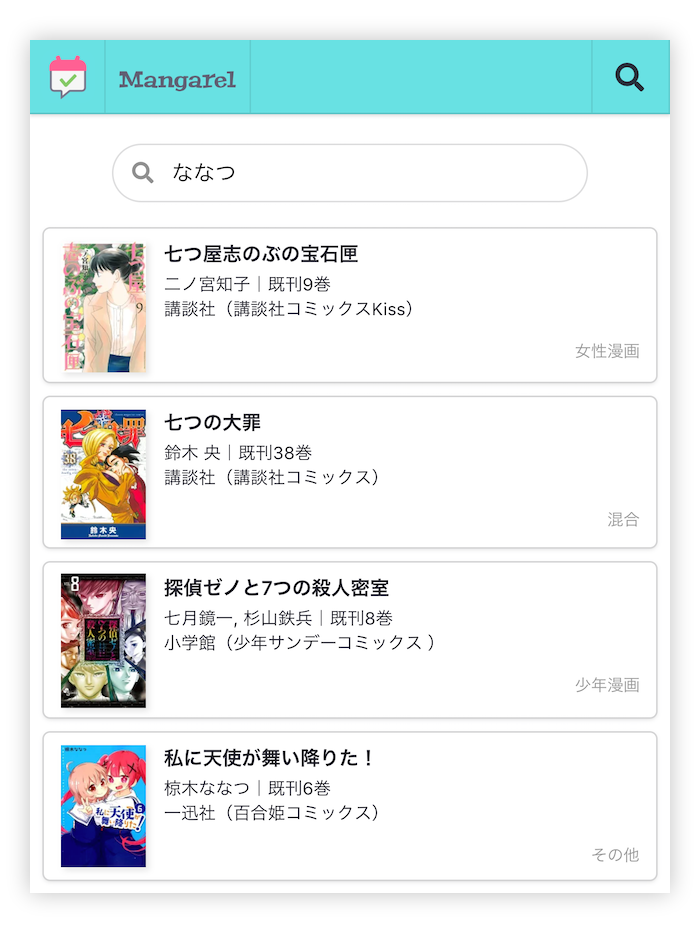
生 Firestore なのでパフォーマンスはめちゃくちゃよくて、このようなインクリメンタルサーチでも遅延もほぼなく実現できてしまいます。なんとこれが無料ですよ、奥さん!
どうやってこれを実現しているかを以降で説明します。
全文検索をどうやって実装しているか
MySQL が全文検索機能を提供してなかったころの昔の話ですが、当時勤務していた某 R 大手ネット通販企業の女性サイトで簡易全文検索を実現したときの方法を流用しました。どうやっていたかというと、オープンソースの形態素解析エンジン「MeCab」をつかって分解した形態素(言語として意味の通る最小単位)を配列フィールドに格納して、検索時にも同じアルゴリズムを使って分解した文字列がその配列に含まれているか判別させていました。
これだとマッチ率の高い順に並べ替えるようなことはできませんが、当時その機能がなかった MySQL 単体で、別途 Elasticsearch のようなサーバを立ててメンテすることなく全文検索を実現できました。
当初、今回も同じことをやろうと考えたのですが問題がありました。
- 巨大な辞書ファイルの置き場所をどうするか
- Firestore がクエリーで
array-containsを使えるのは一度だけ
前者について、某女性サイトで提供していたのは PHP によるサーバーサイドアプリケーションだったので、辞書ファイルはサーバに置いておけば、データ格納時にもクエリー発行時にもその同じ辞書が使えたので問題なかったのですが、今回は SPA なので同じ方法が使えません。それでどうしたか。N-gram を使いました。
N-gram とは「テキストを N 数の隣り合う文字のかたまりに分解するアルゴリズム」です。N の数が 2 なら「bi-gram」、3 なら「tri-gram」とも呼ばれます。たとえば「王様達のヴァイキング」をその二つの方式で分解するとこうなります。
["王様", "様達", "達の", "のヴ", "ヴァ", "ァイ", "イキ", "キン", "ング"] // bi-gram
["王様達", "様達の", "達のヴ", "のヴァ","ヴァイ", "ァイキ","イキン", "キング"] // tri-gram
このやり方だと索引となる配列の容量が形態素解析を使ったときと比べて大きくなるというデメリットもありますが、フロントエンドアプリ内に巨大な辞書ファイルを含める必要がなくなります。また形態素解析だと新たな造語や流行語が変なふうに分解されてしまうことがあり、対応しようとすると辞書のアップデートが必要になりますが、それもいりません。今回の要件にピッタリだったので、この N-gram を使うことにしました。
そして後者の「クエリー内で array-contains が使えるのは1回だけ」問題ですが、これも力技でクリアしました。配列がダメならマップにしようということで、こういうマップを作ってフィールドに格納することにしました。
tokenMap = {
'王様': true,
'様達': true,
'達の': true,
'のヴ': true,
'ヴァ': true,
'ァイ': true,
'イキ': true,
'キン': true,
'ング': true,
};
そしてたとえば「王様達の」という語句で検索が実行されたときにはこのようなクエリーを発行するようにします。
const searchWords = ['王様', '様達', '達の'];
let query = db.collection('comics').limit(30);
searchWords.forEach(word => {
query = query.where(`tokenMap.${word}`, '==', true);
});
const snap = await query.get();
これで実際に『王様達のヴァイキング』がヒットするようになります。
この方法の pros & cons
とりあえず簡易的に全文検索を実現するための方法なので、いくつか以下のような制限があります。
cons1. 検索対象となるテキストサイズの制限
Firestore は 1ドキュメント 1MB という制限があるため、上記のトークンマップを作った上でそのオブジェクトも含めて該当ドキュメントが 1MB に収まるようにしなければいけません。
かつ、ひとつのドキュメントが持てるフィールドは最大 2万なので、他のフィールド数を引いて残った数にトークンの数が制限されます。つまり 1万文字も入れられないということです。
cons2. ソートができない
サーバー側で一切のソートができません。マッチ率などは最初から無理ですが、たとえば検索結果のドキュメントを createdAt などで並べ替えるといったことは対応不可能です。
cons3. 意図しないマッチング
たとえば Mangarel の検索で[「ルーム」と検索する] (https://mangarel.com/search?q= %E3%83%AB%E3%83%BC%E3%83%A0)と、『グランブルーファンタジー外伝』がヒットしてしまいます。これは分解した ['ルー', 'ーム'] が「グランブルー」の 'ルー' と著者ヨミガナの「サイゲーム」の 'ーム' の二つにマッチングするためです。
この手法のデメリットと言うより、N-gram の欠点と言ったほうがいいかもしれません。
逆に、Algolia などと比較して以下のような長所もあります。
pros1. 高パフォーマンス
生 Firestore なのでとにかく速いです。
pros2. ノーメンテでのフィルタリング
ソートはできませんが、他のフィールドと併せてのフィルタリングは可能です。しかもあらかじめ、複合インデックスを作る必要もありません。
Algolia などで同じことをしようとすると、そのフィールドデータを Algolia に送って同期させる必要があります。
まとめ
以上、私が Firestore だけで全文検索を実装した方法を簡単に紹介しました。
なお、『りあクト! Firebaseで始めるサーバーレスReact開発』 ではこの方法がサンプルコード付きでくわしく解説されていますので、興味のある方はそちらをご覧ください。
サンプルコードは Apache ライセンスですので、適当に加工して使っていただいてかまいません。
Firebase、新機能が追加されてどんどん使いでが良くなっているので、日本でも盛り上げていきたいですね!