本日でPythonで何が出来るかについてです。
前回はこちら
[100日後にエンジニアになるキミ - 34日目 - Python - Python演習3]
(https://qiita.com/otupy/items/400f89fd2755bc7e47f0)
その先、仕事とか、研究にどう使えるの?
[ ]
]
(https://youtu.be/c-yVo9l_Qvw)
さて
プログラミングの基礎はいかがだったでしょうか?
文法を一通りやって、演習もやってもらえれば
それなりに理解できると思いますが
まだ、ここまでの段階だと
プログラミングでどんなことができるかとか
どんなことに役立つのかとか・・
イメージが湧かない方の方が多いのではないかと思います。
なので、実際に仕事で使っているコードも見ながら
プログラミングがどういうものなのかを
改めて体験していただき、その後どうすれば良いか
というところを深く掘り下げて行きたいと思います。
ファイルの読み込み
with open(ファイルパス) as 変数名:
処理
# 同じ階層に配置してあるファイルの中身を表示する。
with open('sample.py') as _r:
print(_r.read())
def hello(aa):
print(aa)
読み込みした際の変数名.read()で
ファイルの中身を全て読み込みします。
上記の例だとファイルのコードを全て読み込んでプリントしています。
CSVファイルの読み込み
ファイルの読み込み部分は一緒です。
CSVは,で区切りフォーマットのファイルで
,で区切って読み込みを行う事ができます。
文字列.split(',')でカンマで区切りリスト型に変換を行う
# 結果を格納する変数を用意
res = []
# ファイルの読み込み
with open('sample.csv') as _r:
for row in _r:
# 改行を取り除き、カンマで区切って配列にする
rows = row.replace('\n','').split(',')
# 結果用の変数に追加
res.append(rows)
print(res)
[['aaa', 'bbb', 'ccc'], ['ddd', 'eee', 'fff'], ['hhh', 'iii', 'jjj'], ['kkk', 'lll', 'mmm']]
for row in res:
# タブ区切りで表示
print('\t'.join(row))
aaa bbb ccc
ddd eee fff
hhh iii jjj
kkk lll mmm
スクレイピング
スクレイピングはwebサイトへアクセスして情報取得する技術の事です。
Python言語には、スクレイピング用のライブラリが備わっているので
比較的簡単にWEBサイトから情報取得する事ができます。
requests.get(サイトURL)
WEBサイトへアクセスして情報を取得する。
import requests
# webサイトへアクセスしてデータを取得
html = requests.get('http://yahoo.co.jp')
# 取得したデータの最初の800文字を表示
print(html.content.decode('utf-8')[0:800])
機会学習系のライブラリの利用
データの可視化
データフレーム.plot()
でデータの可視化を行う(デフォルトは折れ線グラフ)
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# データフレームの作成
df = pd.DataFrame([[3,4],[4,5],[6,9],[2,8]],columns=['a','b'])
# データフレームを描画
df.plot()
plt.scatter(データフレーム,データフレーム)
データフレームの2列を用いて散布図を表示する。
df = pd.DataFrame([[3,4],[4,5],[6,9],[2,8]],columns=['1','2'])
# 散布図を描画
plt.scatter(df['1'],df['2'])
scikit learn
scikit learnは機械学習用のライブラリで各種モデル作成のためのプログラム群と
学習用のサンプルデータが揃っている。
datasets.load_iris()
学習用データの読み込み(iris:あやめのサンプルデータ)
import pandas as pd
# 必要なライブラリのインポート
from sklearn import datasets, model_selection, svm, metrics
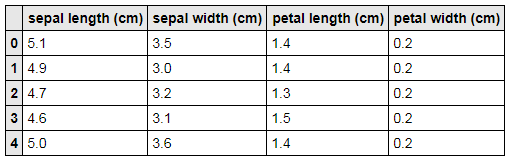
# 有名なアヤメのデータの読み込み
iris = datasets.load_iris()
# アヤメのデータをデータフレームに変換する。
iris_data = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 5行だけ表示
iris_data.head()
# ラベルデータの読み込み
iris_label = pd.Series(data=iris.target)
# 5行だけ表示
iris_label.head()
0 0
1 0
2 0
3 0
4 0
dtype: int64
train_test_split(学習データ, 正解ラベル)
学習データを訓練用とテスト用に分ける。
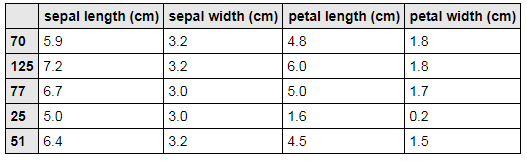
# アヤメのデータを訓練データ、テストデータ、訓練ラベル、テストラベルに分ける。
train_data, test_data, train_label, test_label = model_selection.train_test_split(iris_data, iris_label)
# 訓練データ
train_data.head()
# 訓練ラベル
train_label.head()
70 1
125 2
77 1
25 0
51 1
dtype: int64
# 訓練データとテストデータの個数
print(len(train_data), '\t', len(test_data))
112 38
変数名 = 学習モデルの変数名.クラス()
学習モデルの変数名.fit(訓練データ,訓練ラベル)
訓練データで学習をおこなう。
# SVM学習器の定義
clf = svm.SVC()
# 訓練データで学習
clf.fit(train_data, train_label)
# テストデータで予測
pre = clf.predict(test_data)
print(type(pre))
print(pre)
[0 0 1 1 0 2 1 0 2 1 2 0 2 2 0 1 0 0 2 1 0
0 0 2 0 2 2 2 1 0 2 0 1 2 2 1 0 1]
accuracy_score(テストラベル, 予測値)
予測値の正答率を算出する
# 正答率
ac_score = metrics.accuracy_score(test_label, pre)
print(ac_score)
0.947368421053
サンプルデータだけでも10種類ほどは揃っているので
様々な機械学習モデルを試す事ができます。
その他
他にどんな事が出来るのか、コードを併記しませんが事例を挙げておきます。
定型作業の自動化
メールの受発信、一覧作成
SNSの投稿、書き込みの収集
エクセル、ワード文書などの作成(レポート作成)
PDFのテキスト抽出
GUI操作
データベース操作
データの加工、登録、追加、削除
大量データ加工
画像処理
画像収集
opencvなどを用いた画像加工
顔の抽出
物体検知
統計分析
基礎統計量の算出
分布の計算、可視化
回帰分析
区間推定
仮説検定
Webアプリケーション開発
FlaskやDjangoなどのフレームワークを用いたWEBサイト構築
ゲーム開発
PyGameやKivyなどのフレームワークを用いたゲーム開発
自然言語処理
テキストマイニング
形態素解析
係り受け
n-gram
woed2vec
AI開発
機械学習
DeepLearning
強化学習
GAN
まとめ
これでプログラミングを一通り学んだ訳です。
文法についてはやってきているので、だいたい書けるようになっているはずです。
ここからは自分自身の作りたいプログラムを作ってみましょう。
よく使うコードについてはひとまとめにしておきました。
こちらにリンクを貼っておきますので、是非参考にしてみてください。
https://note.com/otupy/n/n1bedb9f36e54
君がエンジニアになるまであと65日
作者の情報
乙pyのHP:
http://www.otupy.net/
Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMw
Twitter:
https://twitter.com/otupython