本記事は、AWS Containers Advent Calendar 2021 の 18 日目のエントリーです。
Karpenter とは
2021/11/29 (米国時間) に一般提供を開始した、Kubernetes クラスターのオートスケーラーです。
オープンソースプロジェクトとして GitHub で公開されています。
- GitHub: aws/karpenter: Kubernetes Node Autoscaling: built for flexibility, performance, and scalability. https://karpenter.sh
- Docs: Karpenter
Karpenter はクラウドプロバイダーに依存しない設計となっていますが、2021/12/20 時点 (v0.5.3) では AWS のみがサポートされています。
Kubernetes Auto Scaling 101
Kubernetes のオートスケーリングは、大きく分けてコンテナのスケーリングとノードのスケーリングという 2 つのレイヤーがあります。
コンテナレイヤーのオートスケーリングは Horizontal Pod Autoscaler (HPA) や Vertical Pod Autoscaler (HPA) などが、ノードレイヤーのオートスケーリングは Cluster Autoscaler を利用される場合が多いかと思います。
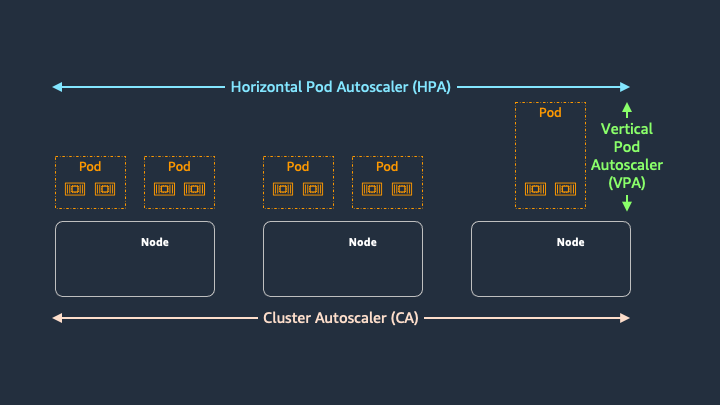
Karpenter はノードレイヤーのオートスケーリングを行うツールであるため、上記の図における Cluster Autoscaler の部分が Karpenter に置き換わる形となります。
Cluster Autoscaler によるノードのプロビジョニング
Karpenter の説明に入る前に、まずは AWS において Cluster Autoscaler がどのようにノードのプロビジョニングを行なっているのかを見ていきます。
※ EKS on Fargate を利用する場合、ノードレイヤーのオートスケーリングを管理する必要がなくなるため、Cluster Autoscaler などのノードレイヤーのオートスケーラーが不要になります。以降、本記事は EKS on EC2 を想定して説明しています。
Cluster Autoscaler は、unschedulable な Pod を検知した場合にノードの追加を試みます。Cluster Autoscaler が内部的に持っている node group というリソースに対してノードの追加が行われますが、node group の実態はクラウドプロバイダーにより異なります。AWS の場合は Amazon EC2 Auto Scaling グループが node group と対応しており、Auto Scaling グループの希望するキャパシティを増加することでノードを追加します。

この Auto Scaling グループは、セルフマネージド型ノードとしてユーザー自身で管理する場合や、マネージド型ノードグループにより Amazon EKS が管理する場合があります。
Karpenter を利用することで何が嬉しいのか
Karpenter は、Cluster Autoscaler に対して次のような改善を行なっています。
- クラウドの柔軟性を活用
- グループ単位ではないノードのプロビジョニング
- スケジューリングの実施
クラウドの柔軟性を活用
この項目については、以下の「グループ単位ではないノードのプロビジョニング」の節で合わせて説明します。
グループ単位ではないノードのプロビジョニング
前述の通り、Cluster Autoscaler は node group に対してノードの追加を行なっています。
ここで、Cluster Autoscaler が管理する node group が複数存在する場合の挙動について考えて見ます。Cluster Autoscaler では、unschedulable な Pod が配置可能な node group をシミュレーションにより判断しています。このシミュレーション結果と実際に node group に追加されるノードを合致させるために、Cluster Autoscaler では「node group に所属するノードが、同一のスケジューリングプロパティ (Resources, Label, Taint) を持つこと」をベストプラクティスとしています。
AWS の場合、すなわち Auto Scaling グループにおいては、インスタンスポリシーで指定された最初のインスタンスタイプがシミュレーションに利用されます。そのため、より多くのリソースを持つインスタンスタイプがポリシー含まれている場合、追加された EC2 インスタンスのリソースが余剰となるような状況が発生します。
参考: Cluster Autoscaler - Amazon EKS
これは言い換えると、ワークロードで必要となるスケジューリングプロパティを持つ Auto Scaling グループを事前に作成しておく必要がある、またプロビジョニング可能なノードは Auto Scaling グループ単位のスケジューリングプロパティに制限される、という状況でした。
Karpenter は node group という抽象的な単位ではなく、ノードすなわちインスタンスを直接扱うことでこれらの状況を改善しています。
AWS では、EC2 Fleet という機能で EC2 インスタンスが管理されています。
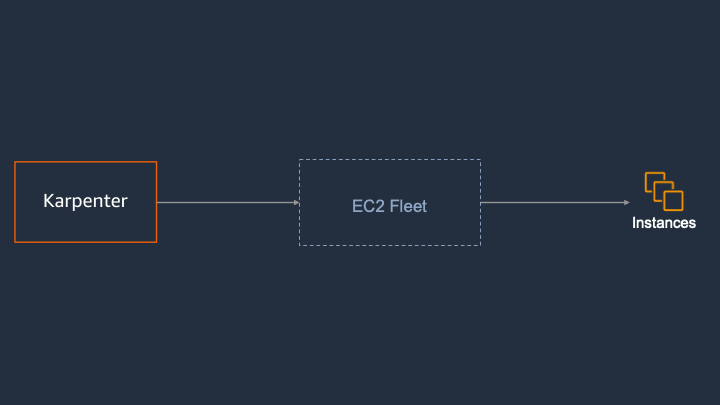
インスタンスを直接扱うため、Karpenter では事前に Auto Scaling グループを作成しておく必要がありません。そのため、ワークロードで必要となる複数の Auto Scaling グループを事前に作成するといった運用上のオーバーヘッドを削減することができます。
また、クラウドプロバイダーによって提供される幅広いインスタンスのオプションから適切なインスタンスを追加することが可能なため、インスタンスタイプや購入オプション (e.g. オンデマンド、スポット) などクラウドの柔軟性を十分に活用することが可能です。
スケジューリングの実施
Cluster Autoscaler では、追加したノードへの Pod のスケジューリングは kube-scheduler に依存しています。これに対して Karpenter は、Karpenter が追加したノードへの Pod のスケジューリングを Karpenter 自身が行なっています。そのため、ノードの Ready および kube-scheduler によるスケジューリングを待つ Cluster Autoscaler よりもパフォーマンスが改善されます。
Karpenter によるスケーリングアクション
ノードの追加
ノードのプロビジョニングについては Cluster Autoscaler と同様で、unschedulable な Pod を検知することでノードの追加が行われます。
また、前述のように AWS では EC2 Fleet という機能で EC2 インスタンスが管理されています。
ここで、Karpenter は EC2 Fleet による EC2 インスタンスの起動と合わせて次の処理を行なっています。
- Node オブジェクトの登録
- 登録した Node への Pod の bind
Karpenter の特徴として、Node オブジェクトの登録は kubelet による操作を待たずに Karpenter 自身が行なっています。
また、登録した Node への Pod の bind についても、kube-scheduler を待たずに Karpenter 自身が行なっています。
ノードの終了
Karpenter には、ノードを終了するための仕組みが現時点で 2 つ備わっています。
1 つは、空のノードを終了するという仕組みです。
空のノードとは、DaemonSet により管理される Pod および Static Pod 以外の Pod が実行されていないノードを指しており、Karpenter は空のノードを検知すると annotation として TTL を付与し、TTL の経過後に該当するノードを終了します。
もう 1 つは、期限の切れたノードを終了するという仕組みです。
Karpenter は、ノードの生存期間を評価する control loop を持っています。期限の切れたノードを検知すると、該当するノードの cordon & drain を実施後にノードを終了します。
これらは、後述の Provisioner という Custom Resource で設定可能で、この機能自体を無効にすることもできます。
Provisioner
Karpenter では、各種設定を Provisioner という Custom Resource で定義します。
以下、例を用いて説明します。
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
# If nil, the feature is disabled, nodes will never expire
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
# If nil, the feature is disabled, nodes will never scale down due to low utilization
ttlSecondsAfterEmpty: 30
# Provisioned nodes will have these taints
# Taints may prevent pods from scheduling if they are not tolerated
taints:
- key: example.com/special-taint
effect: NoSchedule
# Labels are arbitrary key-values that are applied to all nodes
labels:
billing-team: my-team
# Requirements that constrain the parameters of provisioned nodes.
# These requirements are combined with pod.spec.affinity.nodeAffinity rules.
# Operators { In, NotIn } are supported to enable including or excluding values
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.large", "m5.2xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-west-2a", "us-west-2b"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type" # If not included, the webhook for the AWS cloud provider will default to on-demand
operator: In
values: ["spot", "on-demand"]
# These fields vary per cloud provider, see your cloud provider specific documentation
provider: {}
-
spec.ttlSecondsUntilExpired- 前述の、期限の切れたノードを終了するという仕組みで利用する期限を設定します
- このプロパティを未設定にすることで、この仕組み自体を無効にできます
-
spec.ttlSecondsAfterEmpty- 前述の、空のノードを終了するという仕組みで利用する期限を設定します
- このプロパティを未設定にすることで、この仕組み自体を無効にできます
-
spec.requirements- Karpenter がプロビジョニングするノードの制約です
- Karpenter は、この制約にマッチする Pod が unschedulable となった場合のみノードのプロビジョニングを開始します
- 詳細は、後述の Karpenter における制約レイヤーをご参照ください
-
spec.taints- ノードに付与する Taint を設定します
-
spec.labels- ノードに付与する Label を設定します
-
spec.provider- クラウドプロバイダーごとに利用するプロパティです
- AWS の場合、ノードに設定するインスタンスプロファイルやノードを起動するサブネットのセレクターなどを設定します
参考: Provisioner API | Karpenter
Karpenter における制約レイヤー
Karpenter によるノードのプロビジョニングは、次の 3 つのレイヤーで構成されています。
- クラウドプロバイダーの制約
- Provisioner の制約
- Pod の要件

クラウドプロバイダーの制約は、Karpenter を実行しているクラウドプロバイダーが提供するインスタンスタイプやゾーン、購入オプションなどを表しています。
Provisioner の制約は、Provisioner Custom Resource の設定内容です。クラウドプロバイダーが提供していないインスタンスタイプやゾーンは当然ながら利用することができないため、Provisioner Custom Resource の制約はクラウドプロバイダーの制約のサブセットになります。
Pod の要件は、実際に実行する Pod が持つ要求事項です。CPU アーキテクチャやゾーンなどを Node Affinity や Tolerations で宣言します。Karpenter では、Pod の要件が Provisioner Custom Resource 制約のサブセットである場合にノードのプロビジョニングを行います。
どういうことか、例を用いて説明します。
次の図のように、kubernetes.io/arch: amd64 という制約を持つ Provisioner Custom Resource を作成した状況を想定します。
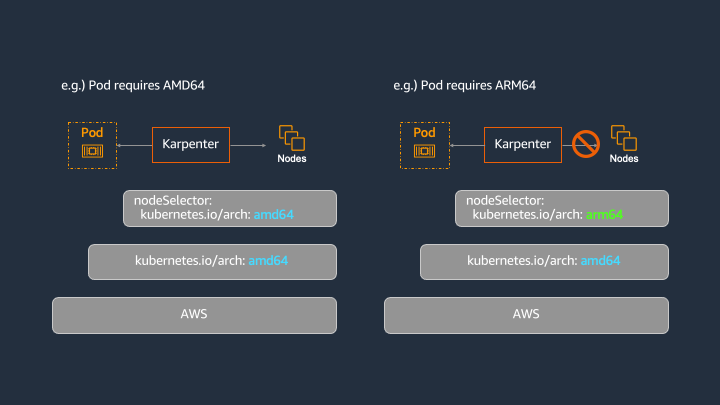
この場合、kubernetes.io/arch: amd64 を要求する Pod が unschedulable となった際に Karpenter によるノードのプロビジョニングが行われます。
一方で、kubernetes.io/arch: arm64 を要求する Pod が unschedulable となった場合は、Karpenter によるノードのプロビジョニングが行われません。これは、Pod の要件が Provisioner Custom Resource の制約のサブセットではないためです。
この制約レイヤーにより、クラウドプロバイダーの柔軟性を活用しつつ、必要に応じてプロビジョニングの範囲をコントロールすることができます。
おわりに
本記事では、Kubernetes クラスターのオートスケーラーである Karpenter についてご紹介しました。
Karpenter はオープンソースプロジェクトとして GitHub で公開しておりますので、ぜひ皆さんのアイデアやユースケースをお知らせください ![]()