ブログ本編もよろしくお願いします。
ロジスティック回帰とは
-
一般化線形モデルの一つであり、目的変数が2値の時(二値判別問題)や確率を求めたい時によく使用される。
(例|病気の発症率や、迷惑メールか否かの判定など) - ある事象がおこる確率を予測し、クラス分類の問題の場合には、その確率をもとにクラスや二値の判別をおこなう。
- 特徴量空間が線形分離可能な場合にのみ高い性能を発揮する
(例|説明変数が二次元平面上にある場合には、二つのクラスに対応する説明変数の群を一本の直線で分けることができる状況) -
最尤推定法(Maximum Liklihood Estimation) を使い係数の値を求める。
(これに対して、重回帰分析などの一般線形モデルでは、最小二乗法が使われている)
ロジスティック回帰の種類
目的変数のタイプによって以下の様に分類される。
- 二項ロジスティック分析:目的変数が2値変数
- 多項ロジスティック分析:目的変数が3つ以上のカテゴリーを有する
- 順序ロジスティック回帰:目的変数が順序変数(順序尺度を持つ変数=クラス間に順序がある)
- 名義ロジスティック回帰:目的変数が名義変数(名義尺度を持つ変数=クラス間に順序がない)
補足(一般化線形モデルと一般線形モデル)
一般線形モデル(Ordinary Linear Model):目的変数が量的データである一般的な回帰分析。説明変数と目的の間に線形関係があることを仮定している。
一般化線形モデル(GLM:Generalized Linear Model):被説明変数が正規分布の確率分布に従う場合(例えば質的データ)であっても分析ができるよう一般線形モデルを拡張したもの。
| 目的変数 | 目的変数と説明変数の関係 | |
|---|---|---|
| 一般線形モデル | 正規分布に従う | 線形な関係を推計する |
| 一般化線形モデル | 正規分布以外の分布に 従う場合にも使われる |
目的変数を適切な関係に変えたものf(x) と説明変数の関係を推計する |
簡単な説明
ある説明変数のセットが与えられた時に、目的変数(確率)を予測する場合を考える。
(確率なので)予測値は0〜1の値をとるべきなので、重回帰分析などの手法をそのまま適用することは不適切であり、何らかの関数を用いて予測値が0〜1の値に収める必要がある。
ロジスティック回帰では、これにロジスティック関数が用いられる。
ロジスティック関数は以下の式で表され、任意の値をを0〜1の変数に変換することができる。
$$ \sigma(t) = \frac{1}{1 + \exp^{-t}}$$
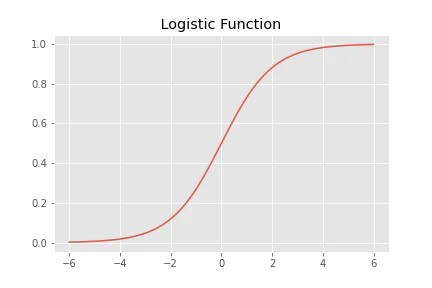
予測したい事象(正事象という)が起こる確率を$ p $とし、オッズ(正事象の起こりやすさ)を $p/(1-p)$ と表す。
ロジスティック回帰では、このオッズの対数を説明変数 $x_i$ の線形和で表現する。
$$ \log (\frac{p}{1-p}) = w_0 + w_1 x_1 + w_2 x_2 + \cdots + w_n x_n = \sum_{i=0}^{n}w_ix_i $$
ただし、求めたいのは正事象の確率なので、左辺が $p$ になるように変形し下の式が得られる。
$$ p = \frac{1}{1 + \exp(-\sum_{i=0}^{n}w_ix_i)} = \frac{1}{1 + \exp[-(w_0 + w_1 x_1 + w_2 x_2 + \cdots + w_n x_n)]} $$
上式における、係数($w_i$)の重みを最尤推定法によって最適化することで、ある説明変数の値が与えられた時に正事象の確率を求めることができるようになる。
二値判別問題の場合には、その確率に応じて正事象のクラスに分類するか否かを決定する。
python実装
乳癌診断結果のデータセット(load_breast_cancer)を用いる。
569人に対する、診断結果を含む30個の説明変数と、それぞれの乳がん診断結果(悪性腫瘍 or 良性腫瘍)の情報が記載されている(変数について)。
ロジスティック回帰によって、乳がん診断結果(悪性腫瘍 or 良性腫瘍)の予測を試みる。
モジュールのインポート〜データ読み込みと可視化まで
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
# scikit-learnより癌のデータを抽出する
data = load_breast_cancer()
df_X = pd.DataFrame(data=data.data,columns=data.feature_names)
df_y = pd.DataFrame(data=data.target,columns=['cancer'])
df = pd.concat([df_X,df_y],axis=1)
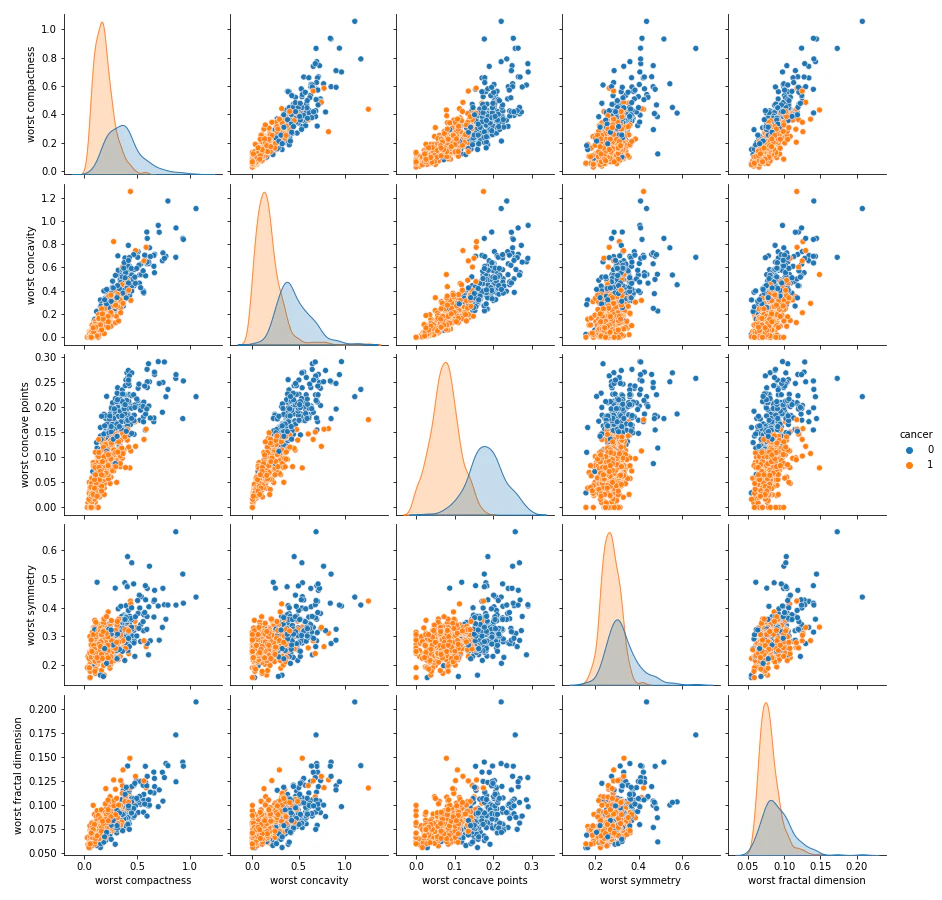
# いくつかの変数で変数同士の関係性を見てみる。
sns.pairplot(df.iloc[:,25:], hue='cancer')
plt.show()
ロジスティック回帰モデルの作成
解析条件
- 説明変数:30個の変数全て使用
- 目的変数:cancer(0:悪性, 1:良性)
- 50%のデータを学習データに、のこり50%をテストデータとする
- ハイパーパラメータ(penalty, C)の最適化は実施しない
参考(設定できるハイパーパラメータ)
| パラメータ | 説明 | デフォルトの値 |
|---|---|---|
| penalty | 正則化の方法 'l1':L1正則化 'l2':L2正則化 |
l2 |
| C | 正則化の強さ(正の値で指定) 小さいほど正則化の強さが増す |
1.0 |
# 説明変数Xと予測したい変数Yを準備する(yは0,1のカテゴリ変数に変換)
X = df.drop('cancer',axis=1)
y = df.loc[:,'cancer']
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size = 0.5, random_state = 0)
# 説明変数は標準化しておく(あとで回帰係数を比較するため)
scaler_X = StandardScaler()
X_train = scaler_X.fit_transform(X_train)
X_test = scaler_X.transform(X_test)
# モデルの構築と学習
lr = LogisticRegression()
lr.fit(X_train, y_train)
# 訓練データ,テストデータに対する予測
y_pred_train = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
# 最初の10サンプルだけ表示してみる
print(y_pred_train[:10])
print(y_pred_test[:10])
"""output
[1 0 1 0 1 1 0 1 0 0]
[0 1 1 1 1 1 1 1 1 1]
"""
予測性能の評価
# 訓練データ
print('accuracy:', accuracy_score(y_true=y_train, y_pred=y_pred_train))
print('precision:', precision_score(y_true=y_train, y_pred=y_pred_train))
print('recall:', recall_score(y_true=y_train, y_pred=y_pred_train))
print('f1 score:', f1_score(y_true=y_train, y_pred=y_pred_train))
print('confusion matrix = \n', confusion_matrix(y_true=y_train, y_pred=y_pred_train))
"""output
accuracy = 0.9894366197183099
precision = 0.9829545454545454
recall = 1.0
f1 score = 0.9914040114613181
confusion matrix =
[[108 3]
[ 0 173]]
"""
# テストデータ
print('accuracy:', accuracy_score(y_true=y_test, y_pred=y_pred_test))
print('precision:', precision_score(y_true=y_test, y_pred=y_pred_test))
print('recall:', recall_score(y_true=y_test, y_pred=y_pred_test))
print('f1 score:', f1_score(y_true=y_test, y_pred=y_pred_test))
print('confusion matrix = \n', confusion_matrix(y_true=y_test, y_pred=y_pred_test))
"""output
accuracy = 0.9754385964912281
precision = 0.9783783783783784
recall = 0.9836956521739131
f1 score = 0.981029810298103
confusion matrix =
[[ 97 4]
[ 3 181]]
"""
# ROC曲線の描画、AUCの計算(ROC曲線の下側の面積)の計算
y_score = lr.predict_proba(X_test)[:, 1] # 検証データがクラス1に属する確率
fpr, tpr, thresholds = roc_curve(y_true=y_test, y_score=y_score)
plt.plot(fpr, tpr, label='roc curve (area = %0.3f)' % auc(fpr, tpr))
plt.plot([0, 1], [0, 1], linestyle='--', label='random')
plt.plot([0, 0, 1], [0, 1, 1], linestyle='--', label='ideal')
plt.legend()
plt.title('ROC curve of test sample',fontsize=15)
plt.xlabel('false positive rate',fontsize=15)
plt.ylabel('true positive rate',fontsize=15)
plt.show()
各精度評価指標の値
| accuracy | precision | recall | f1 score | |
|---|---|---|---|---|
| 訓練データ | 0.989 | 0.983 | 1.0 | 0.991 |
| テストデータ | 0.975 | 0.78 | 0.984 | 0.981 |
**テストデータにおける混同行列**
| 悪性(予測) | 良性(予測) | |
|---|---|---|
| 悪性(実際の値) | 97 | 4 |
| 良性(実際の値) | 2 | 181 |
**テストデータにおけるROC曲線** 
各精度評価指標やAUC(ROC曲線の下側の面積)が高い(1に近いため)良い予測モデルが構築できていると判断できる。
回帰係数の可視化
回帰係数の高い(上位10個)の変数を調べてみる
# 切片(intercept)の表示
print("intercept(切片):", round(lr.intercept_[0],3))
"""output
intercept(切片): -0.220
"""
# 回帰係数を格納したpandasDataFrameの表示
df_coef = pd.DataFrame({'coefficient':lr.coef_.flatten()}, index=X.columns)
df_coef['coef_abs'] = abs(df_coef['coefficient'])
df_coef.sort_values(by='coef_abs', ascending=True,inplace=True)
df_coef = df_coef.iloc[-10:,:]
# グラフの作成
x_pos = np.arange(len(df_coef))
fig = plt.figure(figsize=(6,6))
ax1 = fig.add_subplot(1, 1, 1)
ax1.barh(x_pos, df_coef['coefficient'], color='b')
ax1.set_title('coefficient of variables',fontsize=18)
ax1.set_yticks(x_pos)
ax1.set_yticks(np.arange(-1,len(df_coef.index))+0.5, minor=True)
ax1.set_yticklabels(df_coef.index, fontsize=14)
ax1.set_xticks(np.arange(-10,11,2)/10)
ax1.set_xticklabels(np.arange(-10,11,2)/10,fontsize=12)
ax1.grid(which='minor',axis='y',color='black',linestyle='-', linewidth=1)
ax1.grid(which='major',axis='x',linestyle='--', linewidth=1)
plt.show()
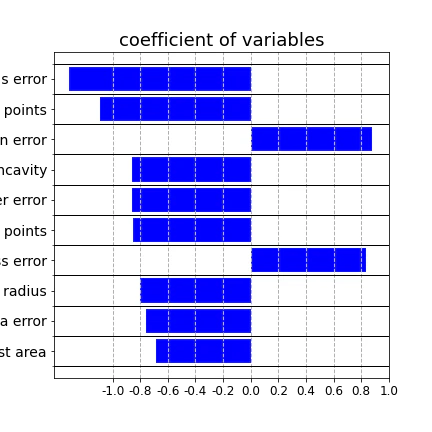
radious error(半径誤差)が最も回帰係数の絶対値が大きく、乳がん腫瘍の悪性・良性判定への寄与が大きいことが分かる。(変数について)
ロジスティック回帰について(詳細説明)
予測したい事象(正事象という)が起こる確率を$ p $、オッズ(正事象の起こりやすさ)を $p/(1-p)$ とし、
このオッズの対数を説明変数 $x_i$ の線形和で表現する。
$$ \log (\frac{p}{1-p}) = w_0 + w_1 x_1 + w_2 x_2 + \cdots + w_n x_n = \sum_{i=0}^{n}w_ix_i \qquad (1)$$
この式を確率 $p$ について変形して
$$ p = \frac{1}{1 + \exp(-\sum_{i=0}^{n}w_ix_i)} = \frac{1}{1 + \exp[-(w_0 + w_1 x_1 + w_2 x_2 + \cdots + w_n x_n)]} \qquad (2)$$
とする。この式における係数($w_i$)を最尤推定法によって学習する。
最尤推定法の手順
$n$ 番目のデータについて、予測値のと当てはまりを考えてみる。
$$ p_n = y_{n}^{t_n} \times (1-y)^{1-t_n} \qquad (3)$$
$y_n$:$n$番目のデータにおける、ロジスティック回帰式から算出される確率(式(2)の$p$)
$t_n$:$n$番目のデータにおける実際の値(0 or 1)
つまり、$p_n$が大きい方が予測式の当てはまりが良いとすると、
- $t_n=1$の時:$p_n=y_n$なので、$y_n$は大きい方がいい
- $t_n=0$の時:$p_n=(1-y_n)$なので、$y_n$は小さい方がいい
式(3)を全データに対して適用(積を計算)すると、
$$ L(w) = \prod_{n=1}^{N} y_{n}^{t_n}(1-y)^{1-t_n} \qquad (4) $$
この$L(w)$を尤度関数といい、これが最大になるとき、(最大になる $w_i$が求まれば)当てはまりが最も良くなると言える。
計算の際には、尤度関数を負の対数尤度(以下の$E(w)$)に変換し、これの最小値を勾配降下法によって求める。
$$ E(w) = - \log L(w) = - \sum_{n=1}^{N}\\{ t_n\log yn + (1-t_n)\log (1-y_n) \\} \qquad (5) $$
勾配降下法
上記の関数をパラメータ$w$について微分すると
$$ \frac{dE(w)}{dw} = \sum_{n=1}^{N}x_n(y_n-t_n) \qquad (6)$$
上記の式(6)が0になるパラメーター${w_i}$の値を算出し、最適なパラメータとする。