(ブログ本編にも投稿してます)
測定には誤差が必ず伴うため、測定によって得られた値には不確かさがあることに留意する。
誤差が測定ごとにランダムであると仮定すれば、データを統計処理することで不確かさを小さくすることができる。
誤差(測定誤差)
誤差:測定値と真値との差([誤差]ー[真値] で求められる。絶対誤差とも呼ぶこともある)
相対誤差:誤差と真値との比。(実際には真の値は分からないので、実際は測定値から真の値を推定し相対誤差の大きさを推定する)
ある量$x$を測定した時、$x$ の測定値$x$(measured)は必ず誤差を含む。
この時、$x$(measured)は、最良推定値($x_{best}$)、誤差(不確かさ|$\delta x$)を用いて、
$$ x(measured) = x_{best} ± \delta x$$
と表される。また、相対誤差(relative uncertainty)はは以下の式で表される。
$$ {relative , uncertainty} = \frac{\delta x}{x_{best}} $$
誤差の種類、正確さと精密さについて
誤差の種類
-
系統誤差(systematic errors):再現性がある誤差。一方向。繰り返し測定を行っても原因は明らかにならないことが多い。誤差の原因がわかれば測定や解析の改良(測定値補正など)で誤差を小さくすることができる。
例)理論(モデル)の誤り、測定器固有の特性など。 -
ランダム誤差(random errors)
:制御できない種類の不規則な誤差のこと。偶発誤差ともいう。繰り返し測定やそれと統計的手法を組み合わせることで誤差の大きさを評価したり、誤差を小さくすることが可能。
例)ランダムな測定ムラ、測定器の精度限界など
正確さと精密さについて
-
accuracy:正確さ。真の値にいかに近いかの尺度
(accuracyが高い=系統誤差が小さい) -
precision:精密さ。一連の実験結果がどの程度一致しているかの尺度。真の値との関係は示していない。
(precisionが高い=ランダム誤差が小さい)
真の値が分かっているか否かで、accuracy, precision, 系統誤差を明らかにできるかどうかが決まる(下表参照)
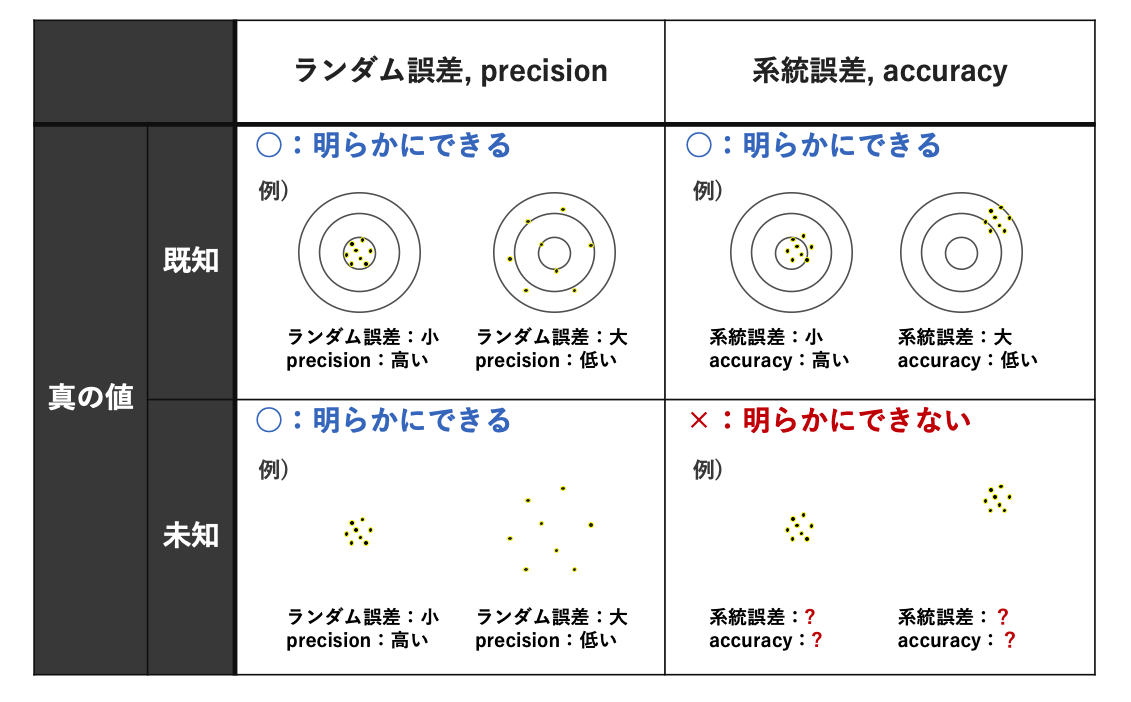
ランダム誤差を小さくするには
ランダム誤差のみ考えた場合、誤差を評価し、測定精度を高めるためには同じ測定を何回も実施し、その値から統計処理によって真値やランダム誤差を見積もることが必要となる。
(母分散が未知の場合の)母平均の信頼区間の求め方
母集団の平均を $\mu$、$x$ 標本平均を $\bar{x}$、不偏分散を $s^2$、抽出したサンプルサイズを $n$、信頼係数を $100(1 - \alpha)$%とすると、下式から母平均 $\mu$ の $100(1-\alpha))$% 信頼区間を求めることができる。
信頼係数:母数を区間推定するときに母数が信頼区間内に含まれる確率のこと。(参考)
$$ \bar{x}-t_{\alpha/2}(n-1)\times\sqrt{\frac{s^2}{n}}\leq\mu\leq\bar{x} +t_{\alpha/2}(nー1)\times\sqrt{\frac{s^2}{n}} $$
解析例)
ある天秤で、ある物質のその重さを10回測定したところ、下のデータが得られた。母分散(≒電子天秤の誤差,分散)は分かっておらず、天秤の誤差は正規分布に従うものとした場合の、このデータの母平均の95%信頼区間を求める。
(上記の式を使い、母平均の信頼区間を求めてみる)

-
標本平均 $ \bar{x} $ と不偏分散 $s^2$ を求める。
$$ \bar{x} = (100.5 + 99.5 + \cdots + 100.4) / 10 = 100.0 \
s^2 = \frac{1}{10-1} \{ (100.5-100.0)^2 + (99.5-100.0)^2 + \cdots + (100.4-100.0)^2 \} = 0.545 $$ -
t分布の上側 $\alpha/2$% 点を求める。
この場合、$\alpha/2 = (100-95)/2=2.5 $% なので、自由度9のt分布の上側2.5%点を求める。
$$ t_{\alpha/2} = 2.262 $$ -
式より95%信頼区間を求める
$$ 100-2.262 \times \sqrt{\frac{0.545}{10}}\leq\mu\leq100-2.262 \times \sqrt{\frac{0.545}{10}} $$
よって、$$ 99.5 \leq\mu\leq 100.5 $$
pythonで計算してみた
import numpy as np
from scipy import stats
data = np.array([100.5, 99.5, 98.9, 101.5,100.1, 99.8, 99.9, 99.2, 100.3, 100.4])
# 平均と不偏分散を求める
mean = round(data.mean(),2)
var = round(data.var(ddof=1),2)
print('平均:',mean)
print('分散:',var)
# t分布の上側 α/2 % 点を求める
upper_0025 = round(stats.t.ppf(q=0.975, df=len(data)-1),3)
print('上側2.5%点:',upper_0025,3)
# 95%信頼区間を求める
lower = round(mean - upper_0025 * np.sqrt(var/len(data)),3)
upper = round(mean + upper_0025 * np.sqrt(var/len(data)),3)
print('95%信頼区間:',lower,'≦',mean,'≦',upper)