CenterNetとは
CenterNetとは、Objects as Pointsという論文で提案された物体検出手法のことです。
物体の中心を特徴点として検出した後、幅・高さのサイズを予測するため、従来の手法と比して計算が軽いなどのメリットがあるようです。
CenterNetを使ってテニスの選手,ボール,コートの位置を検出してみたと同じことをやりたく、CenterNetを使ってあれこれやっています。
CenterNetですが、ソースコードはGithubで公開されており、学習済みモデルを使って推論するなどは、Readme通りに作業すればできます。ただオリジナルデータの学習については、説明や情報が少なく、作業を進めるのに少し苦労しました。作業メモ共有のためと思い、簡易記事を書きました。参考になれば幸いです。
環境
Ubuntu 18.04
PyTorch 0.4.1
データセットの準備
テニスの試合画像で手前側の選手と奥側の選手をそれぞれ物体検出したく、
・手前側の選手を"PlayerFront"
・奥側の選手を"PlayerBack"
とラベル付けしてアノテーションデータを作成しました。
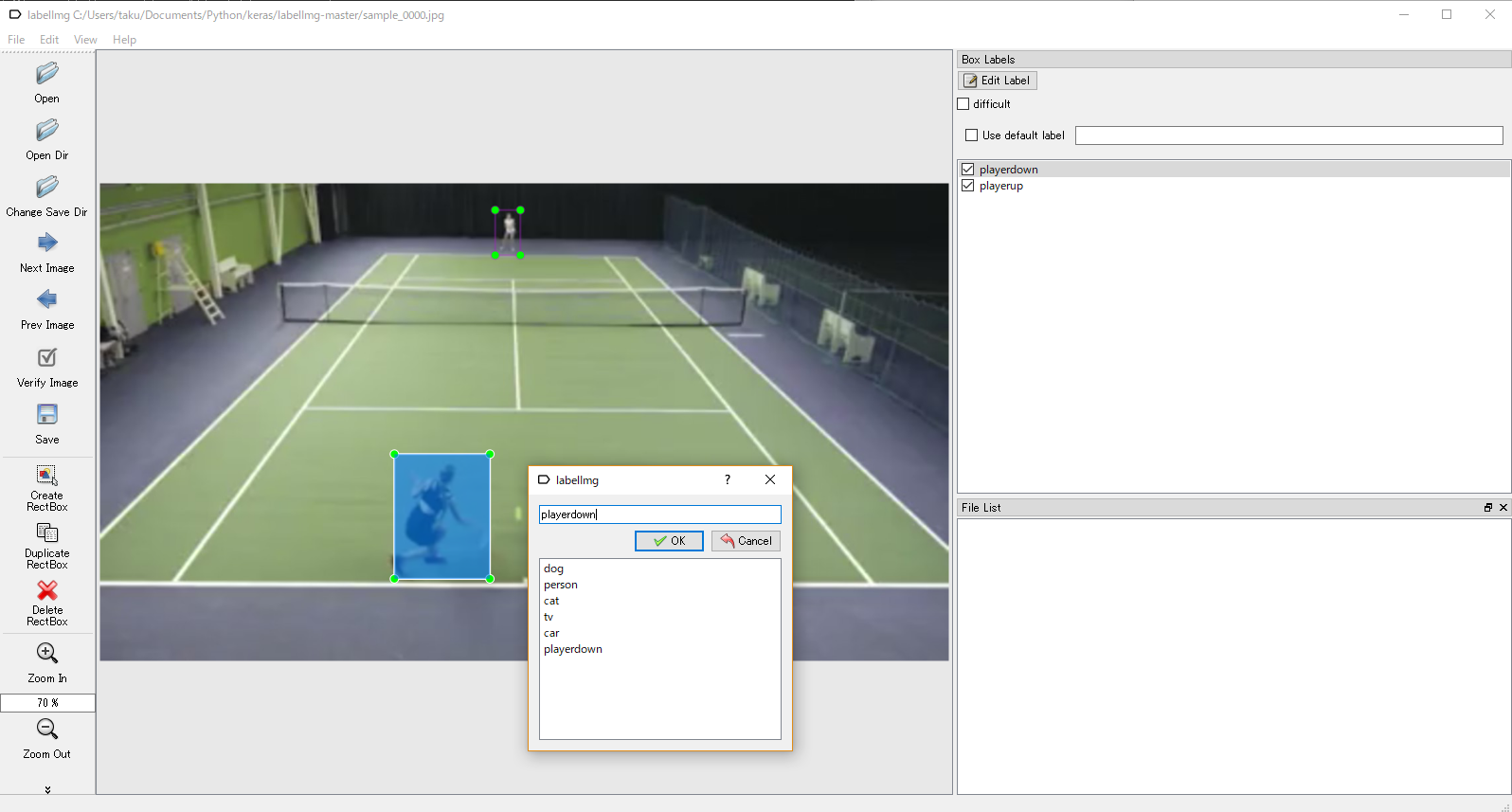
labelImgというツールを使用して作成しましたが、これはPascalVOC形式のxmlファイルとして出力されます。
CenterNetのアノテーションデータはCOCO形式のjsonファイルしか読み込めませんので、xmlファイルをjsonファイルに変換する必要があります。同じ境遇の方は、自分が書いた記事PascalVOC形式のxmlファイルをCOCO形式のjsonファイルに変換するを参考にして変換していただければ。
カテゴリーIDは、
・PlayerFront:1
・PlayerBack:2
として割り付けました。
アノテーションデータは、学習データとテストデータの下記2つのファイルを作成します。ファイル名が異なると学習時にfile not foundとエラーが出力されるのでご注意ください。
・pascal_trainval0712.json :学習データの情報を格納したCOCO形式のデータセット
・pascal_test2007.json :テストデータの情報を格納したCOCO形式のデータセット
アノテーションデータファイル2つは、ディレクトリ構造が↓になるように格納します。
CenterNet/data/voc/annotations/
|--pascal_trainval0712.json
|--pascal_test2007.json
そして、画像データはimagesディレクトリに配置します。
CenterNet/data/voc/images/
|--**.jpg
ソースコードの改変
pascal.pyの30行目のself.class_nameを割り付けたカテゴリーIDに合わせて書き換えます。
# self.class_name = ['__background__', "playerup", "playerdown", "bird", "boat",
# "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog",
# "horse", "motorbike", "person", "pottedplant", "sheep", "sofa",
# "train", "tvmonitor"]
self.class_name=['__background__', "playerFront", "playerBack"]
準備したデータセットで学習する
python main.py ctdet --exp_id pascal_dla_384 --dataset pascal --num_epochs 500 --lr_step 50,100,200,300,400
引数について
ctdet 物体検出(CenterNet)で学習
-- exp_id ネットワークを指定 pascal_dla_384,pascal_dla_512,pascal_resdcn18_384,pascal_resdcn18_512など。MODEL ZOO Pascal VOCに各モデルの推奨GPU数の対応表があるので参考に。
--dataset pascal pascalVOC方式(クラス数20)で学習する
--num_epocks ** エポック数**で学習する
--lr_step 50,100,200,300,400 エポック数50,100,200,300,400の時点でのモデルを保存する指定したエポックのタイミングで学習率(learning rate)を1/10になる
学習データの数が少ない場合、上の方法で学習しても学習不足のモデルが出来る可能性が高いです。
この場合、学習済みモデルを用いて追加で学習させるファインチューニングで学習させると良いです。
--load_model ファイル名を引数にして学習済みモデルを指定します。
学習済みモデルはMODEL_ZOO.mdでダウンロードできます。
ファインチューニングについては、Githubのissues、Transfer learning on very small dataset #307を参考にしました。
python main.py ctdet --exp_id pascal_dla_384 --dataset pascal --num_epochs 500 --lr_step 50,100,200,300,400 --load_model ../models/ctdet_pascal_dla_384.pth
ログファイルと学習モデルは、/exp/ctdet/pascal_dla_384/に格納されます。
推論
学習したモデルを使って推論を実施します。推論実施の前に、CenterNet/src/lib/utils/debugger.pyのコードを改変します。
439行目に、pascal_class_nameの宣言があるので、"PlayerFront"、"PlayerBack"に変更します。
そして、下記コマンドで推論が実施されます。
python demo.py ctdet --demo ../data/voc/images/**.jpg --dataset pascal --load_model ../exp/ctdet/pascal_dla_384/model_last.pth --debug 2
--debug 2 検出結果の画像だけでなく、ヒートマップ画像も確認することができます。