はじめに
Goならわかるシステムプログラミングで、定期的に学んでいます。
今回は、golangでエンディアンを理解していきたいと思います。
※ 今回私が書かせていただく、Qiita記事は、こちら( https://ascii.jp/elem/000/001/260/1260449/ )の補足説明、検証しやすい形に整えたものです。より深く理解したい向けのアドバイスとしては、Qiitaを読んで、イメージを掴んだら、元リンクをじっくり読むことをおすすめします。
エンディアンについて
前提:
- メモリアドレスはbyte単位で割り振られる
-
データのメモリへの格納方法が2週類存在
- データの先頭byteを小さいアドレスに置く方式⇒ビッグエンディアン
- データの先頭byteを大きいアドレスに置く方式⇒リトルエンディアン
10000という数値(16進表示で0x2710)があったときに、ビッグエンディアンでは、Go言語で書くと []byte{0x0, 0x0, 0x27, 0x10} となります。
一方、リトルエンディアンは、Go言語で書くと[]byte{0x10, 0x27, 0x0, 0x0} となります。
文章ですと、イメージしにくいかもしれませんので、数値10000(16進表示で0x2710)を図示してみます。
data変数に32ビットのビッグエンディアンのデータ(10000)を入れる。
data := []byte{0x0, 0x0, 0x27, 0x10}
図示すると、以下の図になります。
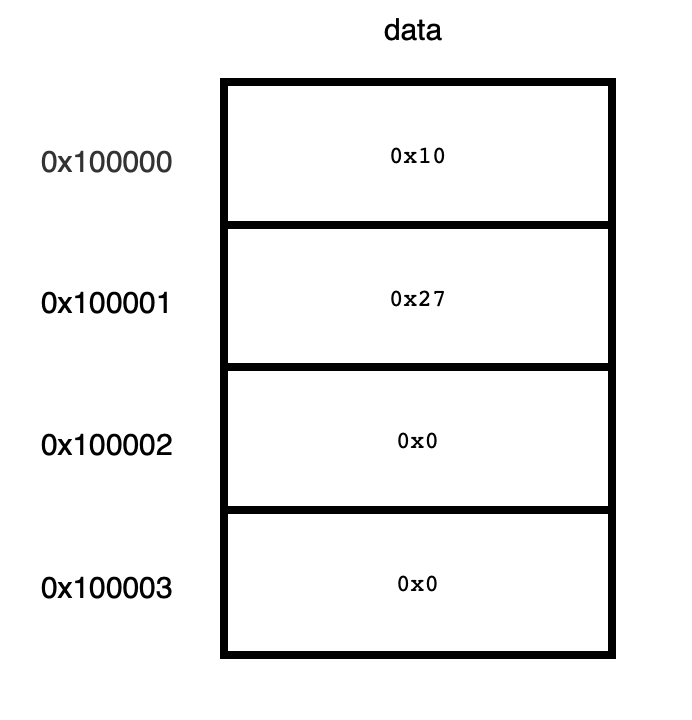
リトルエンディアンの場合は、0x100003に0x10、0x100002には0x27、0x100001と0x100000には0x0が入ります。
Q.リトルエンディアンとビッグエンディアンどちらかに統一されればよいのでは?
お気持ち分かります。この規格は統一されたほうが分かりやすいと思います。しかし、現実はそうはいかず・・。日本で使われている電気の周波数が50Hzと60Hzみたいに異なるものが使われている背景に似ている部分があるのだろうかと思っています。
Q.どのようなときにエンディアンを変換する必要性が出てくるのか?
ネットワークやファイルなど、外部データを扱うときや、外部データとCPUアーキテクチャのエンディアンが違うときなどです。
TCP/IPプロトコルはビックエンディアンだけど、IntelCPUアーキテクチャはリトルエンディアンなので、変換が必要になってくるケースがあります。
実際にプログラムを動かして、リトルエンディアンとビッグエンディアンを体験しよう
package main
import (
"bytes"
"encoding/binary"
"fmt"
)
func main() {
// 32ビットのビッグエンディアンのデータ(10000)
data := []byte{0x0, 0x0, 0x27, 0x10}
var i int32
// エンディアンの変換
binary.Read(bytes.NewReader(data), binary.BigEndian, &i)
fmt.Printf("data: %d\n", i)
}
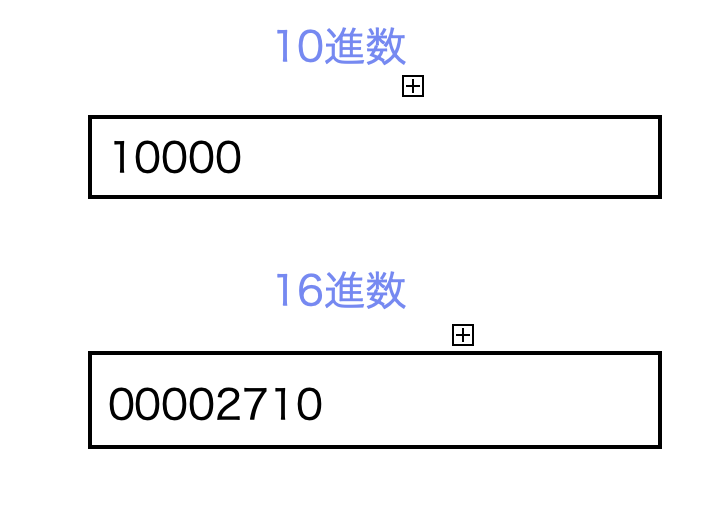
$ go run bigendian.go
data: 10000
次に32ビットのビッグエンディアンのデータ(10000)をリトルエンディアンに変更して実行してみましょう。
package main
import (
"bytes"
"encoding/binary"
"fmt"
)
func main() {
// 32ビットのビッグエンディアンのデータ(10000)
data := []byte{0x0, 0x0, 0x27, 0x10}
var i int32
// エンディアンの変換
binary.Read(bytes.NewReader(data), binary.LittleEndian, &i)
fmt.Printf("data: %d\n", i)
}
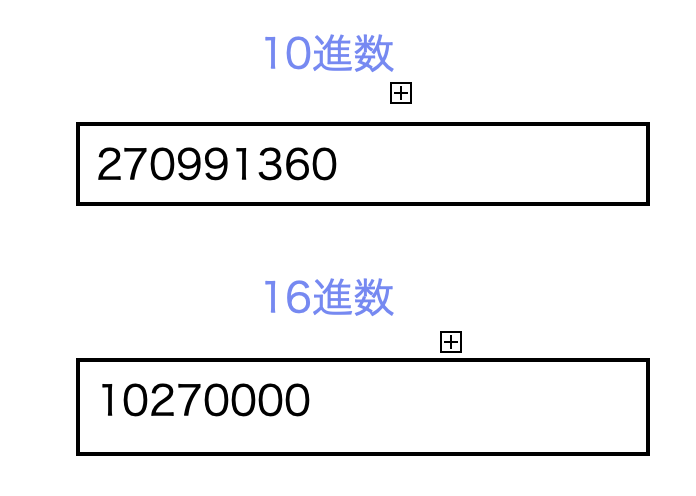
$ go run littleendian.go
data: 270991360
ビッグエンディアンのときと違って、10000ではなく、270991360と表示されています。
データの先頭byteを小さいアドレスに置くか、大きいアドレスに置くかの違いです。
下記の図をみると、イメージが掴めるかもしれません。
ビッグエンディアンのとき
リトルエンディアンのとき
以上です。
参考リンク
分かりやすい記事をありがとうございます。