データの取得
ダッシュボード製作にあたり、必要な情報を取得しました。
自宅では、ソーラーパネルを設置しており、ポータルサイトから動作状況を確認できます。
で、ログインすると、下記のような画面が表示されます。

ここに、ログイン、スクレイピングして、必要な数値を出力することを目的としました。
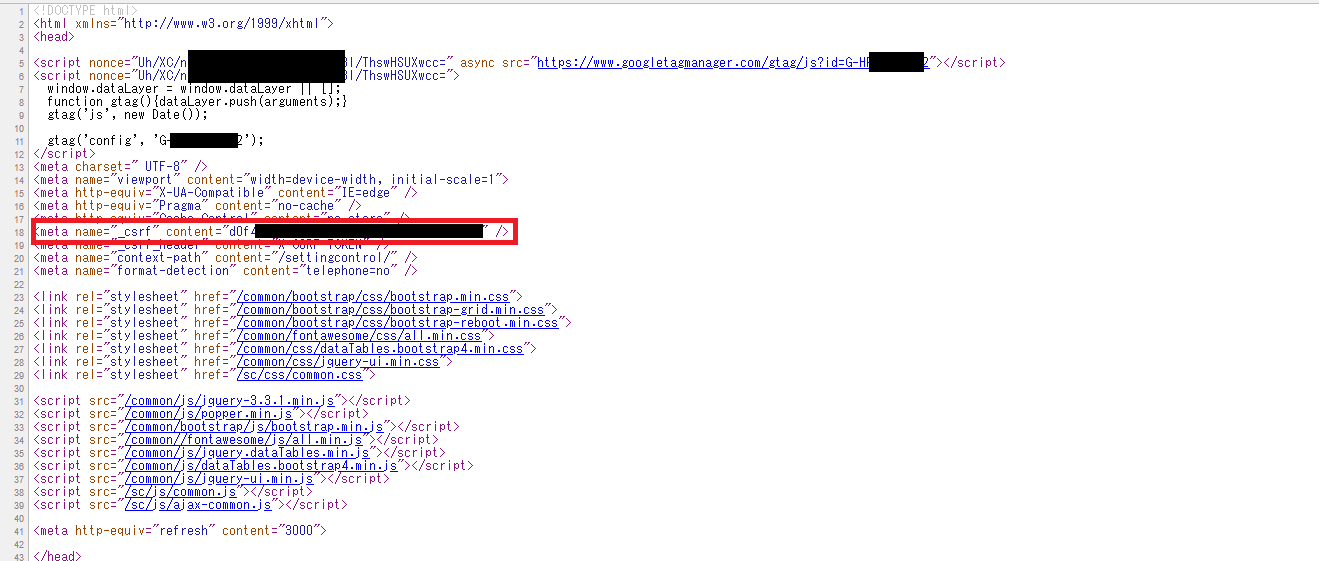
ログインに必要なペイロード
Chrome上ログイン画面で、F12でなにが送信されているのか調べました。
ID、PASSのほか、非表示のcsrfの入力が必要でした。
最終的には、HTMLを見たら、どんな形でブラウザから受け取っているのかわかりました。
csrfの壁
認証には、アクセス毎に変わるワンタイムパスワード的なものが必要になります。
当初は、サーバーレスにて実行できるGASで進めていましたが、
これらに関する情報が少なく、python3で作成しました。
を参考にしました。
# -*- coding: utf-8 -*-
# 20240130
import requests
from bs4 import BeautifulSoup
import re
import datetime
t_delta = datetime.timedelta(hours=9)
JST = datetime.timezone(t_delta, 'JST')
now = datetime.datetime.now(JST)
# 1.ログインページにアクセスする
# ref:https://rurukblog.com/post/requests-cookies-session/
url_login = "https://ctrl.kp-net.com/settingcontrol/processLogin"
session = requests.session()
# ログインページへのアクセス完了
req_before_login = session.get(url_login)
# ログインするための情報を準備する
login_data = {
'loginid': 'xxxxxxxxxxxxxxxxxx',
'loginpassword': 'yyyyyyyyyyyyyyyyy'
}
# ログインするためにcsrfトークンが必要となるため情報を取得
bs = BeautifulSoup(req_before_login.text, 'html.parser')
csrf_token = bs.find(
attrs={'name':'_csrf'}).get('content')
login_data['_csrf'] = csrf_token
# 2. ログインページで認証を行い、管理者ページへ遷移する
req_after_login = session.post(url_login, data=login_data)
# 3. 認証完了後のページで他ページへ遷移を行う
url_group = 'https://ctrl.kp-net.com/settingcontrol/remotevisualization/simplevisualization/enduser/'
req_group = session.get(url_group)
#print('--- ログイン情報 ---')
#print(login_data)
#print('---- 認証ページへのアクセス結果 ---')
#print(re.search(r'<title.*', req_before_login.text).group(0))
#print(req_before_login.status_code)
#print('--- 認証完了ページへのアクセス結果 ---')
#print(re.search(r'<title.*', req_after_login.text).group(0))
#print(req_after_login.status_code)
#print('--- 認証完了ページからgroupページへのアクセス結果 ---')
#print(re.search(r'<title.*', req_group.text).group(0))
#print(req_group.status_code)
# print(req_group.text)
html = req_group.text
text_without_newlines = req_group.text.replace('\n', '')
# print(text_without_newlines)
# 特定の文字までを削除
target_string = '></i><br>発電 </th> <th>現在(平均値)</th> <th class="rt_cell">本日累計</th> </tr> <tr> <td> '
temp_text = text_without_newlines.split(target_string, 1)[1]
genea = temp_text[:3]
target_string = '<span>kW</span> </td> <td class="rb_cell"> '
temp_text = temp_text.split(target_string, 1)[1]
genet = temp_text[:3]
target_string = '現在(平均値)</th> <th class="rt_cell">本日累計</th> </tr> <tr> <td> '
temp_text = temp_text.split(target_string, 1)[1]
usaga = temp_text[:3]
target_string = '<span>kW</span> </td> <td class="rb_cell"> '
temp_text = temp_text.split(target_string, 1)[1]
usagt = temp_text[:3]
# print(genea) # 発電現在平均
# print(genet) # 発電本日累計
# print(usaga) # 消費現在平均
# print(usagt) # 消費本日累計
target_string = '動作状態</th> <th class="rt_cell">蓄電残量</th> </tr> <tr> <td> '
temp_text = temp_text.split(target_string, 1)[1]
btst = temp_text[:2]
target_string = '</td> <td class="rb_cell"> '
temp_text = temp_text.split(target_string, 1)[1]
btlv = temp_text[:5]
target_string = '売電</th> <th class="line_cell line_cell01">現在(平均値)</th> <th class="line_cell line_cell01">本日累計</th> </tr> <tr> <td> '
temp_text = temp_text.split(target_string, 1)[1]
sella = temp_text[:3]
target_string = '<span>kW</span> </td> <td> '
temp_text = temp_text.split(target_string, 1)[1]
sellt = temp_text[:3]
target_string = '現在(平均値)</th> <th class="line_cell line_cell02">本日累計</th> </tr> <tr> <td> '
temp_text = temp_text.split(target_string, 1)[1]
buya = temp_text[:3]
target_string = '<span>kW</span> </td> <td> '
temp_text = temp_text.split(target_string, 1)[1]
buyt = temp_text[:3]
# print(btst)
# print(btlv)
# print(sella)
# print(sellt)
# print(buya)
# print(buyt)
date = now.strftime('%Y/%m/%d %H:%M:%S')
text_file = open("solar.txt", "a")
output = date + ","+genea + ","+genet + ","+usaga + ","+usagt + ","+btst + ","+btlv + ","+sella + ","+sellt + ","+buya + ","+buyt+"\n"
text_file.write(output)
print(output)
まずは動作確認
実行すると、カレントディレクトリにsolar.txtが作成され、必要な数値が出力されます。
正規表現など使ったらいいのでしょうが、まずは一旦適当に必要な情報を抜いています。
2024/01/30 11:22:31,1.9,4.3,1.4,10.,充電, 22 ,0.0,0.0,0.0,6.9
2024/01/30 11:24:47,1.9,4.3,1.4,10.,充電, 22 ,0.0,0.0,0.0,6.9
2024/01/30 11:25:23,1.9,4.3,1.4,10.,充電, 22 ,0.0,0.0,0.0,6.9
GASへの実装
どうやら、GASでも実行できそうに思います。
次回に続きます。
ここにcsrfがあり、GASでHTMLを受けて、中身を解析することで対応できそうです。