概要
Google Vision APIを使ったOCR結果をもとにレシートの合計金額を抽出します。
前提となる記事
下記の記事を前提としています。
データフローは下記のようになっており、
データの抽出には下記の関数を用いました。以降はこの生成物であるlinesを前提とします。
(ざっくりいうと[x,y,text,symbol.boundingbox]を格納したリストのリストです。)
def get_sorted_lines(response,threshold = 5):
"""Boundingboxの左上の位置を参考に行ごとの文章にParseする
Args:
response (_type_): VisionのOCR結果のObject
threshold (int, optional): 同じ列だと判定するしきい値
Returns:
line: list of [x,y,text,symbol.boundingbox]
"""
# 1. テキスト抽出とソート
document = response.full_text_annotation
bounds = []
for page in document.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
for symbol in word.symbols: #左上のBBOXの情報をx,yに集約
x = symbol.bounding_box.vertices[0].x
y = symbol.bounding_box.vertices[0].y
text = symbol.text
bounds.append([x, y, text, symbol.bounding_box])
bounds.sort(key=lambda x: x[1])
# 2. 同じ高さのものをまとめる
old_y = -1
line = []
lines = []
for bound in bounds:
x = bound[0]
y = bound[1]
if old_y == -1:
old_y = y
elif old_y-threshold <= y <= old_y+threshold:
old_y = y
else:
old_y = -1
line.sort(key=lambda x: x[0])
lines.append(line)
line = []
line.append(bound)
line.sort(key=lambda x: x[0])
lines.append(line)
return lines
方策
レシートなんだから「合計」の文字を探して同じ列か下の列の金額を抜き出せばいいだろう と思っていた時期が私にも有りました。
「合計」の文字はなんか潰れていることが多く、OCRできていないことが多々あります。(なんてこった!)
また、そもそも「現計」など別の表記になっているレシートもあり非常に闇が深いです。
例:以下様々な「合計」の表記たち。
| 現計 | 信用 | 対象計 |
|---|---|---|
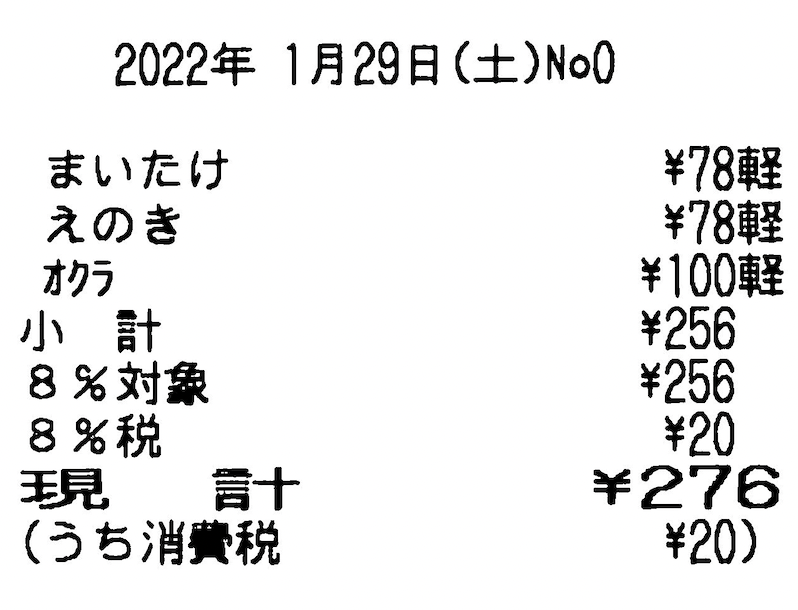 |
 |
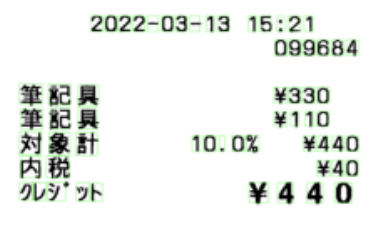 |
さてどうしたものか。。。
開発手順としては日付のときと同じく、「簡単に抜き出せるケースから順に実装してだめだった場合の穴を埋めていく」という方針でしたが記事が無限に長くなるのでここではダイジェスト版をお送りします。
処理フロー
紆余曲折あって現状採用している処理フローについて記述します。
| No | 処理内容 |
|---|---|
| 1 | OCR結果の単語を行ごとにまとめてリストに変換 |
| 2 | 「合計、小計、現計 etc」に合致するキー表現の登場する列番号をそれぞれ抽出 |
| 3 | 金額の記述の登場する列を抽出 |
| 4 | キー表現に対応する金額を抽出 |
| 5 | 抽出した金額から真の合計金額を推定 |
最後のプロセスがなぜ必要かというと、
- 「合計」はほぼ確実に品物の総額を表すが「お支払合計」のような引掛けが存在する
- 「小計」は税抜・税込みの2パターンがあり、小計の後に値引きが入る場合もある
- 「現計」は合計の代わりの時と「現金で渡した額=お釣り込み」を表す場合がある
といった事があるからです。はやく統一してくれ…
行ごとに単語を抽出
前提のところで述べた関数に行ごとの単語情報が詰まっているのでそこから行順に文章のリストを抽出するようにします。
# stringのリストを返す
def get_line_texts(response):
lines = get_sorted_lines(response)
texts = []
for line in lines:
texts.append(''.join([i[2] for i in line]))
return texts
一部を見せると下記の様なリストを取得します。
[...
'1点セット',
'[TO小計]-',
'9点¥500',
'合計¥500',
'(10%対象¥0消費税\\0)',
'(8%対象¥463消費税¥37)',
'交通系IC¥500',
'交通系IC残高は以下の通りです',
'交通系IC取扱日',
...]
合計、小計、現計などのキー表現のある行番号を抜き出し
正規表現で特定の表現に合致する行を抜き出します。
これは正規表現のpatternを変更して何度も使うので関数化しがいがありますね。
def search_gokei_pattern(texts,pattern):
"""
パターンに合致する行番号のリストを返す
Args:
texts: list of string
pattern: 正規表現のパターン
"""
pattern_matched = []
for i in range(len(texts)):
text = texts[i]
if re.search(pattern,text):
pattern_matched.append(i)
return pattern_matched
正規表現は下記のように設定しています。闇を感じます。
| サーチ対象 | 正規表現 | 備考 |
|---|---|---|
| 合計 | r'^[合] ?計' |
「お支払合計」などを排除するため文頭に限定 |
| 小計 | r'[小] ?計' |
小計は文頭じゃなくても出るので解除 |
| 現計 | r'^[現] ?計' |
知らなかった |
| お買上計 | r'買上計' |
イトー○ーカドー対策 |
| 対象計 | r'^対象計' |
**計みたいな感じでまとめたいが... |
| 信用 | r'^信用' |
いるのか?これ |
金額表現の抽出
金額の抽出も結構癖が強いです。
金額は一般に ¥300 のような表記になっているかと思いきや *300 のように書いてあったりもします。あんまりレアなケースはこちらも考えたくないのでひとまず上の2パターンのみを考えることにしました。
場合によってはスペースが入ったり区切りのカンマやその見間違いのピリオドが入るので最終的にr'[¥\*][ \d,.]+'としました。
# stringから金額を抽出する関数
def match_price_string(text):
pattern = r'[¥\*][ \d,.]+'
match = re.search(pattern, text)
if match:
match_text = match.group()
for sp_char in [" ",",","."]:
match_text = match_text.replace(sp_char,"")
price = match_text[1:]
return price
else:
return ''
def search_price_string(texts):
"""
テキストのリストを{行番号: 金額} のdictにして返す
"""
price_matched = {}
for i in range(len(texts)):
text = texts[i]
if match_price_string(text):
price_matched[i] = match_price_string(text)
return price_matched
キー表現に対応する金額を抽出
金額は基本キー表現の同列か上下の列にあると考えられるので下記の順番で探していきます。

このあたりで面倒になったのかコードが雑になってきていますね…
def match_gokei_price(texts,pattern):
"""
特定のパターンに合致する金額のstirngを返す。なければ空の文字列を返す。
"""
pattern_matched = search_gokei_pattern(texts,pattern)
price_matched = search_price_string(texts)
for idx in pattern_matched:
try:
return price_matched[idx]
except:
try:
return price_matched[idx+1]
except:
try:
return price_matched[idx-1]
except:
continue
return ''
それぞれの正規表現に対応する金額を辞書で保持
合計グループ、 小計グループ、 その他・現計グループの3つに金額を分けてそれぞれの金額を保持しておきます。
漏れを極力なくすために上記で言及していないやばいパターンを内包していますがそこは気にしない方向で。
def extract_gokei_prices_dict(response):
texts = get_line_texts(response)
gokei_patterns = [r'^[合] ?計', r'買上げ?計', r'対象計']
shokei_patterns = [r'[小] ?計']
other_patterns = [r'[現] ?計', r'信用',r'決済',r'金額',r'支払']
gokei , shokei , other_kei = '','',''
for gp in gokei_patterns:
temp = match_gokei_price(texts,gp)
if temp:
gokei = temp
break
for sp in shokei_patterns:
temp = match_gokei_price(texts,sp)
if temp:
shokei = temp
break
for op in other_patterns:
temp = match_gokei_price(texts,op)
if temp:
other_kei = temp
break
gokei_dict = {}
gokei_dict["合計"] = gokei
gokei_dict["小計"] = shokei
gokei_dict["現計等"] = other_kei
return gokei_dict
有効な金額のみを保持する
表記ずれなどの対策のために基本的に金額が20円以下の場合は自動的にそちらを却下するようにしています。
def check_valid_prices(gokei_dict, min_price = 21):
"""
一定の金額以下を排除
"""
for key in gokei_dict.keys():
if gokei_dict[key] == '':
continue
elif int(gokei_dict[key]) < min_price:
gokei_dict[key] = ''
else:
continue
return gokei_dict
ちゃんとした合計金額になっているか吟味する
- 1種類しか計算できてない場合
- そのまま処理する
- 2種以上抽出できている場合
- 「合計」と「現計」の組み合わせ
- 基本的に現金計よりも合計を信用する
- 「合計」と「小計」の組み合わせ
- 合計=小計のときは合計値を採用
- 合計 > 小計のときは合計が小計の1.08倍か1.1倍付近になっていることを確認して合計値を採用。そうでない場合は小計×1.08とする。
- 小計 > 合計のとき、特に根拠はないですが「合計」の金額を採用します。
- 「合計」と「現計」の組み合わせ
- その他のパターン
- ちゃんと考えてません!! 特に根拠なく「合計」の金額を採用します。
- 一応小計は割引などで計算が合わない事が多いことなどを加味してはいます。
def response_to_valid_gokei_prices(response):
"""
合計・小計・現計等から有効そうな金額を選ぶ
"""
gokei_dict = check_valid_prices(extract_gokei_prices_dict(response))
nonzero = sum([1 if gokei_dict[i] else 0 for i in gokei_dict.keys() ])
if nonzero == 0:
return ''
elif nonzero == 1:
price = ''.join([gokei_dict[i] for i in gokei_dict.keys()])
else:
price = decide_valid_gokei_prices(gokei_dict)
return price
def decide_valid_gokei_prices(gokei_dict):
gokei = gokei_dict["合計"]
shokei = gokei_dict["小計"]
other_kei = gokei_dict["現計等"]
if shokei == '':
return gokei
else:
taxed_shokei = int(int(shokei) * 1.08)
taxed_shokei_strs = [str(taxed_shokei), str(taxed_shokei+1)]
if shokei == gokei or shokei == other_kei:
return shokei
elif gokei in taxed_shokei_strs:
return gokei
elif other_kei in taxed_shokei_strs:
return other_kei
elif gokei:
return gokei
else:
return other_kei
感想
ベースとなるアイデアはシンプルですが、OCRに伴う表記ゆれやレシートそのものの表記ゆれを吸収するためにとんでもなく泥臭いプロセスになってしまいました。
OCRを出来合いのもので済ましているので本番の製品はもっとOCRの部分に工夫を入れたり、情報抽出にも画像の位置情報などを盛り込んでいるんだろうなと勝手に思っています。
しかしレシートの表記は早く標準化されてほしい…