はじめに
今回はElasticsearchとKibanaを使った、Twitterダッシュボードの作成方法についての解説しています。Elasticsearchに関する前提知識はなくても、最後までたどり着ける構成になっている(はず?)なので、是非参考にして頂ければと思います。
単につぶやきデータを収集したいという場合は、TwitterのAPIを好みのスクリプトで呼び出して取得すれば良いのですが、今回の場合はつぶやき数の推移を追いたい、踏み込んだ分析も行いたいなどという目的もあったので、データがストックされていき、ドリルダウン分析も可能な環境を構築する形で対応する事にしました。
Redash / Googleスプレッドシートのアドインなど色々と実現手段は考えられたのですが、Elastic Stackで構成するのが1番手軽かつ、要件を満たせると考え実装しました。同じように特定のキーワードを含むつぶやきデータを分析・可視化したいという方は、是非参考にして頂ければと思います。
対象読者
- 特定のキーワードを含むTwitterのつぶやきを自動で収集->分析する環境を作りたい方
- Elasticsearch/Kibana/Logstashのザックリした機能を把握したい方
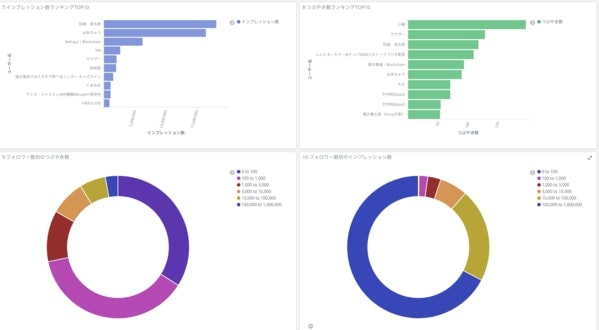
完成物の一部
つぶやき回数の集計

●つぶやきトレンドの把握

●よくつぶやいているユーザーさんの把握
実装方法
Elastic Stackとは、Elastic社の製品をまとめた通称のことで、その中でもElasticsearch / Logstash / Kibanaの3つが主要なプロダクトとなっています。ザックリ説明をすると、以下のような関係性です。

Logstashには、Twitterのつぶやきデータを取得するためのTwitterInputPluginが用意されているので、今回はこちらを利用しています。
全体の構成図は以下のようになっています。

手順1:ElasticsearchとKibana、Logstashの実行環境をセットアップする
まずは最初に環境構築を行いましょう。ElasticStack自体はWindows/Mac/LinuxいずれのOSにも対応しているのですが、今回は常時起動させておきたかったので、AWS上のインスタンスに環境をセットアップしました。ドキュメントに従って進めていけば問題ないかと思います。
環境構築が手間でとりあえず試してみたいという場合は、AmazonElasticsearchServiceか、ElasticCloudを使いましょう。コマンドを叩く必要もなく、直ぐに触ってみる事ができます。特に、ElastiCloudは手軽に導入できておすすめ。
詳しくは、他のドキュメントにお任せしますがKibanaとLogstashについても、ElasticSearchと同様にインストールしておきます。
このステップが終われば、Logstashでデータを取得->転送し、ElasticSearchに蓄積した後、Kibanaで可視化できる、Elastic Stackのコア機能のセットアップが完了しているはずです。
手順2:Logstashの設定ファイルを作成->起動する
それでは、LogstashでTwitterのつぶやきデータをElasticSearchに流し込む部分を作っていきます。シンプルですが、設定ファイルを記述し、プロセスを起動する事で直ぐに動かし始める事ができます。
設定ファイルは .confの拡張子で作成。
①Logstashの設定ファイルを作成する
input {
twitter {
# TwittrAPIの認証情報を入力
consumer_key => "ご自身の認証情報"
consumer_secret => "ご自身の認証情報"
oauth_token => "ご自身の認証情報"
oauth_token_secret => "ご自身の認証情報"
# つぶやきの検索対象に含めるキーワードを配列で指定する
keywords => ["voicy","ボイシー","ぼいし-"]
full_tweet => true
}
}
output {
elasticsearch {
# ElasticSearchのホストパス
hosts => ["http://localhost:9200/"]
# インデックス名
index => "twitter_import"
}
}
Logstashの優れている点の1つに、様々なデータソースに対応したプラグインがあらかじめ用意されている点があります。10分で構築!と書いたのは、誇張ではなく、認証情報とウォッチしたいキーワードを設定するだけで、直ぐにデータの収集を開始する事ができるのです。便利!(ドキュメントはこちら)
Twitterの認証情報を取得する方法は、この辺りを見れば問題ないかと
②起動する
起動コマンド
sudo /usr/share/logstash/bin/logstash --path.settings=/etc/logstash/ --path.data ログの保存パス -f 設定ファイル
プロセスを起動します。バッチでAPIを叩いてくれるので、自動でデータを収集し続けてくれます。正しく設定できれば、以下のようにKibana上でにつぶやきのデータが格納されている事が確認できるはずです。
停止するときは、プロセスをKillして停止しています。(調べきれていないので、他の方法もあるかもしれません)
停止コマンド
# -9フラグで強制停止
kill -9 [プロセスID]
 ### 手順3:Kibanaでダッシュボード作成
KibanaはElasticsearchと連携しているビジュアライゼーションツールで、ElasticSearch内に保存されているデータを、可視化する用途で使われます。
### 手順3:Kibanaでダッシュボード作成
KibanaはElasticsearchと連携しているビジュアライゼーションツールで、ElasticSearch内に保存されているデータを、可視化する用途で使われます。
それ以外にも、データの追加や削除もKibana上から使用できるようになっており、検索クエリの発行なども行えます。
グラフの作成インターフェイスも分かりやすいので、Tablearu /Redash/DOMO辺りのBIツールを使った事のある方はサクサク作れると思います。グラフをガシガシ作成してダッシュボードに配置していきます。
 ## 完成しました
今回作成したダッシュボードを使用する事で、特定のキーワードを含むTwitteつぶやきを1箇所にまとめ、一覧することができます。
## 完成しました
今回作成したダッシュボードを使用する事で、特定のキーワードを含むTwitteつぶやきを1箇所にまとめ、一覧することができます。
また、深掘りしたくなった時に以下のような問いに対しても答えを出す事ができるようになりました。
どのユーザーがよくつぶやいているのか? 情報発信が活発な時間帯はいつか? ツイート数のトレンドはどのように変化しているのか?
以上、Twitterのダッシュボード分析環境を構築してみたという話でした。エゴサーチのし過ぎで目がチカチカしている方がいたら、業務効率化の為に是非取り入れてみて下さい!