この記事について
- グラフデータベースについて学習するために、以下の書籍を読んだ。内容について、備忘録(兼 共有用資料)として、メモを残しておく。興味のある人は、実際に本を買って読むのが早いです。
- グラフデータベース ―Neo4jによるグラフデータモデルとグラフデータベース入門 Ian Robinson
出典情報
『Graph Databases』(Ian Robinson,Jim Webber, Emil Eifrem 著, O'Reilly, Copyright 2013 Neo Technology, ISBN978-1-449-35626-2, 邦題『グラフデータベース』オライリー・ジャパン、ISBN978-4-87311-714-0
書籍内に、【出典を明らかにしていただくのはありがたいことですが、必須ではありません】と記載があります。一部読みやすいように修正を施し、正確な引用記述を欠いている部分がありますが、ご了承ください!
対象読者
- グラフデータベースって何?という状態だけど、何か知ってみたい人
読むとこうなる
- グラフデータベースについて、基本的な概念/メリットが分かって自分でも触ってみたくなる...と思う。
目次
- 1章 はじめに
- 2章 つながりのあるデータを格納するための選択肢
- 3章 グラフでのデータモデリング
まとめ
1章 はじめに
疑問①:グラフって何??
正式には、グラフは単なる頂点(vertex)と辺(edge)の集合です。または、少しなじみやすい言葉で言うと、一連のノード(節点)とそのノードをつなぐ関係(リレーション)です。
----- 省略 -----
例えば、Twitterのデータは簡単にグラフで表せます。フォロワーの小さなネットワークがわかります。ここでは、意味的文脈を定めるのに関係が重要です。(P2)
- Twitterのソーシャルグラフ
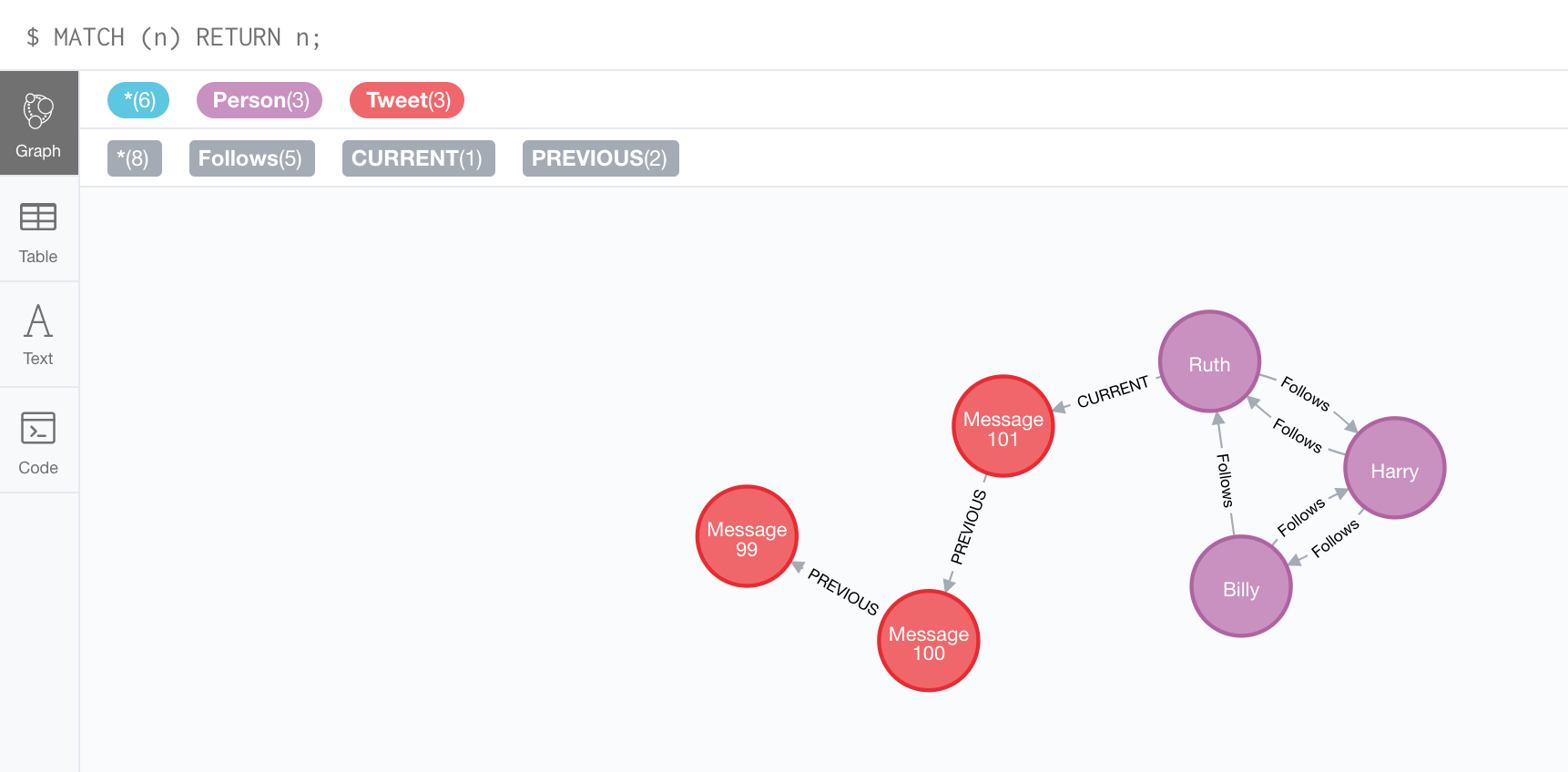
- ユーザーと、公開したメッセージで、__2種類のノード__が存在。
- フォローを示す"Follows"/直近の投稿である事を示す"CURRENT"/1つ前の投稿である事を示す"PREVIOUS"で、__3種類の関係__が存在。
- "Ruth"から"CURRENT"を辿る事で、直近のメッセージを簡単に追跡する事ができる。
プロパティグラフモデルの持つ特徴
- 上記の図では、グラフモデルの最も一般的な一種であるプロパティグラフモデルを非公式に紹介しています。プロパティグラフは、以下の特徴を備えています。
- プロパティグラフには、ノードと関係が含まれている
- ノードには、プロパティ(キー/値 ペア)が含まれている
- 関係には名前と方向があり、必ず開始ノードと終了ノードがある
- 関係にもプロパティを含めることができる
アンサー:
- ノードと関係で表現される、つながりに重きをおいたデータ表現。プロパティグラフモデルと、RDFモデルが主流
疑問②:グラフデータベースって何が美味しいの??
- グラフデータベースが強力ながらも斬新なデータモデリング技術を提供する事自体が、よく理解されている確立したデータプラットフォームを置き換えるための十分な理由になる訳ではありません。__グラフデータベースの場合は、この利点は、ユースケースやデータパターンをグラフで実装した時にパフォーマンスが1桁以上改善し、集約のバッチ処理と比較して遅延が大幅に小さくなることとして現れます。(P7)
パフォーマンス
- データセットが大きなるにつれ結合集約的なクエリのパフォーマンスが悪化するリレーショナルデータベースとは対照的に、グラフデータベースではデータセットが大きくなってもパフォーマンスが比較的一定のままである傾向があります。(P7)
柔軟性
- 開発者やデータアーキテクトはドメイン(対象領域)で表されるとおりにデータをつなぎたいので、データの本当の形や複雑さが全く分からない段階で事前に構造やスキーマを無理やり作成するのではなく、問題ドメインの理解が進むのに合わせて形にする必要があります。グラフデータモデルはITをビジネスの速度で変えることができるように、ビジネスニーズを表し、それに対応します。(P7)
アジャイル性
-
グラフデータモデルのスキーマのない性質は、グラフデータベースのアプリケーションプログラミングインターフェース(API)とクエリ言語のテスト可能な性質と相まって、アプリケーションを管理された方法で進化させることを可能にします。(P7)
-
同時に、スキーマがないからこそ、グラフデータベースにはリレーショナル領域で馴染みのあるスキーマ指向のデータガバナンスメカニズムが欠けています。しかし、これはリスクではありません。通常はデータモデルやクエリをテストし、グラフに依存するビジネスルールをアサート(表明)するテストを使ってプログラム的にガバナンスを適用します。(P8)
アンサー:
- データが膨張しても高いパフォーマンスを発揮するし、スキーマレスなのでビジネスの早い流れについていけるし、テストも簡単に実施できるからイイ!
読後感想:
- 確かに、BigQueryで回しても計算に時間がかかる、アプリケーションに組み込むのは厳しい処理は多くある。グラフに載せ替える事でメリットの大きい計算処理は多そう。めっちゃサマルと、計算コストの高い多重JOINを避けられる これに尽きる感じ。
- 設計段階から"このクエリを発行したい" --> "どうモデリングするか?"という、テスト駆動開発に近い思想で作っていけるのは、直感的にクエリが理解しやすいからっていうのもポジ要因。
- スキーマを変更(ノードのプロパティを変更/新しい関係の追加)などを行っても、他の処理に影響を与えない特性は安心感がある。ただ、むやみやたらに追加すると処理が重くもなると思うので、ビジネスロジックに使用しない、情報はグラフに含めない。は基本姿勢になりそう。
2章 つながりのあるデータを格納するための選択肢
疑問③:リレーショナルデータベースってそんなに良くないの??
-
数十年にわたって、開発者はリレーショナルデータベースの内部でつながりのある半構造化データセットに対応しようとしてきました。(省略)〜 一方で、実世界で出現するアドホックで例外的な関係をモデリングしようとすると苦労します。皮肉にも、リレーショナルデータベースは関係性を扱うのが下手なのです。 (P9)
-
この先は、ソーシャルグラフの分析を事例に、リレーショナルデータベースのパフォーマンスが出ないケースをひたすらに解説....!
アンサー:
- RDBに恨みでもあるのかの如く、バッサリ切られていた。確かに、つながりのあるデータを取り扱うには向いてないよなと思う。JOIN地獄に陥りがち。
疑問④:NoSQLデータベースってそんなに良くないの??
-
ほとんどのNoSQLデータベース(キーバリュー指向、ドキュメント指向、またはカラム指向)は、つながりのない一連のドキュメント/値/列を格納します。そのため、つながりのあるデータやグラフに使うのが困難になります。(P12)
-
この先は、ソーシャルグラフの分析を事例に、NoSQLデータベースのパフォーマンスが出ないケースをひたすらに解説....!
-
関係のトラバーサル(走査)はコストがかかります。これは、ソーシャルネットワークの拡大の機会を制限するだけでなく、利益をもたらすレコメンデーションを減らし、データセンターの欠陥機器を見逃し、不正な購買活動がネットをすり抜けます。多くのシステムはグラフのような処理の体裁を維持しようとしますが、必ずバッチで実行され、ユーザーが求めるリアルタイムなやり取りを提供しません。(P12)
アンサー:
- トラバーサルの範囲が拡大しがちで、最大パフォーマンスを発揮できないケースも多いとの事。
疑問⑤:グ、、、グラフデータベースはどうなの??
- 前述の例は、__暗黙的__につながりのあるデータを扱っていました。ユーザーはエンティティ間の意味的依存関係を推論しますが、データモデル(およびデータベース自体)はこのような関連がわかりません。(P16)
- 本当に必要なのは、要素間のつながりを含むまとまりのある全体像です。先ほど見たストアとは対象的に、グラフ領域では__つながりのあるデータをつながりのあるデータとして格納します。__(P16)
- このソーシャルネットワークでは、実世界でのつながりのデータの多くの事例のように、ドメイン内でのエンティティ間のつながりに統一性がありません。ドメインが半構造化されているのです。(P16)
- グラフモデルの柔軟性により、既存のネットワークに支障をきたしたりデータを移行しなくても、新しいノードや関係を追加できます。元のデータとその意図は損なわれません。(P16)
- グラフはずっと豊かなネットワーク像を提供します。誰が誰を愛しているか(LOES)(そしてその愛が報われているかどうか?)がわかります。(P16)
図2-5 グラフでの友達、同僚、労働者、片思いの簡単なモデリング
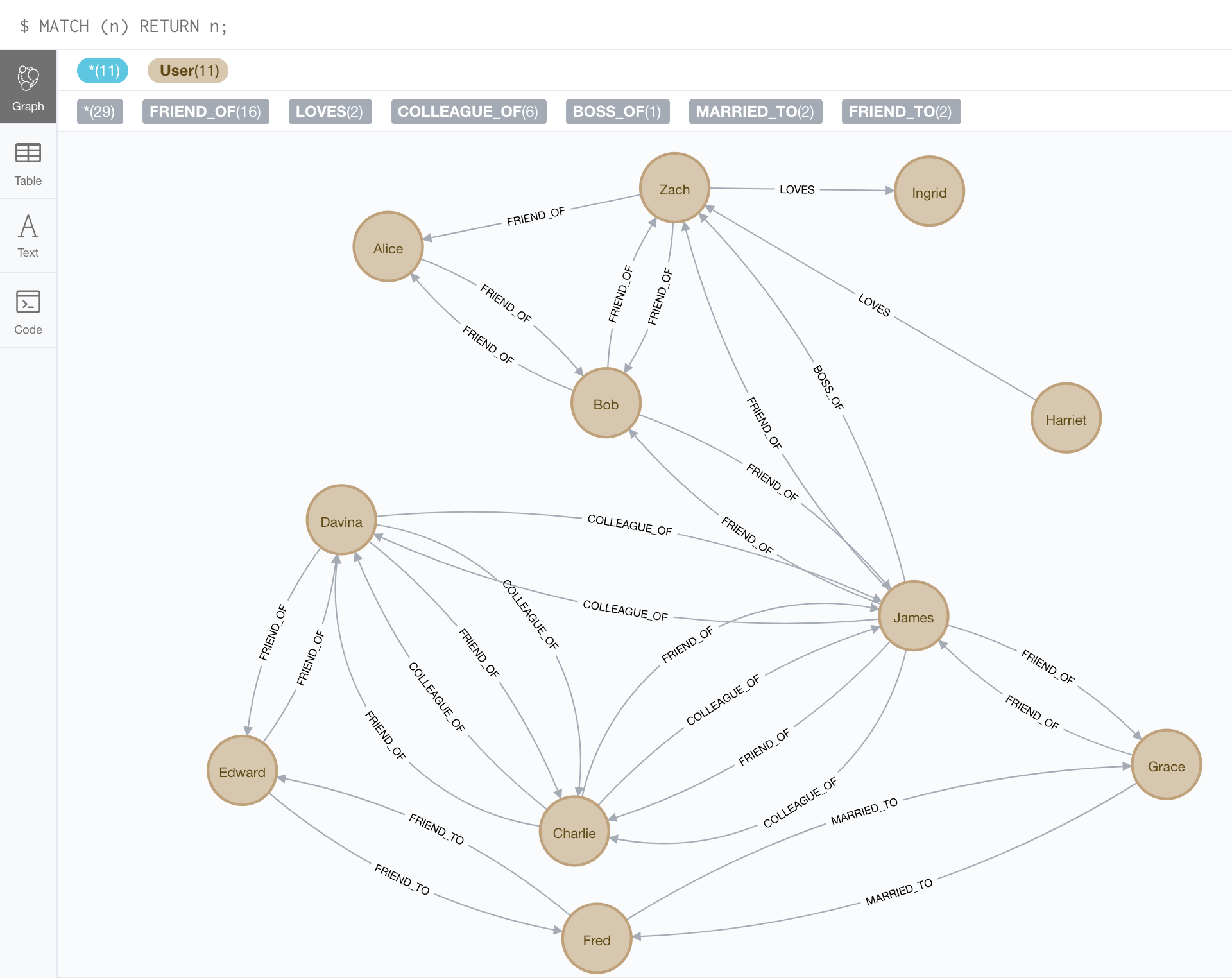
- グラフの生成コード(Cypher)
CREATE
(Alice:User{name:"Alice"}),
(Bob:User{name:"Bob"}),
(Zach:User{name:"Zach"}),
(James:User{name:"James"}),
(Harriet:User{name:"Harriet"}),
(Ingrid:User{name:"Ingrid"}),
(Grace:User{name:"Grace"}),
(Fred:User{name:"Fred"}),
(Charlie:User{name:"Charlie"}),
(Davina:User{name:"Davina"}),
(Edward:User{name:"Edward"}),
(Alice)-[:FRIEND_OF]->(Bob),
(Alice)<-[:FRIEND_OF]-(Bob),
(Alice)<-[:FRIEND_OF]-(Zach),
(Bob)<-[:FRIEND_OF]-(Zach),
(Bob)-[:FRIEND_OF]->(Zach),
(Bob)<-[:FRIEND_OF]-(James),
(Bob)-[:FRIEND_OF]->(James),
(Zach)<-[:FRIEND_OF]-(James),
(Zach)<-[:BOSS_OF]-(James),
(Zach)-[:LOVES]->(Ingrid),
(Zach)<-[:LOVES]-(Harriet),
(James)-[:FRIEND_OF]->(Charlie),
(James)<-[:FRIEND_OF]-(Charlie),
(James)-[:COLLEAGUE_OF]->(Charlie),
(James)<-[:COLLEAGUE_OF]-(Charlie),
(James)<-[:FRIEND_OF]-(Grace),
(James)-[:FRIEND_OF]->(Grace),
(James)-[:COLLEAGUE_OF]->(Davina),
(James)<-[:COLLEAGUE_OF]-(Davina),
(Grace)<-[:MARRIED_TO]-(Fred),
(Grace)-[:MARRIED_TO]->(Fred),
(Fred)-[:FRIEND_TO]->(Edward),
(Fred)<-[:FRIEND_TO]-(Edward),
(Davina)<-[:COLLEAGUE_OF]-(Charlie),
(Davina)-[:COLLEAGUE_OF]->(Charlie),
(Davina)<-[:FRIEND_OF]-(Charlie),
(Davina)-[:FRIEND_OF]->(Charlie),
(Davina)-[:FRIEND_OF]->(Edward),
(Davina)<-[:FRIEND_OF]-(Edward);
- データ実務者の観点から見ると、グラフデータベースは複雑で半構造化された密接につながりのあるデータ(つまり、グラフ以外の形式扱うと手に負えない非常に高度なデータセット)を扱うための最適な技術であることは明らかです。
図:リレーショナルデータベースでの友達の検索とNeo4jでの効率的な検索の比較
| 深さ | RDBMS実行時間(秒) | Neo4j実行時間(秒) | 返されたレコード数 |
|---|---|---|---|
| 2 | 0.0616 | 0.01 | ~2500 |
| 3 | 30.267 | 0.168 | ~11万 |
| 4 | 1543.505 | 1.359 | ~60万 |
| 5 | 未完了 | 2.132 | ~80万 |
アンサー:
- データ実務者の観点から見ると、グラフデータベースは複雑で半構造化された密接につながりのあるデータ(つまり、グラフ以外の形式扱うと手に負えない非常に高度なデータセット)を扱うための最適な技術であることは明らかです。 ここに集約されている。
読後メモ:
- レコメンデーションの文脈から考えると、機械学習を用いた手法(協調フィルタリングや、コンテンツベース)と、グラフ理論をもちいた手法(プロパティグラフの走査)は、根本的に異なる手法だと言える。実際にどちらのアルゴリズムが優れているかは、ユーザーの反応が決める事ではあるが、計算のリアルタイム性という点では、グラフ理論ベースに軍配が上がる事は明白。
3章 グラフでのデータモデリング
疑問⑥:グラフデータベースが優れているのは分かったけど、モデリングはどうやるの??
- グラフでのモデリングを深く掘り下げる前に、モデルに関して一般的に説明します。__モデリングは特定の要求や目的を動機とした抽象化作業です。__世界を"ありのまま"に表現する自然な方法はなく、目的を持った多くの選択、抽象化、簡素化がありますが、その中には特定の目的を満たすために役に立つ方法があります。(P21)
- この点ではグラフ表現も変わりません。しかし、おそらくグラフ表現を他の多くのデータモデリング手法と差別化しているのは、論理モデルと物理モデルの密接な親和性です。
- リレーショナルデータ管理手法では、ドメインの自然言語表現から逸脱する必要があります。まず自然言語表現から巧みに論理モデルを引き出し、強制的に物理モデルに変換します。この変換により、世界の概念化とデータベースとのそのモデルのインスタンス化に意味的な不一致が生じます。(P21)
- 現在のグラフデータベースは、__他のどのデータベース技術よりも"ホワイトボードと相性がいい"技術です。__ホワイトボードでの問題の代表的な表示方法はグラフです。表現性の観点では、グラフデータベースは、リレーショナルデータベース実装で長年悩まされてきた分析と実装の間のインビーダンスミスマッチを減らします。(P21)
アンサー:
- 現実世界を自然言語表現で表したものをそのまま設計に落とし込むから、より直感的だよ。ホワイトボードをそのまま使えて楽チンだよ。
読後メモ:
- 第一に"実行したいクエリが成功するか"のみを考えて、直感的に設計できる事はメリット。アーキテクチャ設計時点でコケたとしても、スキーマレス性を生かして後から撤回できるのは良い。
- RDB設計と比べてパフォーマンスチューニングに意識を持たなくても良いのはあるが、コツやノウハウはあるので、実際に設計する場合は、ベストプラクティスをしっかりと把握する必要あり。
疑問⑦:プロパティグラフモデルが持つ特徴って何があるの??
- 要約すると、プロパティグラフモデルには次のような顕著な特徴があります。
- プロパティグラフはノード、関係、プロパティで構成される
- ノードはプロパティを持つ。ノードを、任意のキー/値ペアの形式でプロパティを格納するドキュメントと考える。キーは文字列であり、値は任意のデータ型になる。
- 関係は、ノードをつないで構造化する。関係には必ず方向、ラベル、開始ノード、終了ノードがあり、ダングリング(宙ぶらりんの)関係はない。関係の方向とラベルは、ノードの構造を意味的にはっきりさせる。
- ノードと同様に、関係もプロパティを持つことができる。関係にプロパティを追加できる機能は、グラフアルゴリズムへの追加メタデータの提供、関係への意味(質や重みなど)の追加、実行時のクエリの制約に役立つ。(P22)
アンサー:
- 上に書いた通り。
疑問⑧:グラフデータベースを取り扱うにはどんな言語があるの??
- Cypherは、表現力豊かなグラフデータベースクエリ言語です。Neo4j専用ですが、図を使ってグラフを表す習慣と密接な親和性があるため、グラフをプログラムで正確に記述するのに理想的です。(P23)
- 他のグラフデータベースにはデータをクエリする別の手段があります。Neo4Jをはじめとした多くのグラフデータベースはRDFクエリ言語SPARQLと命令型の経路ベースクエリ言語Gremlinをサポートしています。(P23)
アンサー:
- Cypher / SPARQL / Gremlinの3種類がある。Neo4jで使える、Cypher推してます!
読後メモ:
- AWSのマネージドのグラフデータベースサービス"Amazon Neptune"では、GremlinとSPARQLは対応しているものの、Cypherは現状未対応(泣) Gremlinは、日本語情報もまだ少ないので、ドキュメントを当たって理解していく必要がある。
その他グラフデータベースの学習で参考になったリンク集
公式系
- Amazon Neptune
- neo4j
- The Neo4j Cypher Manual v3.5
- gremlin
活用事例
- [レポート] DAT315 :NIKEにおけるAmazon Neptuneを利用したソーシャルグラフの構築 #reinven
- Large-Scale Real-Time Recommendations with Neo4j
- グラフ型データベースAmazon Neptuneでレコメンデーション検索を試してみる(後編)
Qiita記事
- Cypherのノード(Node)の基本を理解する
- Cypherのリレーションシップ(Relationship)の基本を理解する
- MacでNeo4jを使ってみる