初投稿です。
画像分類の記事が多く、物体検知関係の記事が少ないと思ったので記述します。
次②→
『https://qiita.com/osakasho/items/757df802bd34f907cb43 』
作業環境
PC:Windows
言語:Python3
インストール:Node.js(npmコマンドが使えるように)
IDLEなど:PycharmとAnaconda
モデル学習:GoogleColab を利用します。
Pythonとターミナルが使える状態なら問題なく動作する(とおもいます。)
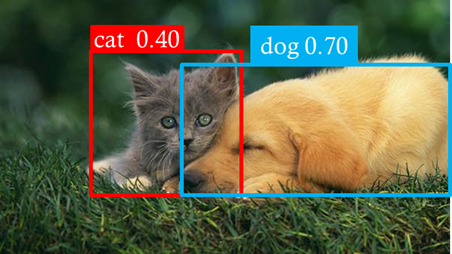
ゴールのイメージ
画像のどこに犬と猫が存在するか表示する。
参考資料等
以下の記事を参照しました。
スクレイピング・画像収集(https://qiita.com/Ikko_Kojima/items/4d943c60ff5e886a0544)
YOLOv3関係全て(https://sleepless-se.net/2019/06/21/how-to-train-keras%E2%88%92yolo3/)
※正直、「眠れない夜」さんの記事ですべて解決します。それくらいわかりやすく凄い記事です。
スクレイピング・画像収集(リサイズ)
まずは、作業用ディレクトリを作りましょう。
mkdir AIprojects_test
cd AIprojects_test
mkdir images
mkdir save_annotations
次に、画像収集するために「Google_images_download」を入れて、ダウンロードします。
pip install google_images_download
googleimagesdownload -ri -cd "chromedriver.exe" -l 100 -k "犬"
googleimagesdownload -ri -cd "chromedriver.exe" -l 100 -k "猫"
すると、ディレクトリの「ダウンロード」に「犬」と「猫」フォルダが生成され、100枚ずつ画像がダウンロードされました。犬フォルダと猫フォルダの中を画像をすべて先ほど作成した「images」の中にコピーしましょう。
├── AIprojects_test
├── save_annotations
└── images
└──犬と猫の画像たち
となっているはずです。
ここで、画像サイズを均等にするためにリサイズします。
resize_images.pyを作成します。
import os
import sys
from glob import glob
from PIL import Image
def resize_images(images_dir, image_save_dir, image_size):
os.makedirs(image_save_dir, exist_ok=True)
img_paths = glob(os.path.join(images_dir, '*'))
for img_path in img_paths:
# resize
image = Image.open(img_path)
rgb_im = image.convert('RGB')
rgb_im.thumbnail([image_size,image_size])
# make background
back_ground = Image.new("RGB", (image_size,image_size), color=(255,255,255))
back_ground.paste(rgb_im)
# make path
save_path = os.path.join(image_save_dir, os.path.basename(img_path))
end_index = save_path.rfind('.')
save_path = save_path[0:end_index]+'.jpg'
#print('save',save_path)
back_ground.save(save_path,quality=95,format='JPEG')
def _main():
images_dir = 'images/' # input directory
image_save_dir = 'resize_images/' # output directory
image_size = 224
if len(sys.argv) > 1:
image_size = int(sys.argv[1])
resize_images(images_dir=images_dir, image_save_dir=image_save_dir, image_size=image_size)
if __name__ == '__main__':
_main()
python resize_images.pyで画像を全て224×224pxにリサイズし、新規フォルダ「resize_images」が作成されます。
ディレクトリ構成が
└── AIprojects_test
├── save annotations
├── images
| └──犬と猫の画像たち
|
├── resize_images
| └──リサイズされた犬と猫の画像たち
|
└── resize_images.py
となっていれば、OKです。
VoTTを使ってアノテーションする
物体検知で一番しんどい作業がアノテーションです。
アノテーションとは正解データを作ることで、これには、マイクロソフトのVoTTを利用します。
VoTTはこのしんどい作業をGUIで楽にしてくれたものです。さすが天下のMicrosoft様、一生ついていきます。
以下の作業ディレクトリで以下の順序で実行してください。
git clone https://github.com/Microsoft/VoTT.git
cd VoTT
npm ci
npm start
しばらく待つと、以下のような画面が出てきます。
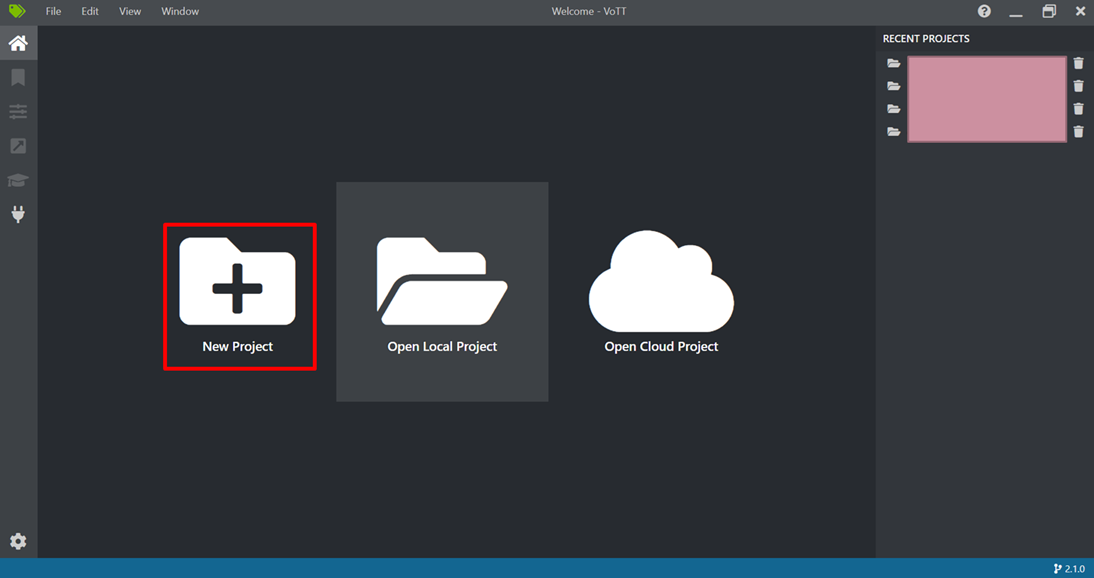
「New Project」を選択し、すると以下のような設定画面が出てきますので、
設定を記述します。
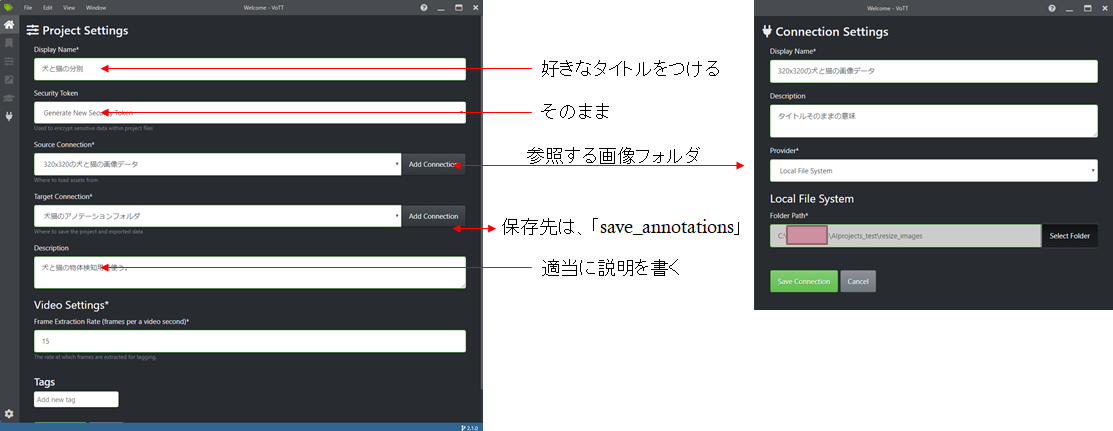
SourceConeectionとは画像の参照先です。先ほどの「resize_images」フォルダを選択しましょう。
TargetConnectionは、アノテーションの保存先です。作成しておいた「save_annotations」に選択します。
最後に、緑色の「Save Connection」をクリックします。
次に、出力の設定を行います。
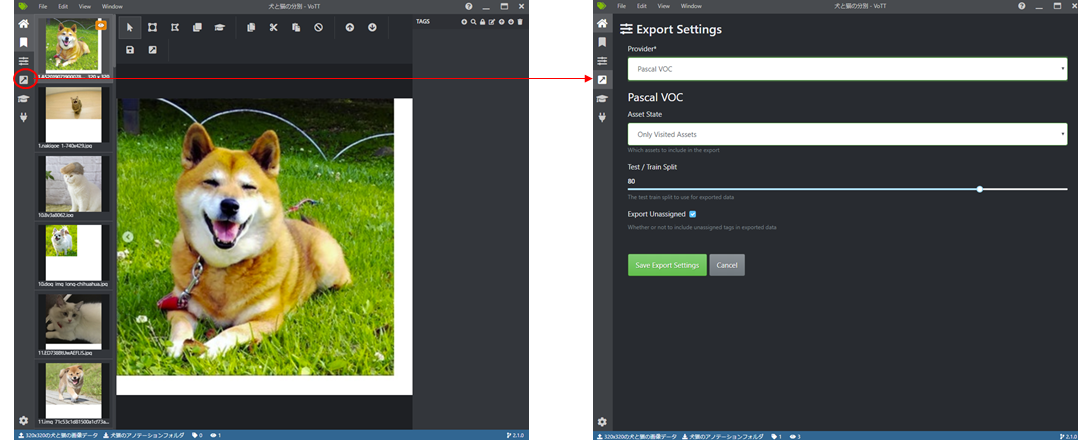
Export Settingsを開き、ProviderをPascal VOCに設定し、Save Export Settingsで保存します。
とうとう、アノテーションを実施します。
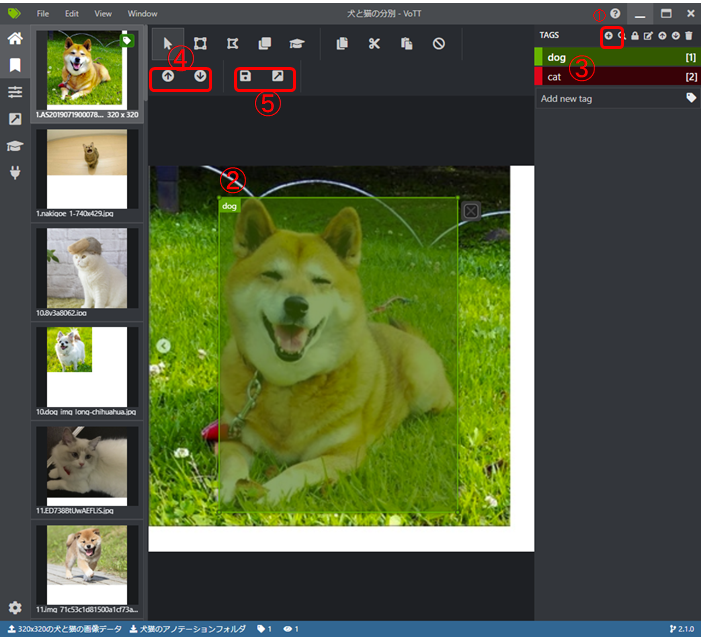
1、まず、Tagsを作ります。今回は犬と猫なので、dog, catの2種類を作りました。
2、次に、犬の部分をクリックで囲います。
3、犬を囲ったので、dogをクリック
4、「↓」で次の画像へ、「↑」は前に戻ります。
5、保存と出力です。すべてのアノテーションが終えたら、出力しましょう。
出力後、「save_annotations」フォルダにデータが保存されているので、

「ano_data」に圧縮!!!!

今回はここまでで終了です。お疲れ様でした!!!!!
最後に
次は、今回使ったデータをもとにYOLOv3で学習をさせ、テストしてみます。
それでは、また。