有名な国際会議の予稿集や学術雑誌が出るたびに「早く読みたいけど、多すぎ。時間無い」と思う方は、多いのではないでしょうか。
ということで、乱読用の論文要約スクリプトを作ってみました。当初は、最新バージョンのGPT-4を使用してスクリプトを作成しようと思っていました。しかし、GPT-4はAPI利用料の単価が高いことと、性能がそれほど良くないという検証結果があることから、GPT-4ではなく、GPT-3の1つである"gpt-3.5-turbo"モデルを使用してスクリプトを作成しました。
環境・モジュール
- macOS Ventura 13.4.1
- Python実行環境
- python = "3.11"
- pdfminer-six = "20221105" # PDFからテキストに変換するときに利用
- openai = "0.27.8" # OpenAIのAPIコールに利用
- numpy = "1.25.1"
- pyyaml = "6.0.1" # APIキーを読むために利用
- 実行日: 2023-07-20
事前準備・実行方法・例
-
スクリプト名: summarize_article.py
-
第1引数: PDF形式の論文
-
設定ファイル: secret.yaml(summarize_article.pyと同じディレクトリに置く)
openai_api_keyに登録する情報は、https://platform.openai.com/ から取得します。secret.yaml# Key name: named as "summarize_article.py" in OpenAI web console openai_api_key: sk-nxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxa -
「環境・モジュール」で示したPython実行環境のパッケージをインストールする。(pipでもpoetryでもなんでもOK)
- "sample_1_CISO.pdf"はPDF形式の論文ファイル
実行例% python summarize_article.py sample_1_CISO.pdf input file has 15096 words, so API requests repeat 9.0 times. 0 times request... (1792 words are included) - CISO(Chief Information Security Officer)は、企業のITセキュリティリスクを評価し、適切に管理する役割を担っている。 - CISOは、組織内のヒューマンセンタードセキュリティ(HCS)の基本概念にどのように反応するかを探るため、30人のCISOとのワークショップを実施した。 - 参加したCISOたちは、HCSに興味を持ちながらも、実際の人間の行動を考慮していないため、市場で利用可能なものを使用していることがわかった。 - CISOたちは、意識啓発やフィッシングシミュレーションを定期的に行っているが、実際の人間の行動やセキュリティが従業員に与える摩擦を考慮していない。 - 結論として、HCSの研究と実践が合致していないことが明らかになった。 - CISOの役割や組織内のHCSに関する研究についても紹介されている。 (要約は続く) 1 times request... (1792 words are included) - CISOのコミュニティを対象にしたワークショップシリーズが開催された。 - CISOのフィードバックに基づいてワークショップのアジェンダが形成された。
スクリプト
- gpt-3.5-turboの上限トークン数である4,097以下に入出力が収まるように、論文を分割しています。
- また、分割による文脈ロストを避けるために、プロンプトの文中に論文の分割数を記載して、さらに、前後の文脈を考慮することを記載しています。
- プロンプト作成に当たって、以下の記事を参考にさせていただきました。ありがとうございました。
https://qiita.com/sakasegawa/items/1d906d66330a09b6939f
import argparse
import re
import numpy as np
import yaml
import openai
from pdfminer.high_level import extract_text
# APIキーをsecret.yamlから読み取ってセットする
with open('secret.yaml', 'r') as f :
secret_config = yaml.safe_load(f)
openai.api_key = secret_config['openai_api_key']
# APIへ送信するワード数の上限を、経験的に設定する
WC_MAX = int(4096 * 7 / 16)
# PDFファイルからテキスト情報を抽出する
def extract_text_from_pdf(file_path) :
text = extract_text(file_path)
return text
# テキスト情報から単語途中で現れるハイフンと改行を削除する
def clean_extracted_text(text) :
text = text.replace('-\n', '')
text = re.sub(r'\s+', ' ', text)
return text
# APIへ送信するメッセージ(プロンプト)を作成する
def create_prompt(text, total_num_req) :
return f"""英語の研究論文の一部を日本語で要約するタスクを行います。
研究論文は全部で{total_num_req + 1}個に分割しています。
以下のルールに従ってください。
・リスト形式で出力する (先頭は - を使う)
・簡潔に表現する
・不明な単語や人名と思われるものは英語のまま表示する
それでは開始します。
英語の論文の一部:
{text}
日本語で要約した文章:"""
# テキストをWC_MAXごとに分割する
def split_text(text, wc_max) :
'''
:param text: english oneline sentence
:param wc_max: word count max (if token max is 4097, it should be 2048)
:return: chunk[]
'''
words = text.split() # Split the text into words
chunks = [' '.join(words[i :i + wc_max]) for i in range(0, len(words), wc_max)]
return chunks
# main()メソッド
def main() :
# 第一引数はPDFファイル(英語論文を想定)
parser = argparse.ArgumentParser(description='Extract text from a PDF file.')
parser.add_argument('file_path', help='The path to the PDF file.')
args = parser.parse_args()
# PDFファイルからテキスト情報を抽出して整形する
extracted_text = extract_text_from_pdf(args.file_path)
clean_text = clean_extracted_text(extracted_text)
# テキスト情報の概要を表示する。APIコール回数を表示する。
print(f"input file has {len(clean_text.split())} words, "
f"so API requests repeat {np.ceil(len(clean_text.split()) / WC_MAX)} times.")
# 分割処理(4,097トークン以下に抑えるための処理)
splited_clean_text = split_text(clean_text, WC_MAX)
# 分割したテキストごとに要約をリクエストする
for i in range(len(splited_clean_text)) :
print(f"{i} times request... ({len(splited_clean_text[i].split())} words are included)")
# Setup prompt messages
messages = [
{"role" : "system",
"content" : "あなたは、金融機関に所属するサイバーセキュリティ研究者です。あなたは、前後に問い合わせした内容を考慮して思慮深い回答をします。"},
{"role" : "user", "content" : create_prompt(splited_clean_text[i], len(splited_clean_text))}
]
# APIにリクエストを送信する
# token数超過などの例外を返す可能性があるため、try/exceptを設定しておく。
try:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # GPTのモデルを指定。安価なgpt-3.5-turbo
messages=messages,
max_tokens=800, # 生成するトークンの最大数(入力と合算して4097以内に収める必要あり)
n=1, # 生成するレスポンスの数
stop=None, # 停止トークンの設定
temperature=0.7, # 生成時のランダム性の制御
top_p=1, # トークン選択時の確率閾値
)
# 生成するレスポンス数は1という前提
print(response["choices"][0]["message"]["content"])
except openai.error.InvalidRequestError as e:
print("OpenAI API error occurred: " + str(e))
if __name__ == "__main__" :
main()
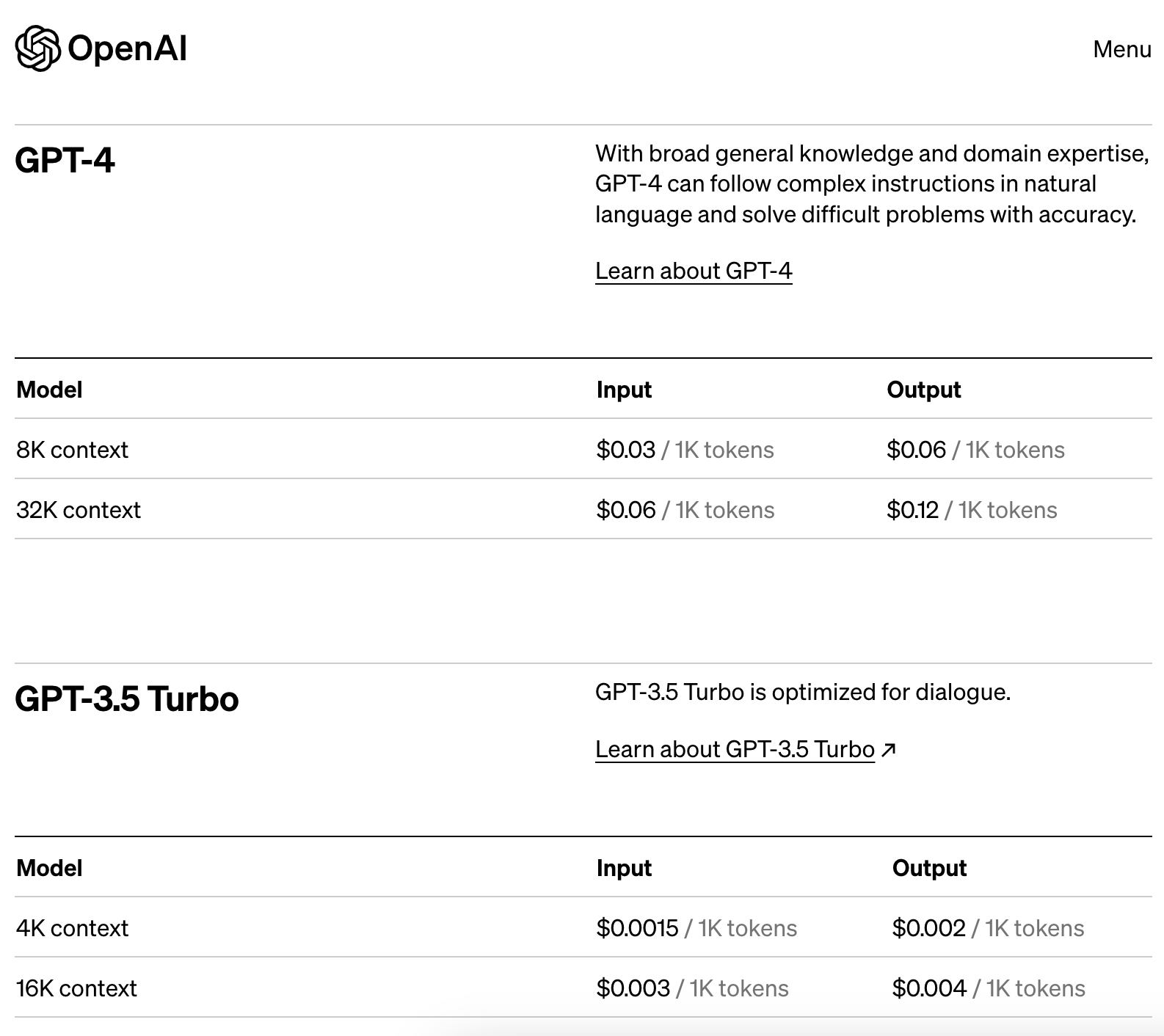
GPT-4であれば、32,000トークンまで一度に処理ができるので、このような分割を必要とする場面が少なくなります。(ただし、API利用にかかるコストは上がります。)
まとめに変えて
乱暴なやり方ではありますが、コスト比較をしておきます。
32,000tokenが必要な要約作業(約30ページ程度の論文の要約作業)を考えると、GPT-4は入力の都度1.92ドル。5,000token分の要約を行ったとして、出力に0.6ドル。合計、日本円でおよそ300円かかる計算です。
一方、GPT-3.5の場合、入力で0.048ドル。出力で0.01ドル。合計、日本円でおよそ7円かかる計算です。
コストだけで比較すると、乱読目的の論文要約では十分使えます。