じゃんけんアドベントカレンダー の 4 日目です。
前回までで自動テストと CI を整えたので、今回からついにコードをリファクタリングしていきます。
まずは今回・次回くらいでいわゆる「MVC」に近いかたちを目指していきます。
「MVC」に近づけるにあたり、この記事では
- Enum の導入
- DTO の導入
の 2 つを実施します。
※ Enum の導入は MVC とは直接関係ないですが、Enum が文法にある言語ではぜひとも使うべきものなので、今回導入してしまいます。
Enum の導入
Enum を使っていない場合、じゃんけんの「グーが 0、チョキが 1、パーが 2」といった定義は int などの定数になっていると思います。
private static final int STONE_NUM = 0;
private static final int PAPER_NUM = 1;
private static final int SCISSORS_NUM = 2;
private static final String STONE_STR = "STONE";
private static final String PAPER_STR = "PAPER";
private static final String SCISSORS_STR = "SCISSORS";
こういった定数を Enum を使って定義することで、コードがより安全になります。
例えば以下のようになります。1
@AllArgsConstructor
@Getter
public enum Hand {
STONE(0, "STONE"),
PAPER(1, "PAPER"),
SCISSORS(2, "SCISSORS");
private int value;
private String name;
}
このプラクティスは Java などの Enum のある言語であれば確実に使うものです。
こういった値の定義にはぜひ Enum を使いましょう。
Enum に続いて、次は DTO を導入していきます。
DTO の導入
アプリケーション開発では、データベーススキーマと一致した「モデル」クラスを作ることが少なくありません。
データベーススキーマと一致した「モデル」クラスの作成から始めることには賛否ありますが、今回はまずその方針で始めて、次回以降で徐々にリファクタリングしていってみようと思います。
実装
実装中のアプリケーションのデータモデルは、Day 1 の記事 で紹介した通り以下のようになっています。
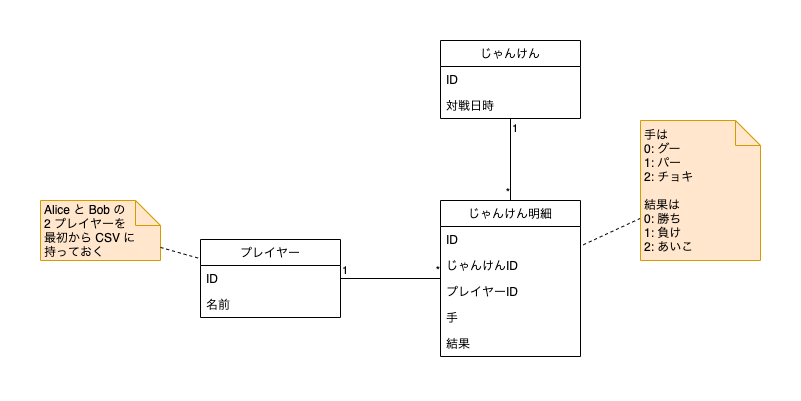
このデータモデルと一致する「入れ物クラス」を Java で実装すると、例えば以下のようになります。
@AllArgsConstructor
@Getter
@EqualsAndHashCode
@ToString
public class Player {
private long id;
private String name;
}
こういった、データを入れて持ち運ぶためだけのクラスを「DTO (Data Transfer Object)」と呼んだりします。
それでは、このようにして作った Player クラス、Janken クラス、JankenDetail クラスを使うようにリファクタリングした際の効果を 2 つ解説します。
効果 1. CSV のカラムの並び順を 1 度だけ意識すればよくなった
以前のコードでは、以下のように players.csv のどのカラムが id でどのカラムが name なのかを何度も意識していました。
private static String findPlayerNameById(int playerId) throws IOException {
try (Stream<String> stream = Files.lines(Paths.get(PLAYERS_CSV), StandardCharsets.UTF_8)) {
return stream
// ID で検索
.filter(line -> {
String[] values = line.split(CSV_DELIMITER);
int id = Integer.parseInt(values[0]);
return id == playerId;
})
// 名前のみに変換
.map(line -> {
String[] values = line.split(CSV_DELIMITER);
return values[1];
})
.findFirst()
.orElseThrow(() -> {
throw new IllegalArgumentException("Player not exist. playerId = " + playerId);
});
}
}
この 1 メソッドだけであれば読んで理解できなくないですが、id ではなく name で検索するといった類似メソッドが増えていくと、CSV のどのカラムが何のデータなのかを全箇所で意識するのは大変です。
特に、カラムの定義に変更があった際は、どこを修正すればいいのか分からなくなりやすいでしょう。
Player クラスを使うと、上記のメソッドが以下のように変化します。
private static String findPlayerNameById(long playerId) throws IOException {
try (val stream = Files.lines(Paths.get(PLAYERS_CSV), StandardCharsets.UTF_8)) {
return stream
.map(line -> {
val values = line.split(CSV_DELIMITER);
val id = Long.parseLong(values[0]);
val name = values[1];
return new Player(id, name);
})
// ID で検索
.filter(p -> p.getId() == playerId)
// 名前のみに変換
.map(Player::getName)
.findFirst()
.orElseThrow(() -> {
throw new IllegalArgumentException("Player not exist. playerId = " + playerId);
});
}
}
プレイヤーの CSV ファイルの中で、どのカラムが id でどのカラムが name なのか対応させる箇所が最初の map 処理だけになり、以後の filter や map では CSV ファイルの形式を意識しなくてよくなりました。
今後似たメソッドが増えた際も、CSV の 1 行を Player に変換する処理だけメソッドに抽出することで、CSV の行と Player クラスの対応を 1 箇所で管理することができます。
効果 2. メソッドの引数が減った
じゃんけん明細の 1 行を保存するメソッドは、以前は以下のようになっていました。
private static void writeJankenDetail(PrintWriter pw,
long jankenDetailId,
long jankenId,
int playerId,
int playerHand,
int playerResult) {
:
}
引数が多く、どれをどの順番で渡すのかも分かりにくいですし、呼び出すのが大変です。
JankenDetail クラスを使うと、上記のメソッドの引数が以下のようにシンプルになります。
private static void writeJankenDetail(PrintWriter pw,
JankenDetail jankenDetail) {
:
}
今回は結局呼び出し側で
val jankenDetail1 = new JankenDetail(jankenDetail1Id, jankenId, PLAYER_1_ID, player1Hand, player1Result);
のようにたくさん引数を与える処理を書くためありがたみが薄いですが、例えば JankenDetail を引数として受け取るメソッドが増えた場合に利便性を感じるようになります。
Setter を作らない理由
ここまでで、DTO を導入し、そのメリットについて書いてきました。
ところで、私が例として挙げた DTO のコードを見て、なぜ Setter がないのか疑問に感じる方もいると思います。
@AllArgsConstructor
@Getter
@EqualsAndHashCode
@ToString
public class Player {
private long id;
private String name;
}
ということで、最後になぜ Setter を設けないのかを解説していきます。
理由は 2 つあるので順に説明していきます。
理由 1. イミュータブルにしたい
1 つ目の理由は、オブジェクトをイミュータブル (不変) にすることで、バグの発生確率を下げることができるからです。
Setter のようにフィールドを書き換えるメソッドを持つオブジェクトを使うと、コードのどこかでそのメソッドが呼び出され、オブジェクトの保持する値が書き換えられてしまう可能性があります。
フィールドの書き換えに起因するバグは、コードを深く読んでいかないと見つけられず、解決するのになかなか骨が折れます。
Setter などのオブジェクトのフィールドを変更するメソッドを持たない「イミュータブル (不変)」な設計にすることによって、このような問題の発生を防ぐことができます。
理由 2. フィールド追加時の変更箇所の検知
2 つ目の理由は、Setter を使っているとクラスにフィールドを追加した際に修正すべき箇所が分からなくなりやすいことです。
(オブジェクトをイミュータブルにすることとも関連しています)
例えば、Player クラスに id と name に加えて birthday というフィールドを追加するとします。
このとき、Player クラスを修正した後、他にはどこを直せばいいでしょうか ?
Setter を使っている場合、Player インスタンスを生成している箇所は
Player player = new Player();
player.setId(1);
player.setName("Alice");
のようになっている可能性があり、この場合フィールドを追加してもコンパイルエラーは発生しないため、修正すべき箇所として検知することはできません。
一方、Setter を作らず、コンストラクタでインスタンス構築時にデータを与えるようにしておけば、
Player player = new Player(1, "Alice");
のようにインスタンスを生成している箇所がコンパイルエラーになり、修正箇所として検知できます。
このようにオブジェクトが生成された時点で整合性を持つように設計することで、コードのメンテナンス性を向上させることができます。
どうしても Setter を使う状況
Setter を使わない理由を説明してきましたが、仕方なく使う場面もあります。
よくある例としては、使用している OR マッパが Setter を必要としている場合があります。
また、Setter 以外のメソッドについても、ミュータブル (可変) にした方が可読性が高かったりモデルとして適切だったりする場合は、無理にイミュータブル (不変) にせずミュータブルにする場合もあります。
とはいえ、基本はイミュータブル (不変) がオススメです。
慣れないとどれもこれもミュータブル (可変) にしたくなってしまうのですが、まずイミュータブル にしようとしてみて、それで難しければミュータブルにするような考え方でもいいかもしれません。
現時点のコード
これで Enum と DTO の導入が完了しました。
現時点のコードの構成を図示すると、以下のようになっています。
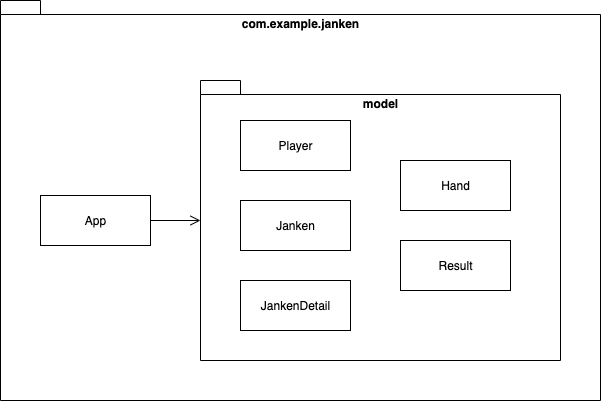
コードは GitHub の この時点のコミット を参照ください。
次回のテーマ
今回は「MVC」を目指す第一歩として、入れ物クラス (DTO) の抽出と、ついでに Enum の導入を実施しました。
次回は View を分離して、より MVC に近づけてみようと思います。
それでは、今回の記事はここまでにします。最後まで読んでくださりありがとうございました。
じゃんけんアドベントカレンダー に興味を持ってくださった方は、是非購読お願いします。
次回の記事
【Day 5】View を抽出して MVC に近づける【じゃんけんアドカレ】
-
コンストラクタや Getter などボイラテンプレートを書くのは面倒なので、Lombok で生成しています ↩