じゃんけんアドベントカレンダー の 13 日目です。
前回トランザクションスクリプトからドメインモデルに移行する中で、いくつかの課題点が見つかりました。
今回はその中でも
- Janken と JankenDetail の整合性がアプリケーション層に依存していること
- モデルの他のクラスを参照で持つのか ID だけ持つのか統一されていないこと
の 2 つについて検討しようと思います。
Janken と JankenDetail の整合性がアプリケーション層に依存していること
まず、Janken と JankenDetail の整合性がアプリケーション層に依存していることについて、もう一度振り返ってみようと思います。
JankenApplicationService で Janken と JankenDetail を保存する箇所は以下のようになっています。
val jankenWithId = jankenDao.insert(tx, janken);
jankenDetailDao.insertAll(tx, jankenWithId.details());
また、Janken と JankenDetail の読み込みのコードは、例えば以下のようになると想像されます。
val tmpJanken = jankenDao.findById(jankenId).get()
val jankenDetails = jankenDetailDao.findByJankenIdOrderById(tx, jankenId);
val janken = new Janken(tmpJanken.getId(), tmpJanken.getPlayedAt(), jankenDetails.get(0), jankenDetails.get(1);
これらのコードでは、Janken と JankenDetail を同時に保存すること・同時に取り出すことがアプリケーション層に依存しています。
もしもアプリケーション層で Janken と JankenDetail が同時に保存・取り出しされないコードが書かれてしまうと、保存されたデータが整合性のない状態になったり、取り出したオブジェクトの一部フィールドが NULL という整合性のない状態になったりします。
Janken と JankenDetail が同時に保存・取り出しされるべきものならば、そのことはモデルとして表現されるべきで、アプリケーション層の実装に委ねるべきではありません。
根本原因
このように Janken と JankenDetail の整合性がアプリケーション層の実装次第になってしまう原因は、Janken と JankenDetail それぞれの DAO をアプリケーション層で呼び出して読み書きしていることです。
これは、データモデルを中心に考え、テーブルと 1 対 1 に対応するようにデータアクセスを実装していることに起因します。
ところで、アプリケーション層は DAO のインタフェースのみに依存しているため、保存先が変わっても DAO だけ修正すればいいように見えますが、実はそれも怪しいです。
例えば、保存先がドキュメント DB であれば、1 つのドキュメントに Janken も JankenDetail も保存する場合もあり、その際は JankenDao と JankenDetailDao の両方の保存メソッドを呼び出すことはしないと思います。
データ中心からドメインモデル中心へ
このように、データ設計を中心としたアプローチでは、
- ドメインモデルの整合性の確保がアプリケーション層の実装次第になる
- 保存先が変更になった際にアプリケーション層も修正することになる
といった問題が発生します。
ドメインモデル上で整合性をしっかり表現し、さらに保存先に依存せずにアプリケーション層を記述するためには、データ設計中心 (DOA 的) ではなく、ドメインモデル中心 (OOA 的) に考える必要があります。1
DAO から Repository へ
そこで、データアクセスの実装方式として、テーブルと 1 対 1 に対応する DAO (= テーブルデータゲートウェイ) という実装パターンをやめ、ドメインモデルを中心にデータアクセスを実現する Repository パターンに変更します。
DAO と Repository ではコード上の違いはほとんどないこともありますが、Martin Fowler's Bliki (ja) の PofEAA の解説によれば、
DAO (= テーブルデータゲートウェイ) は、2
データベース テーブルへの Gateway (466)として振舞うオブジェクト。インスタンスはテーブル内のすべての行を操作する。
リポジトリ は、
ドメインオブジェクトにアクセスするためのコレクション ライクなインターフェースを使って、ドメイン—データ マッピングレイヤ間の仲介を行う。
とされています。
つまり、DAO はデータベースのテーブルを中心に考えたデータアクセスパターンであり、Repository はドメインモデルを中心に考えたデータアクセスパターンである、という違いが大きいです。
Repository と「集約」
Repository はドメインモデルを中心に考えたデータアクセスのパターンだと書きました。
それは、ドメインモデルとしてデータの読み書きを同時にしたい単位で Repository を作成するべきという意味です。
今回で言えば、Janken と JankenDetail は同時に読み書きします。
このように、ドメインモデルの中で、同時に読み書きし、まとめて取り扱うような集まりを「集約」と言います。
クラスごとに Repository を作っている例を見かけることが多いですが、Repository は「集約」ごとに 1 つだけ作成することで本領を発揮します。
Repository 実装のコツは、以下の記事が非常に参考になります。
Repository の実装
さて、前置きが長くなりましたが、それでは Repository を実装しようと思います。
Janken と JankenDetail は 1 つの集約の中のクラスなので、JankenRepository だけ作成し、JankenDetailRepository は作りません。
JankenRepository インタフェースは以下のようになりました。
public interface JankenRepository {
List<Janken> findAllOrderById(Transaction tx);
Optional<Janken> findById(Transaction tx, long id);
long count(Transaction tx);
Janken save(Transaction tx, Janken janken);
}
実装クラスである JankenMySQLRepository は以下のようになりました。
public class JankenMySQLRepository implements JankenRepository {
private JankenDao jankenDao = ServiceLocator.resolve(JankenDao.class);
private JankenDetailDao jankenDetailDao = ServiceLocator.resolve(JankenDetailDao.class);
@Override
public List<Janken> findAllOrderById(Transaction tx) {
val jankenWithoutDetails = jankenDao.findAllOrderById(tx);
val jankenDetails = jankenDetailDao.findAllOrderById(tx);
return jankenWithoutDetails.stream()
.map(j -> {
val jankenDetailsFilteredById = jankenDetails.stream()
.filter(jd -> jd.getJankenId().equals(j.getId()))
.collect(Collectors.toList());
return new Janken(
j.getId(),
j.getPlayedAt(),
jankenDetailsFilteredById.get(0),
jankenDetailsFilteredById.get(1));
})
.collect(Collectors.toList());
}
:
@Override
public Janken save(Transaction tx, Janken janken) {
val jankenWithId = jankenDao.insert(tx, janken);
val jankenDetailsWithId = jankenDetailDao.insertAll(tx, jankenWithId.details());
return new Janken(
jankenWithId.getId(),
janken.getPlayedAt(),
jankenDetailsWithId.get(0),
jankenDetailsWithId.get(1));
}
}
JankenMySQLRepository の内部では、先日作成した DAO を使うようにしています。
find の処理で jankens テーブルと janken_details テーブルにそれぞれアクセスしていることが気になる方がいらっしゃるかもしれません。
public class JankenMySQLRepository implements JankenRepository {
:
@Override
public List<Janken> findAllOrderById(Transaction tx) {
val jankenWithoutDetails = jankenDao.findAllOrderById(tx);
val jankenDetails = jankenDetailDao.findAllOrderById(tx);
:
このようなアクセス方法は N + 1 問題が生じるのではないかと誤解される場合がありますが、N + 1 問題はループでデータベースアクセスすることが原因なので、テーブルごとに 1 回ずつアクセスことでは発生しません。
実際には JOIN を使って 1 度のデータベースアクセスで全てのデータを取得することも多いと思いますが、今回は実装を簡略化するためこのようにさせていただきました。
後日 OR マッパを導入予定なので、その際は JOIN して 1 度のデータアクセスで必要なデータを取得するようにしようと思います。
ディレクトリ構成の整理
「集約」の考え方と「Repository パターン」を導入するにあたり、ディレクトリ構成も整理しました。
まず、domain.model 以下を集約ごとにパッケージ分けしました。
Repository は集約単位で作成するものなので、それが明示されるように domain.model 以下の各集約のパッケージに配置しています。
:
├── domain
│ ├── model
│ │ ├── janken
│ │ │ ├── Hand.java
│ │ │ ├── Janken.java
│ │ │ ├── JankenDetail.java
│ │ │ ├── JankenRepository.java
│ │ │ └── Result.java
│ │ └── player
│ │ ├── Player.java
│ │ └── PlayerRepository.java
: :
dao はもともと domain 以下に配置していましたが、MySQLRepository の内部実装として使うだけになったので、infrastructure に移動しました。
:
├── infrastructure
: :
│ ├── dao
│ │ ├── JankenDao.java
│ │ ├── JankenDetailDao.java
│ │ └── PlayerDao.java
: :
│ ├── mysqldao
│ │ ├── JankenDetailMySQLDao.java
│ │ ├── JankenMySQLDao.java
│ │ └── PlayerMySQLDao.java
│ └── mysqlrepository
│ ├── JankenMySQLRepository.java
│ └── PlayerMySQLRepository.java
:
これで「集約」と「Repository」の導入が完了しました。
最後に、残ったもう 1 つの検討事項である「モデルの他のクラスを参照で持つのか ID だけ持つのか統一されていないこと」について考えようと思います。
モデルの他のクラスを参照で持つのか ID だけ持つのか統一されていないこと
まず、どんな話だったのかを振り返ってみます。
現在、Janken クラスのコードは以下のようになっています。
@AllArgsConstructor
@Getter
@EqualsAndHashCode
@ToString
public class Janken {
:
private Long id;
private LocalDateTime playedAt;
private JankenDetail detail1;
private JankenDetail detail2;
:
JankenDetail クラスのコードは以下のようになっています。
@AllArgsConstructor
@Getter
@EqualsAndHashCode
@ToString
public class JankenDetail {
private Long id;
private Long jankenId;
private Long playerId;
private Hand hand;
private Result result;
:
気になるのは
- JankenDetail の jankenId
- JankenDetail の playerId
の 2 つです。
まずは後者の playerId から考えてみます。
JankenDetail は player を持つべきか、playerId を持つべきか
Janken クラスは JankenDetail を参照として持っていますが、JankenDetail から Player に対しては playerId だけを保持しています。
コードの統一感を考えると Player を参照として持った方がいいのではないか、というのが論点です。
結論としては、現状のまま、集約の内部は参照で保持し、集約を超える場合は ID 等だけ保持するべきです。
もしも別集約のオブジェクトを参照で保持することを許容すると、Repository からオブジェクトを取得するときのサイズが非常に大きくなったり、一部のフィールドを NULL という危険な状態で扱うことになったりします。
そのような状態を避けるため、集約を超えた関連は ID 等だけの保持で実現します。
※ 厳密には、DDD で言うところの Entity は集約をまたがって参照しませんが、Value Object であれば参照して構いません
なお、OR マッパによっては Lazy Fetch のような機能で遅延読み込みする方法もあり、それを上手に使えば参照を保持しつつ大きなデータをロードしないことも可能かもしれません。
ですが、そういった OR マッパは、N + 1 問題が発生しやすかったり挙動が分かりにくかったりするため、あまり使用をオススメしません。3
JankenDetail は jankenId を持つべきか、持たないべきか
次に、JankenDetail の jankenId についてです。
上記の Janken クラスと JankenDetail クラスを見ていると、Janken から JankenDetail を参照しつつ、逆方向に JankenDetail が jankenId を持っており、違和感を感じるかもしれません。
私の場合、Janken が JankenDetail を保持し、JankenDetail が Janken を保持することは、双方向依存なので避けます。
ですが、Janken が JankenDetail を保持し、JankenDetail が jankenId を保持することは、双方向依存ではないので許容します。
一方、そもそもドメインモデル的には JankenDetail が jankenId を持っていることが必要な場面はないと思います。
集約ルートである Janken が id を保持しているため、必要があればその値を使えばいいからです。
JankenDetail が jankenId を保持しているのは RDB のデータ設計上の都合なので、ドメインモデルとしては排除する、という考え方もあります。
(例えば、保存先が RDB ではなくドキュメント DB であれば、ここに jankenId があるのは不自然ではないでしょうか)
現時点のコード
文字ベースの解説が多くなってしまいましたが、今回の内容は以上になります。
現時点の主要なクラスの構成を図示すると、以下のようになっています。
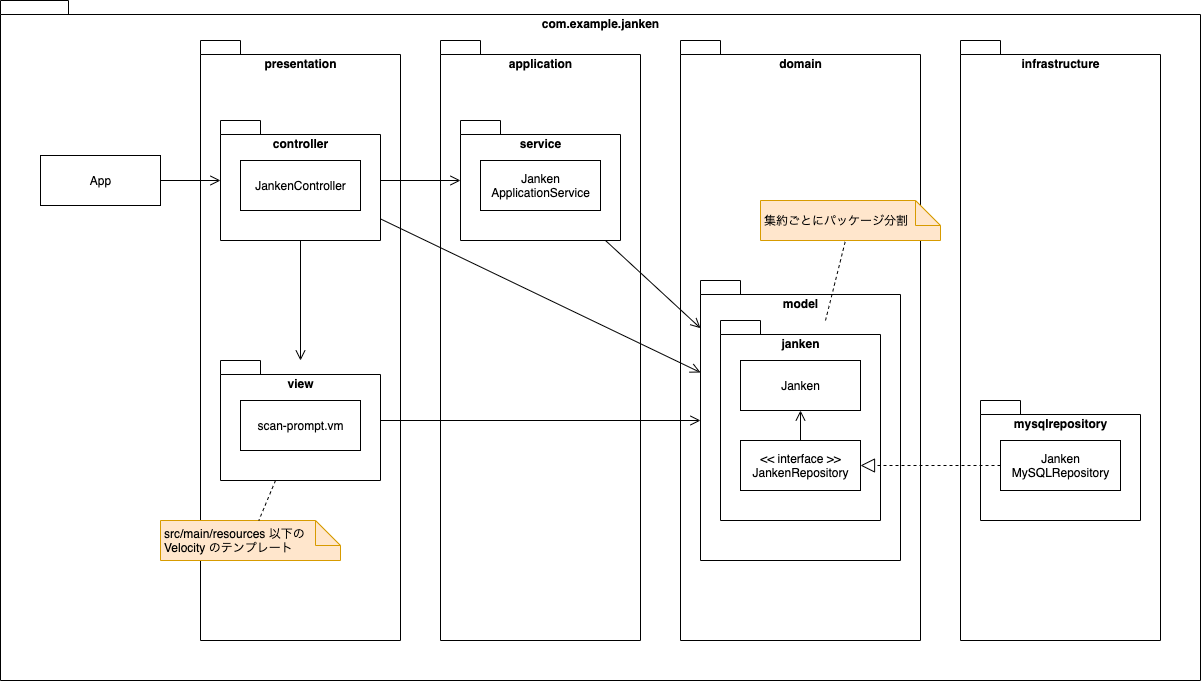
ディレクトリ構成も掲載しておきます。
$ tree app/src/main/java/
app/src/main/java/
└── com
└── example
└── janken
├── App.java
├── application
│ └── service
│ ├── JankenApplicationService.java
│ └── PlayerApplicationService.java
├── domain
│ ├── model
│ │ ├── janken
│ │ │ ├── Hand.java
│ │ │ ├── Janken.java
│ │ │ ├── JankenDetail.java
│ │ │ ├── JankenRepository.java
│ │ │ └── Result.java
│ │ └── player
│ │ ├── Player.java
│ │ └── PlayerRepository.java
│ └── transaction
│ ├── Transaction.java
│ └── TransactionManager.java
├── infrastructure
│ ├── csvdao
│ │ ├── CsvDaoUtils.java
│ │ ├── JankenCsvDao.java
│ │ ├── JankenDetailCsvDao.java
│ │ └── PlayerCsvDao.java
│ ├── dao
│ │ ├── JankenDao.java
│ │ ├── JankenDetailDao.java
│ │ └── PlayerDao.java
│ ├── jdbctransaction
│ │ ├── InsertMapper.java
│ │ ├── JDBCTransaction.java
│ │ ├── JDBCTransactionManager.java
│ │ ├── RowMapper.java
│ │ ├── SimpleJDBCWrapper.java
│ │ └── SingleRowMapper.java
│ ├── mysqldao
│ │ ├── JankenDetailMySQLDao.java
│ │ ├── JankenMySQLDao.java
│ │ └── PlayerMySQLDao.java
│ └── mysqlrepository
│ ├── JankenMySQLRepository.java
│ └── PlayerMySQLRepository.java
├── presentation
│ ├── controller
│ │ └── JankenController.java
│ └── view
│ └── View.java
└── registry
└── ServiceLocator.java
20 directories, 33 files
コードは GitHub の この時点のコミット を参照ください。
次回のテーマ
今回 Repository を導入したことで、モデルの整合性についての問題をある程度解決できました。
しかし、Janken と JankenDetail の生成時に ID が NULL になるという、ID の採番に起因する問題がまだ残っています。
次回はこの ID の採番問題を解決しようと思います。
それでは、今回の記事はここまでにします。最後まで読んでくださりありがとうございました。
じゃんけんアドベントカレンダー に興味を持ってくださった方は、是非購読お願いします。
-
実際にはデータ設計も非常に重要なので、ドメインモデルの設計と行ったり来たりするのではないかと思います ↩
-
DAO とテーブルデータゲートウェイが同じであることは書籍『エンタープライズ アプリケーションアーキテクチャパターン』に書かれています ↩
-
具体的には JPA です ↩