私が所属する電通国際情報サービスAIトランスフォーメーションセンター(https://isid-ai.jp/ )の同僚が、以前Azure AI-OCRに関して以下の記事を書きました。(以降、前回記事と呼びます)
この時点からAzureのAI-OCRがさらに進化を遂げており、是非皆さんに紹介したく記事にしております。
本記事の目的
本記事は、前回記事で検証をおこなっている、「**Cognitive Service Read API v3.2」の改良版である「Private Preview版」**を使わせていただき、現状の日本語の認識精度がどうなのか?また、どのように変化したかについてまとめた記事となっています。
なお、両者の違いを明確にしておくと次のようになっています。
| 印刷文字の日本語対応 | 手書き文字の日本語対応 | |
|---|---|---|
| Read API v3.2 | ◯ | × |
| Private Preview版 | ◯ | ◯ |
つまり、前回記事との大きな違いは、今回は特に日本語手書きに焦点をあてた記事であるということになります。(印刷文字の認識精度についても全く見ていないわけではないです。)
Read API v3.2でも日本語には対応しているので、その時点で手書き文字の認識もある程度できていました。今回さらに手書きにも対応したということで、果たしてどのような感じなのか探っていきます。
また、**「Read API v3.2」と「Private Preview版」**を用いて、同じAzureサービス内での比較を行う内容となっている点も前回記事との違いです。
想定読者
以上を踏まえると、特に次のような方にはおすすめかと思います。
- 手書き文字を含むような日本語文書のOCRについて興味のある方
- 日本語のOCRが現状どのような精度なのか知りたい方。
- Azure-OCRの精度向上の質・スピード感を知りたい方。
(余談)
ところで、個人的には、3つ目のAzure-OCRの精度向上の質・スピード感を知りたいという視点は重要だと思っています。クラウドサービスを選ぶにあたり、「現在どのようなことができるか」はもちろん大事ですが、「**将来に向けた期待度が高いかどうか」**まで見れればもっと良いと思いませんか?
今回は、Azure-OCRという一つのサービスの中で精度がどう変化したかを検証する記事になっているので、ぜひ、そういった視点でも見ていただければと思います。
検証にあたって
実行環境・実行コードについて
本題の検証に移っていきますが、まずは実行環境・実行コードについて触れておきます。
ただし、今回用いているのは、あくまでPrivate-Preview版のため、private-preview版を使うための環境構築の方法やコード全体をお伝えすることはできません。とはいえ、検証の流れとしては前回記事と同様の流れで行っていますので、環境構築や実行コードについては、そちらをご参照頂ければと思います。
補足
今後、Public Preview版や一般提供版が提供されたときのために書いておくと、従来通りであれば、以下の部分のURLを適切に変更することで、新しいVerの機能が利用できると思います。(正確な情報は、更新されるであろう公式ドキュメントを参照してください。)
# vision-v3.2のread機能のURLを設定
text_recognition_url = (ENDPOINT + "vision/v3.2/read/analyze")
検証用データと検証内容
とは言っても、利用した元データ自体も前回記事と変わらず、IPAで公開されている情報システム・モデル取引・契約書のテンプレート「<重要事項説明書(第二版追補版付属)>」の一部を用いています。
ただし、今回は手書き文字に対する精度検証を行うため、下記の流れで検証用データを実施しています。
- 筆者が印刷した文書の項目を手書きで埋める
- スキャンしてPDF化
こうして、出来上がったOCR実行前のデータがこちらになります。
このデータに対し、「**Cognitive Service Read API v3.2」「Private Preview版」**のそれぞれでOCRを実施し、結果を比較しました。
検証結果
それでは、「**Cognitive Service Read API v3.2」と「Private Preview版」**でのOCR精度を比較していきます。
※ なお、ここからは簡単のためにRead API v3.2を旧ver、Private Preview版を新verと表記します。
※ 検証結果は違いがわかりやすい箇所のみをピックアップしています。文書全体に対するOCR結果のリンクも記事の最後に貼ってありますので、全体を見たい方はぜひご参照ください。
◯ 精度が向上していた点
1. 日本語手書き文字の認識精度がかなり向上している。
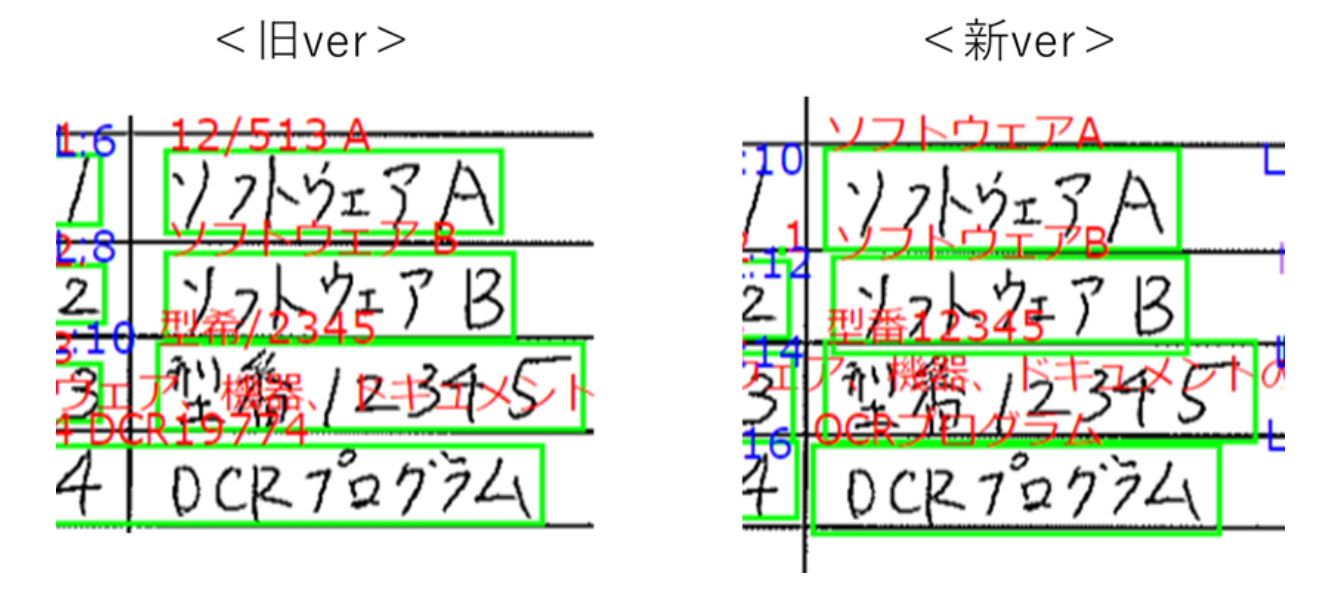
まず、前提として旧バージョンでも日本語手書き文字の認識精度が悪いかというとそういうわけでもなかったと思っています。実は、自分がAI-OCRを実際に試したのは、この旧verが初めてでした。そして感覚的な話にはなってしまいますが、初めて旧verを使ったときでも「思ったより凄い!」と思っていました。
とはいえ、日本語手書きでうまくいかないところは、結構目にはついていたので今回新verでどうなるだろうと、楽しみにしていました。結果としては、日本語手書き文字の認識精度がかなり向上していてとても驚いています。
例えば、上図では改善が顕著であった例を示していますが、旧verで
- 「ソフトウェアA」を「12/513A」としていた点
- 「型番12345」を「型希/2345」としていた点
- 「OCRプログラム」を「DCR19774」としていた点
全てが見事に新バージョンで直っています。
また、下図は「OCR精度検証のため、「単価」、「数量」、「納入日」といった項目の文字間隔を空けています。」という少し長めの文のOCR結果です。旧バージョンでは難しめの漢字である「納」や「隔」という字を誤認識していますが、新バージョンではすべて正しく読み取れていました。とてもいい感じですね。

2. 氏名のような固有名詞に強くなっている。
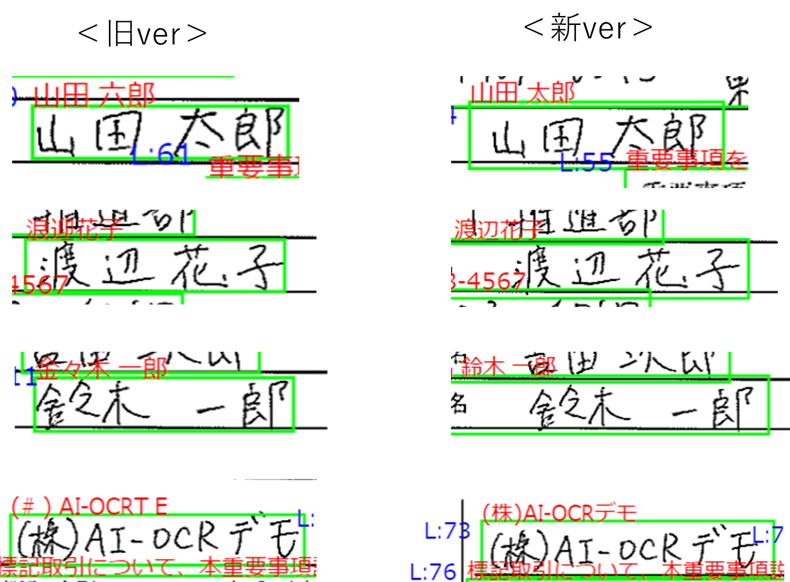
次に目についたのは、氏名のような固有名詞に強くなっているという点です。
旧verでは「山田太郎」、「渡辺花子」、「鈴木一郎」というような、頻出かつ漢字もそこまで難しくない名前でも誤認識しています。また、「(株)AI-OCRデモ」という会社名も、もちろん実在はしないものの簡単な文字ばかりですが誤認識しています。
これに対し、新バージョンでは上記のすべてが直っています。
3. 単語において、文字の間隔が離れていると別の文字と認識される問題が改善している
実はこの「**単語において、文字の間隔が離れていると別の文字と認識される」**という問題点は、前回記事でも触れられています。そしてそこでは「こちらは仕方ない部分もありますが・・・」と述べられていました。私も仕方ないよなというのは同感でした。この検証をするまでは。。。
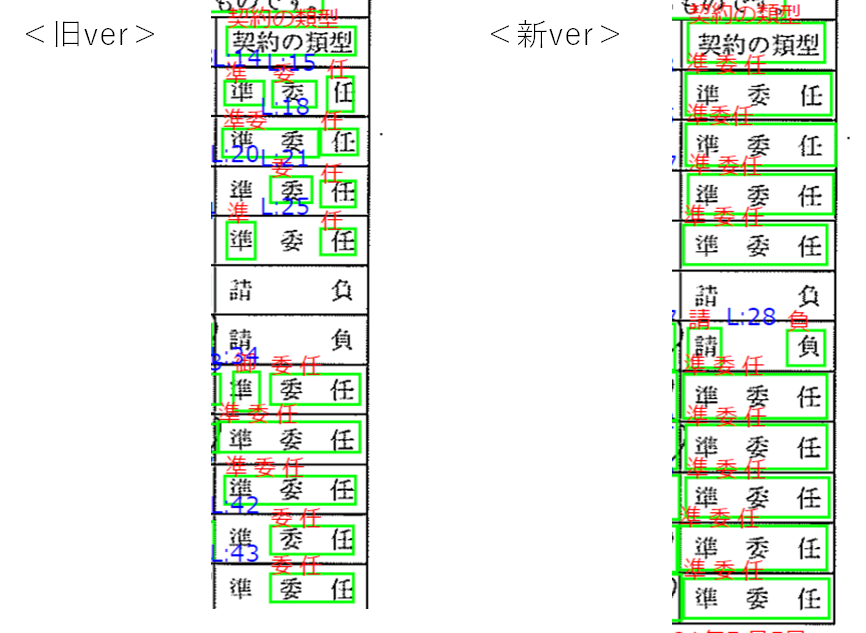
上図をみると、旧verでは「準委任」が「準」「委」「任」となったり「準委」「任」となったり、はたまた「準」「委任」となったりしていていますが、新バージョンでは9個の「準委任」のすべてが一塊で認識されています。残念ながら中の仕組み(アルゴリズム)まで知ることはできませんが、こうなってくるととても気になります。
こういった結果をみるとAI-OCRにおける「本当はこうだけど、これはしょうがないよね」といった点も今後Azure-OCRではどんどん解消されていくのでは?と期待が高まります。
とはいえ「請負」という単語が分割されている事からも分かる通り、間が広いと別の文字として認識されてしまうようです。詳細な検証はできていませんが、今回の結果を見た限り約1文字分の間隔までであれば、同一の単語として認識できるようです。
4. 「¥」が認識できるようになっている

上図のように「¥」が認識できるようになっています。まさに日本対応ができているというのが実感できる例ではないでしょうか。
OCRを活用したシステムでは、OCRでの間違いが、ルールベースの後処理で解決しやすい間違いなのか、そうではないのかという点が非常に重要です。
「¥」が認識できるというのは、細かいことのようで非常に重要なのです。「¥」があれば、その後ろに続く数字は金額であるということが後から分かりますよね。
--
以上4つが今回ピックアップした精度向上ポイントになります。
△今後の改善点
OCRという技術の性質上、常に100%の精度で、というのは難しいです。
スキャンの質であったり、手書き文字の綺麗さや癖などにはどうしても依存してしまいます。
今回の検証結果でも、すべて完璧に認識できているというわけではありません。
こうした性質上、OCRをシステムに組み込んで業務に実際に活用するためには、間違えたとしても、ルールベースの後処理で修正が効くかという点が非常に重要になってきます。
今回の新バージョンの検証結果で、会社名の「名」と「オーシーアール検証・・・」の部分は違う枠内にあるにもかかわらず、くっついてしまっている場合がありました。

この点は、後処理のしやすさに関わる部分のため、改善点として挙げておきます。
最後に
いかがでしたでしょうか?実際に検証を行う前は、さすがに手書き文字だと厳しいのかな、と個人的には思っていましたが、かなり精度良く読み取れていて驚きました。旧バージョンではうまくいっていない点も新バージョンで改善している点が多く、今後のAzure-OCRへの期待も高まります。
なお、今回はあまり定量的な評価はできていませんが、他サービスとの比較も含め、定量的な評価を行っている記事がありますので合わせてご確認いただくと良いと思います。
また、今回の検証結果及び考察は、あくまでも今回の検証データに限ったものとなりますので、その点についてはご了承ください。他の記事を参照したり、皆様自身で試してみると面白いと思います。
最後に文書全体に対するOCR結果のリンクを貼っておきますので、全体を確認したい方はぜひご参照ください
文書全体OCR結果リンク
・ 旧バージョンのOCR結果
・ 新バージョンのOCR結果