はじめに
手元にあるPCでLLMを動かす方法としては、Ollamaなどが有名ですが、他にも様々なツールがあります。そのうちの一つであるXinferenceを紹介します。
Xinferenceとは
Xinferenceは様々なAIモデルの操作と統合を合理化するオープンソースプラットフォームです。LLMだけでなく、画像生成、音声認識、embedding、rerankのモデルにも対応しています。また、モデルのエンジンとして、vllm、sglang、llama.cpp、transformersに対応しているため、量子化モデル(gguf、awqなど)も動かす事ができます。
- 良い点:
- embeddingに加えて、rerankモデルも扱える
- 複数のモデルエンジンに対応しているので、扱えるモデルが豊富
- イマイチな点:
- 対応しているアプリが少ない
- OpenAI互換APIは備えているものの、それだとrerankが使えない
使い方
セットアップ
Dockerを使う方法が簡単です。
docker run -d \
-e XINFERENCE_HOME=/data \
-v </on/your/host>:/data \
-p 9997:9997 \
--gpus all \
--name xinference \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0
公式ドキュメントにある様に、huggingfaceのcacheを他のアプリなどと共有して容量を節約したい場合は下記が良いです。
docker run -d \
-v </your/home/path>/.xinference:/root/.xinference \
-v </your/home/path>/.cache/huggingface:/root/.cache/huggingface \
-v </your/home/path>/.cache/modelscope:/root/.cache/modelscope \
-p 9997:9997 \
--gpus all \
--name xinference \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0
モデル起動
http://localhost:9997/ にアクセスし、Launch Model から希望のモデルを選択します。
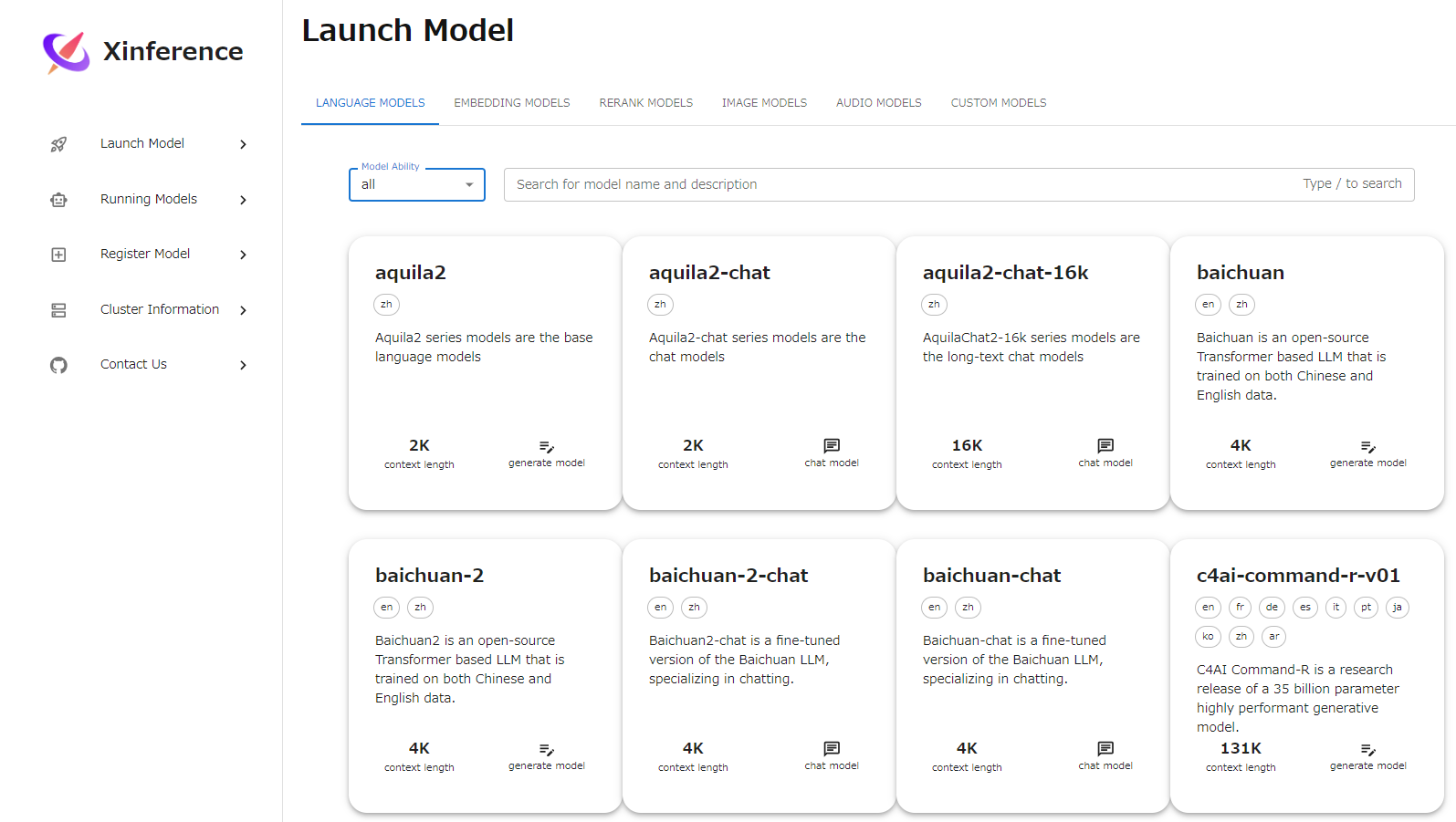
モデルファイルの形式、モデルサイズ、量子化パラメータなどを選択します。
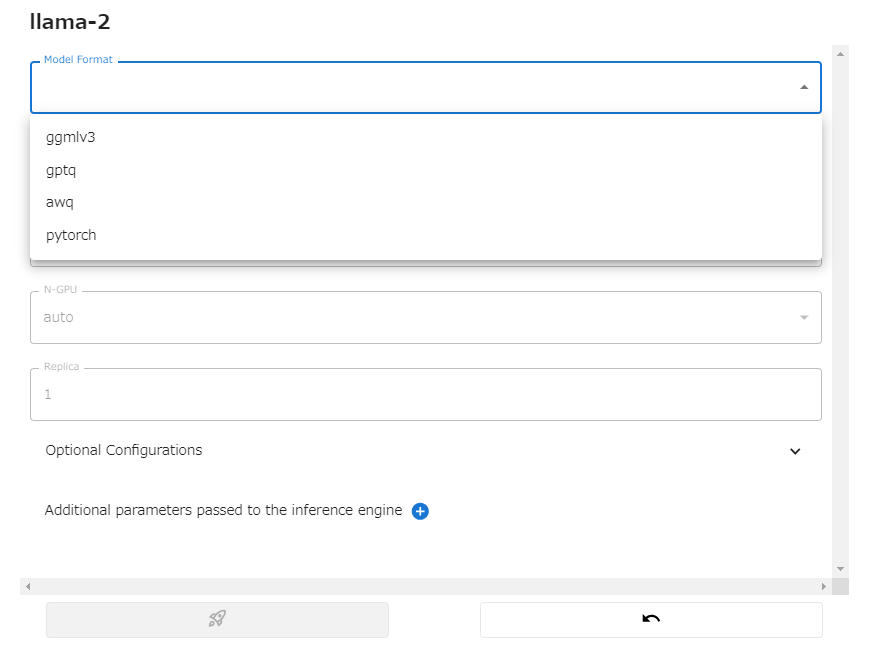
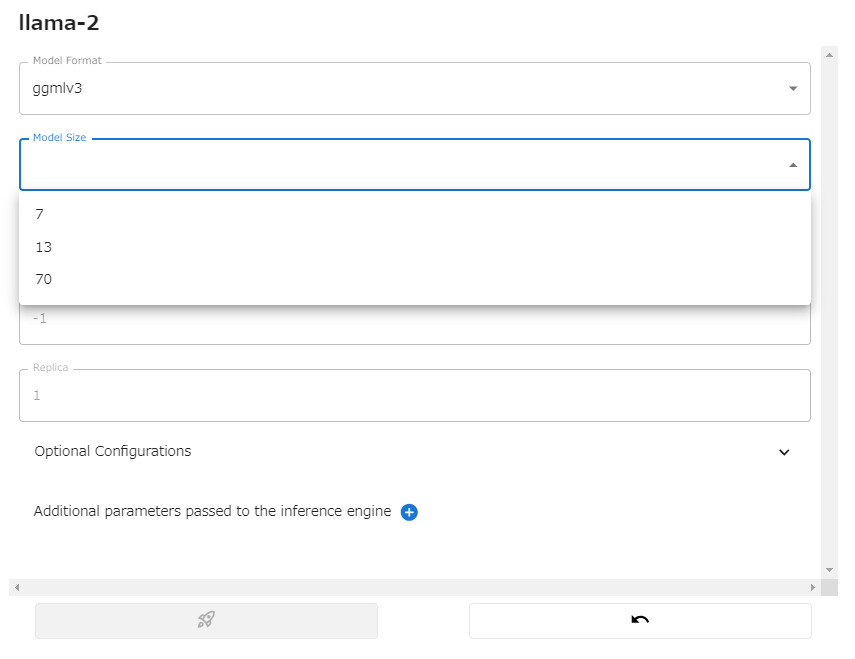
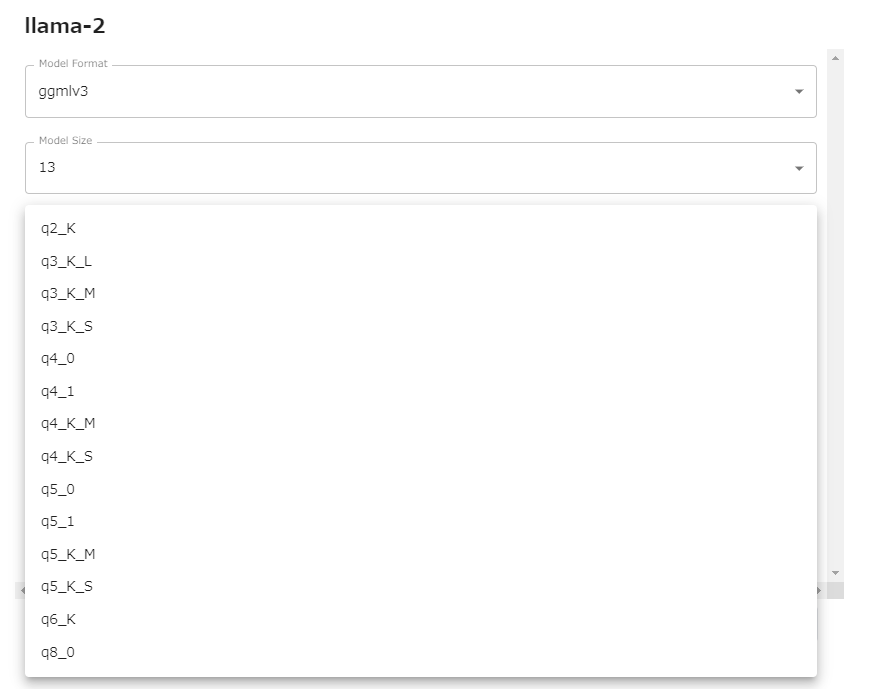
左下のロケットを押すとモデルのダウンロードが始まり、実行されます。
(2回目からはCachedと表示されてダウンロードは飛ばせます。)
実行中のモデルはRuuning Modelsから確認できます。
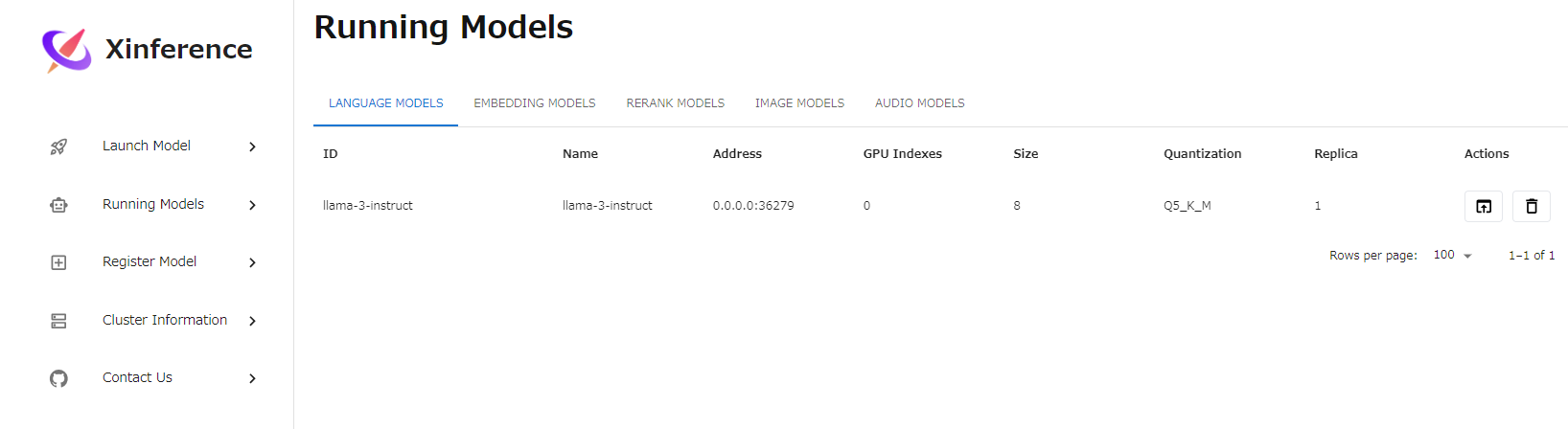
一覧にないモデルはRegister Modelから追加できます。
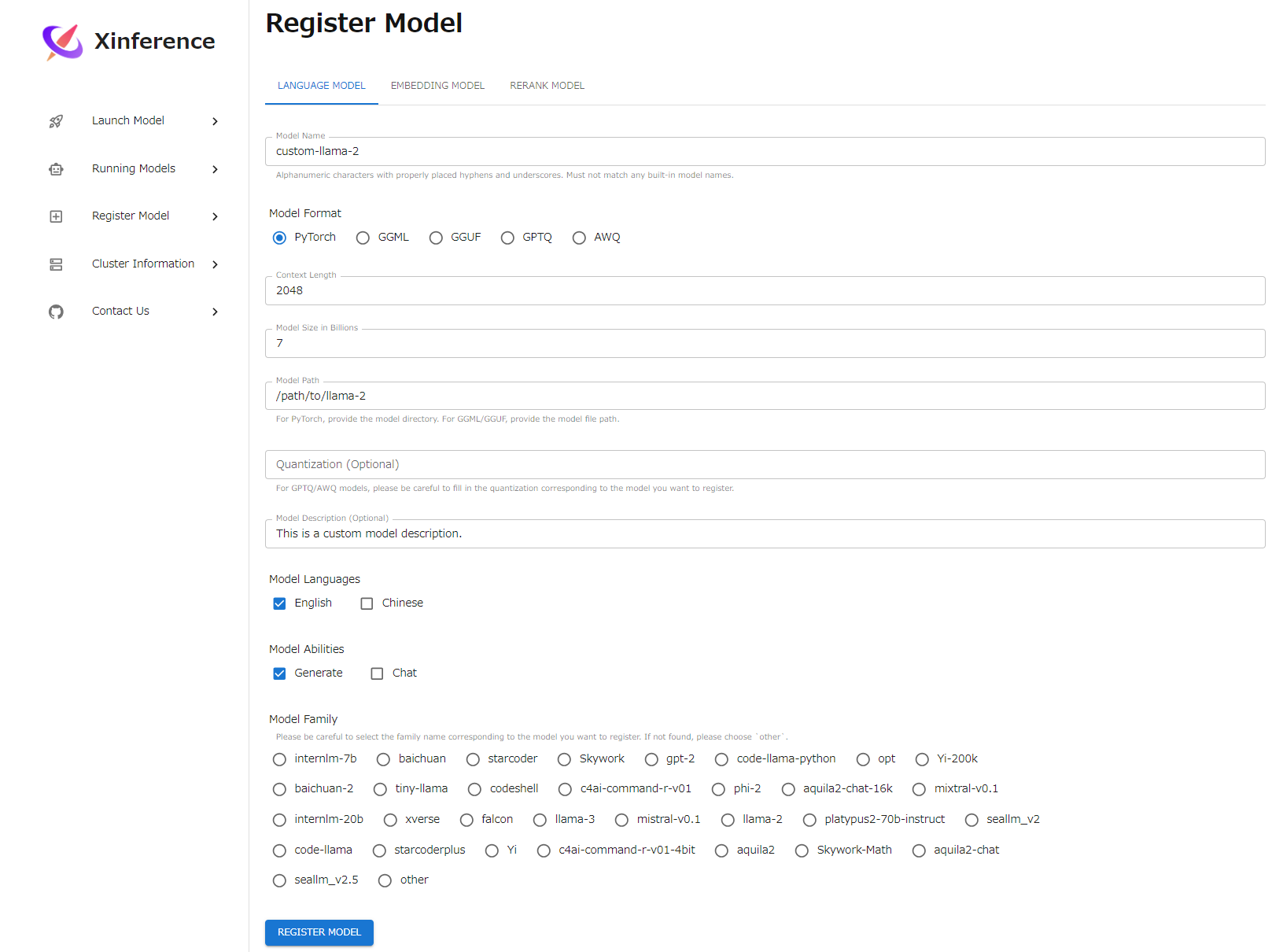
中国製だからか言語選択が英語と中国語しかありません。しかし、Lanch Modelにはenとzh以外のタグもあるので、内部的には他の言語も設定できる様ですし、llamaの様にenのみのモデルでも日本語が使えたりするので、あまり気にしなくても良さそうです。
CLIからモデルを起動することもできます。
例:
docker exec -it xinference xinference launch -n llama-3-instruct -f ggufv2 -s 8 -q Q5_K_M
docker exec -it xinference xinference launch -n bge-m3 -t embedding
docker exec -it xinference xinference launch -n bge-reranker-v2-m3 -t rerank
起動中のモデルは以下のコマンドで確認できます。
$ docker exec -it xinference xinference list
UID Type Name Format Size (in billions) Quantization
---------------- ------ ---------------- -------- -------------------- --------------
llama-3-instruct LLM llama-3-instruct ggufv2 8 Q5_K_M
UID Type Name Dimensions
------ --------- ------ ------------
bge-m3 embedding bge-m3 1024
UID Type Name
------------------ ------ ------------------
bge-reranker-v2-m3 rerank bge-reranker-v2-m3
チャット実行
Runnning ModelsからWeb UIを起動すると、チャットができます。お馴染みのGradioの画面ですね。
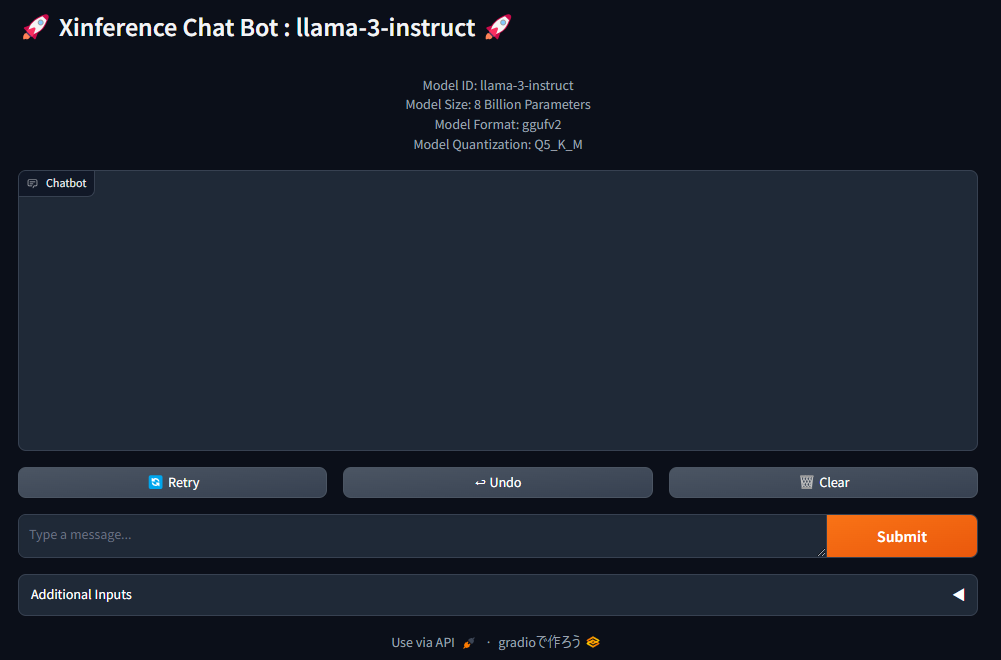
他にも、PythonやWeb APIから使う事ができます。詳しくは公式ドキュメントを参照してください。
まとめ
Xinferenceの使い方を紹介しました。これ単体ではただの良くあるLLMアプリですが、rerankモデルが使えるのでRAGアプリと組み合わせると効果的です。この辺は次回以降紹介していきたいと思います。