LlamaIndex + Amazon Neptune Analyticsを使ったGraphRAGを試してみました🙂
これまでグラフデータというものを聞いた事しかなかったのですが、先月のAWS Summit Japan 2024に参加した際、「Amazon Neptune Analytics と生成 AI 活用」というセッションを拝聴し、Amazon Neptune の新しいグラフ分析エンジン「Amazon Neptune Analytics」と、グラフデータを活用したRAGについて知りました。このセッションを通じて、GraphRAGとグラフデータに非常に興味を持ちました。
そこでLlamaIndexをまず試してみて、そこから様々なことを勉強していこうと考えました。GraphRAGの仕組みを理解するのに役立つ記事がありましたので、参考までにリンクを貼っておきます。
やってみる
GraphRAGを試してみる前に Amazon Bedrock for Knowledge baseでこれまでのRAGを試します。読ませるのは世界的漫画であるドラゴンボールの情報です💪
以下のコードでWikipediaからTXTファイルを取得します。
コード
import wikipedia
import os
wikipedia.set_lang("ja")
state = "ドラゴンボール"
directory = "./data"
short_summary = False
os.makedirs(directory, exist_ok=True)
try:
title = wikipedia.page(state).title.lower().replace(" ", "_")
content = (wikipedia.page(state).summary if short_summary else wikipedia.page(state).content)
content = content.strip()
filename = os.path.join(directory, f"{title}.txt")
with open(filename, "w", encoding="utf-8") as f:
f.write(content)
print(f"Saving {filename}")
except Exception:
print("Error")
続いて、Bedrock for Knowledge baseでRAGを構築します。やり方に関しては割愛します。
LLMのモデルはClaude 3 Sonnet v1
埋め込みモデルはTitan Embeddings G1 - Textv1.2 を使います。
構築後、少しいじわるな質問をしてみると、思ってる答えと違う答えが返ってきました。
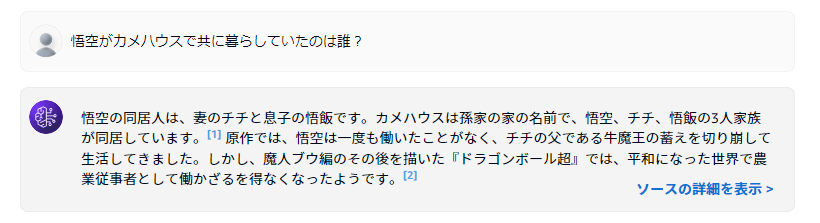
元のテキストファイルの文中には以下の文章が存在しているので正しく拾えていれば答えられそうです。
…
ドラゴンボール探しが終わったあと、後に親友となるクリリンとともに亀仙人に弟子入りする。ランチともこのときに知り合い、共々カメハウスで同居する。
…
LlamaIndex + Amazon Neptune Analytics
ここからは、こちらを参考に進めてみます。
環境は python 3.10, pip 24.1.2 です。Jupyter Notebookで検証を進めます。
pip install boto3
pip install llama-index-llms-bedrock
pip install llama-index-graph-stores-neptune
pip install llama-index-embeddings-bedrock
import wikipedia
import os
from llama_index.graph_stores.neptune import NeptuneAnalyticsGraphStore
from llama_index.core import StorageContext
from llama_index.core import load_index_from_storage
from llama_index.llms.bedrock import Bedrock
from llama_index.embeddings.bedrock import BedrockEmbedding
from llama_index.core import (
StorageContext,
SimpleDirectoryReader,
KnowledgeGraphIndex,
Settings,
)
from IPython.display import Markdown, display
import boto3
session = boto3.Session()
config = boto3.session.Config(region_name='us-east-1')
client = session.client('bedrock-runtime', config=config)
llm = Bedrock(
model="anthropic.claude-3-sonnet-20240229-v1:0",
)
embed_model = BedrockEmbedding(
model="amazon.titan-embed-text-v1",
)
Settings.llm = llm
Settings.embed_model = embed_model
Settings.chunk_size = 512
ドキュメントの読み込み
documents = SimpleDirectoryReader(input_dir="./data").load_data()
ImportError: llama-index-readers-file package not found というエラーに遭遇
pip install -U llama-index-readers-file をして解消
NeptuneAnalyticsGraphStoreを使います。
graph_store = NeptuneAnalyticsGraphStore(
graph_identifier="<graph_identifier>"
)
Neptune Analytics
Neptuneを検索 > Analytics > グラフを作成
- パブリック接続有効化: あり
- 他はデフォルトのまま作成
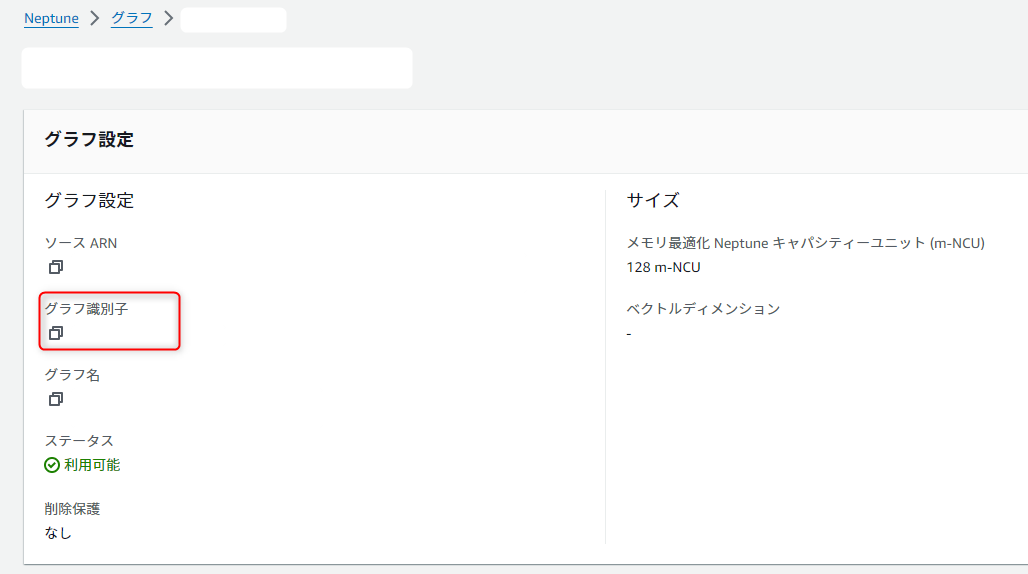
- グラフ識別子をコピー
KnowledgeGraphインデックス作成 ~ クエリ
storage_context = StorageContext.from_defaults(graph_store=graph_store)
# そこそこ時間かかる
index = KnowledgeGraphIndex.from_documents(
documents,
storage_context=storage_context,
)
インデックスに関連するデータを保存
index.storage_context.persist("./persist")
こちらはインデックスに関連する以下のJsonファイルが指定のディレクトリへ保存されます。作成したインデックスを再度利用するのに使うようです。
- default__vector_store.json: ドキュメントやノードのテキスト埋め込みベクトル
- docstore.json: ドキュメントやノードのメタデータと内容
- image__vector_store.json: 画像データの埋め込みベクトル
- index_store.json: インデックス全体の構造とメタデータ
それでは自然言語クエリをかけてみます。
query_engine = index.as_query_engine()
response = query_engine.query(
"悟空に友達とお嫁さんはいるの?"
)
display(Markdown(f"{response}"))
悟空には友達と妻がいます。
友達としては、クリリン、ヤムチャ、天津飯などが挙げられます。
特にクリリンとは幼なじみで親友となり、様々な冒険を共にしています。
妻はチチで、二人の間には長男の悟飯と次男の悟天がいます。
チチは悟空が亀仙人の元で修行していた際に出会い、後に結婚しました。
チチは悟空が戦いばかりしていることに不満を持っていましたが、最終的には悟空の生き方を受け入れています。
回答は良好です!
次に先程は答えられなかった質問を投げてみます。
query_engine = index.as_query_engine()
response = query_engine.query(
"悟空がカメハウスで共に暮らしていたのは誰?"
)
display(Markdown(f"{response}"))
悟空がカメハウスで共に暮らしていたのは、ランチとクリリンです。
コンテキストの情報から、「ランチともこのときに知り合い、共々カメハウスで同居する。」と記載されています。
こちらも想定していた回答が得られました!🙌
作成したインデックスを再利用する場合は from_defaultsメソッドで保存したインデックス情報を読み込み、 load_index_from_storage関数を使ってロードするようです。
graph_store = NeptuneAnalyticsGraphStore(graph_identifier="<graph_identifier>")
storage_context = StorageContext.from_defaults(
graph_store=graph_store,
persist_dir="./persist"
)
load_index = load_index_from_storage(storage_context=storage_context)
コンテキストに無い質問をしてみます。
query_engine = load_index.as_query_engine()
response = query_engine.query(
"ザーボンさんって誰?"
)
display(Markdown(f"{response}"))
申し訳ありませんが、提供された情報からはザーボンさんについての詳細が分かりませんでした。
この方について説明するための関連情報がないようです。
そうか...ザーボンさんを知らないのか...
足りない情報をウィキペディアから取得します。
コード
import wikipedia
wikipedia.set_lang("ja")
state = "ザーボンさん フリーザ"
directory = "./data"
short_summary = False
os.makedirs(directory, exist_ok=True)
try:
title = wikipedia.page(state).title.lower().replace(" ", "_")
content = (
wikipedia.page(state).summary
if short_summary
else wikipedia.page(state).content
)
content = content.strip()
filename = os.path.join(directory, f"{title}.txt")
with open(filename, "w", encoding="utf-8") as f:
f.write(content)
print(f"Saving {filename}")
except Exception:
print(f"Error!")
データを追加してインデックスを更新する場合は、refresh_ref_docsというメソッドが使えそうでしたので試してみます。
new_documents = SimpleDirectoryReader(input_dir="./data").load_data()
load_index.refresh_ref_docs(
documents=new_documents,
storage_context=storage_context,
)
# save refresh_graph index data
load_index.storage_context.persist("./persist")
これもそこそこ時間がかかりました。(もっといい方法があるのかもしれません...)
完了したら再度質問をしてみます。
query_engine = load_index.as_query_engine()
response = query_engine.query(
"ザーボンさんって誰?"
)
display(Markdown(f"{response}"))
ザーボンはフリーザの側近で、情報分析力に長けた参謀的な役割を担っていました。
冷静沈着な性格で、フリーザに忠実に仕えていた宇宙人です。
変身する能力を持ち、変身すると爬虫類のような風貌になり、戦闘力が大幅に上がります。
ナメック星でベジータと戦い、最終的にベジータに敗れて命を落としました。
期待していた回答が得られました!👏
さいごに
Amazon Neptuneを初めて使ってみました。
正直、グラフデータ自体をちゃんと勉強していかないとよく分からない事が多いのですが、とても興味が湧いたので継続して試行錯誤しながら勉強していこうと思います。
最後までご覧いただきありがとうございました!