本記事は2024年2月段階のAutonomous Database および Open AI GPT3.5を使用したものです。Select AI で生成したSQLについて出力が含まれますが、同様の結果を保証するものではございません。
Select AI 機能に関して、自然言語からどのようなSQLが作成されるのか、どのような操作で制御できたのかを共有します。
検証にはOracle LiveLabsで提供されている Select AIのデモ環境を使用しています。構築については以下を参照ください。
Oracle LiveLabs: Run Workshop - Chat with Your Data in Autonomous Database Using Generative AI
記事内容:
- 前提の確認
- 基本的な動作の確認
- 条件の制御① - 固有名詞の言語変換
- 条件の制御② - 属性の制御
■1.前提の確認
以下の作成済みAIプロファイルで検証
BEGIN DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name => 'openai_gpt35',
attributes =>
'{"provider": "openai",
"credential_name": "OPENAI_CRED",
"object_list": [{"owner": "MOVIESTREAM", "name": "movies"},
{"owner": "MOVIESTREAM", "name": "streams"},
{"owner": "MOVIESTREAM", "name": "customer"},
{"owner": "MOVIESTREAM", "name": "actors"},
{"owner": "MOVIESTREAM", "name": "genre"},
{"owner": "MOVIESTREAM", "name": "customer_segment"},
{"owner": "MOVIESTREAM", "name": "customer_contact"}
]
}'
);
END;
/
OPENAIのgpt-35に対して以下のオブジェクトを使ってSQLを作成させます。
| 表 | 含まれる情報(ざっくり) |
|---|---|
| movies | 映画ID/タイトル/公開日/予算/売上/スタッフ/スタジオ/映画のサマリ |
| streams | 映画ID/顧客ID/ジャンルID/stream環境/視聴回数/支払方法/支払金額 |
| customer | 顧客ID/顧客セグメントID/氏名/メールアドレス/住所(大陸,国,州,市)/年齢/性別/婚姻状況/学歴/雇用形態 |
| actors | 映画ID/俳優名 |
| genre | ジャンルID/ジャンル名 |
| customer_segment | 顧客セグメントID/顧客セグメント名/セグメント短縮名 |
| customer_contact | 顧客ID/氏名/メールアドレス/住所(大陸,国,州,市) |
■2. 日本語での動作の確認
まずは、簡単なデータの抽出を実行します。
「映画のジャンルの一覧」
-
出力:

※最初の10行のみが出力され、データを見る場合はExplore, SQLを見る場合はExplainをクリックします。 -
データ(Explore)
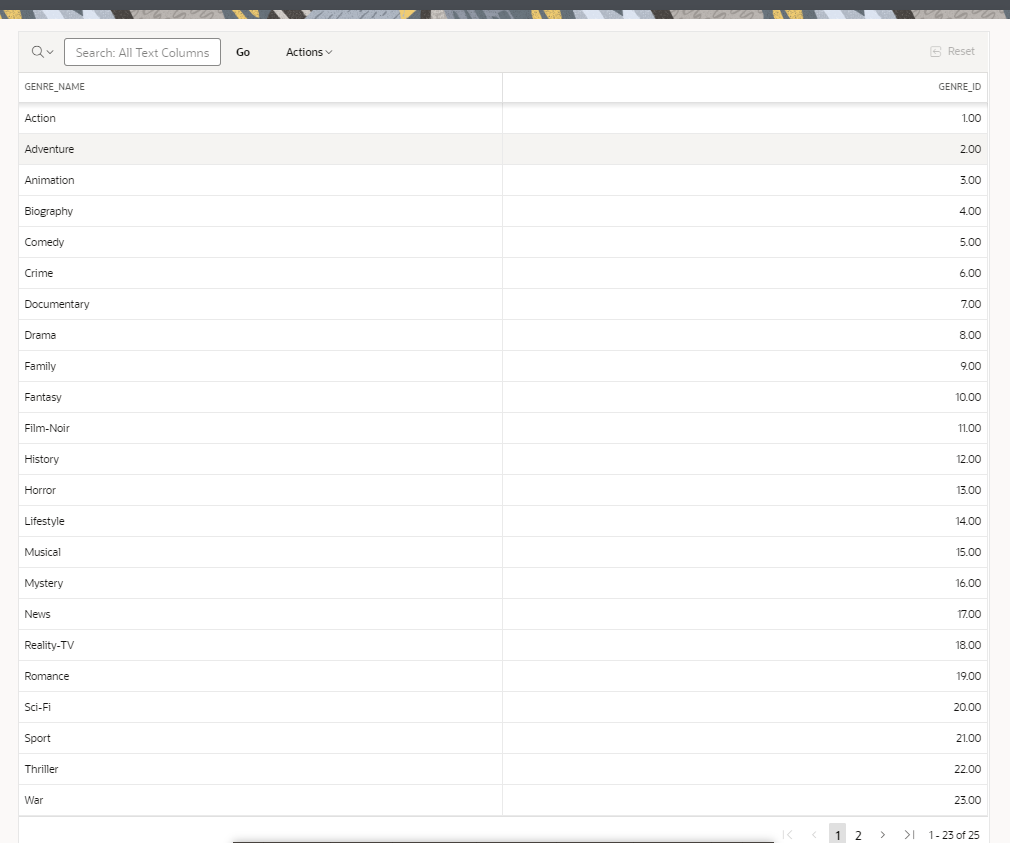
-SQL(Explain)
SELECT g.GENRE_ID, g.NAME AS GENRE_NAME
FROM MOVIESTREAM.GENRE g
GENRE表からGENRE_IDとNAME列を抽出し、ジャンル名を聞いているため、NAME列をGENRE_NAMEに変換しています。
次は俳優を起点に映画の売上状況を聞いてみます。
「ジョニーデップが出演している映画の総売上の上位3作品を教えて」
- 出力

ファンタスティックビーストシリーズの2作品、パイレーツオブカリビアンシリーズから1作品が抽出されました。どのようなロジックでデータが抽出されたかをSQLを見ていきます。
- SQL
SELECT m.TITLE, SUM(s.SALES) AS TOTAL_SALES
FROM MOVIESTREAM.MOVIES m
JOIN MOVIESTREAM.ACTORS a ON m.MOVIE_ID = a.MOVIE_ID
JOIN MOVIESTREAM.STREAMS s ON m.MOVIE_ID = s.MOVIE_ID
WHERE a.ACTOR = 'Johnny Depp'
GROUP BY m.TITLE
ORDER BY TOTAL_SALES DESC
FETCH FIRST 3 ROWS ONLY
MOVIE表のTITLE列および総売上として、MOVIES_STREAM表のSALES列をTITLE別に集計を抽出し、俳優が'Johnny Depp'である映画のみを、売上順に3作品を抽出するSQLです。
総売上というキーワードによりSUM関数を使用してくれますが、総売上ではなく売上とした場合にSUM関数が使用されず、SALES列を単純に抽出に比較するようなSQLになりました。
SELECT m.TITLE, s.SALES
FROM MOVIESTREAM.MOVIES m
JOIN MOVIESTREAM.ACTORS a ON m.MOVIE_ID = a.MOVIE_ID
JOIN MOVIESTREAM.STREAMS s ON m.MOVIE_ID = s.MOVIE_ID
WHERE a.ACTOR = 'Johnny Depp'
ORDER BY s.SALES DESC
FETCH FIRST 3 ROWS ONLY
■3. 条件の制御① - 固有名詞の言語変換
前項に確認したSQLは、カタカナでジョニーデップと記載したものをAIにて'Johnny Depp'と変換されたこと、列値が英語で格納されているという条件が合わさったため、データの抽出ができました。
SELECT AIではAIプロファイルでオブジェクト情報を生成AIに渡しますが、実データは渡しませんので、AIからみるとどのようなデータが入っているか判別できない状態でSQLを生成しています。そのため利用者側が人名などの固有名詞に関してWHERE句の制御がどのように行われるか把握する必要があると考えて動作検証してみました。
- カタカナ語をそのまま聞いてみる
質問を「"ジョニーデップ"が出演している映画の総売上の上位3作品を教えて」と記載することで、AIによる’Johnny Depp’への変換を回避できました。
- SQL
SELECT m.TITLE, SUM(s.SALES) AS TOTAL_SALES
FROM MOVIESTREAM.MOVIES m
JOIN MOVIESTREAM.ACTORS a ON m.MOVIE_ID = a.MOVIE_ID
JOIN MOVIESTREAM.STREAMS s ON m.MOVIE_ID = s.MOVIE_ID
WHERE a.ACTOR = 'ジョニーデップ'
GROUP BY m.TITLE
ORDER BY TOTAL_SALES DESC
FETCH FIRST 3 ROWS ONLY
※ACTOR列には俳優名が英語で入っているため、データは抽出できません。
- 漢字で聞いてみる
次に日本人俳優の真田広之さんを条件に上位3作品を聞いてみます。
「真田広之が出演している映画の総売上の上位3作品を教えて」
- 出力

※データが1件も抽出できていません。 - SQL
SELECT m.TITLE AS MOVIE_TITLE, SUM(s.SALES) AS TOTAL_SALES
FROM MOVIESTREAM.MOVIES m
JOIN MOVIESTREAM.ACTORS a ON m.MOVIE_ID = a.MOVIE_ID
JOIN MOVIESTREAM.STREAMS s ON m.MOVIE_ID = s.MOVIE_ID
WHERE a.ACTOR = '真田広之'
GROUP BY m.TITLE
ORDER BY TOTAL_SALES DESC
FETCH FIRST 3 ROWS ONLY
真田広之さんは漢字だからでしょうか、そのまま変換せずにWhere句に使用されています。"Hiroyuki Sanada"で質問をしたところ、そのまま検索され適切なデータを取得することができました。
- 参考

■4. 条件の制御② - 属性の変換
次に固有名詞ではなく、属性によるデータ抽出がどの程度できるかを見ていきます。
まずは会員の性別に関して適切な情報を取得できるかを見てみます。
「顧客の性別の割合」
-
出力

-
SQL
SELECT
COUNT(*) AS total_customers,
SUM(CASE WHEN GENDER = 'Male' THEN 1 ELSE 0 END) AS male_customers,
SUM(CASE WHEN GENDER = 'Female' THEN 1 ELSE 0 END) AS female_customers,
SUM(CASE WHEN GENDER IS NULL THEN 1 ELSE 0 END) AS unknown_gender_customers,
(SUM(CASE WHEN GENDER = 'Male' THEN 1 ELSE 0 END) / COUNT(*)) * 100 AS male_percentage,
(SUM(CASE WHEN GENDER = 'Female' THEN 1 ELSE 0 END) / COUNT(*)) * 100 AS female_percentage,
(SUM(CASE WHEN GENDER IS NULL THEN 1 ELSE 0 END) / COUNT(*)) * 100 AS unknown_gender_percentage
FROM MOVIESTREAM.CUSTOMER
CUSTOMER表のGENEDER列から情報を取得し、性別から男性='Male'、女性='Female'およびその他という属性を作成して、検索条件を作ってくれています。
では聞き方を変えて以下の質問にした場合どうなるでしょうか。
「顧客のうち男性顧客と女性顧客の割合」
-
出力

-
SQL
SELECT
COUNT(CASE WHEN GENDER = '男性' THEN 1 END) AS male_count,
COUNT(CASE WHEN GENDER = '女性' THEN 1 END) AS female_count,
COUNT(*) AS total_count,
ROUND(COUNT(CASE WHEN GENDER = '男性' THEN 1 END) / COUNT(*) * 100, 2) AS male_percentage,
ROUND(COUNT(CASE WHEN GENDER = '女性' THEN 1 END) / COUNT(*) * 100, 2) AS female_percentage
FROM MOVIESTREAM.CUSTOMER
明示的に男性、女性という属性を明記した場合にそれが条件にそのまま使用されていることが確認できます。
聞き方によって、検索条件にブレが出てしまい、適切な検索ができるケースとできないケースが出てしまっています。そのため、以下コマンドでGENDER列にコメントを追記します。
comment on column customer.gender is '性別を格納します。男性は"Male"、女性は"Female"です'
コメントを追記後に再実行すると結果が変わります。
-
出力

-
SQL
SELECT
COUNT(CASE WHEN c.GENDER = 'Male' THEN 1 END) AS male_customers,
COUNT(CASE WHEN c.GENDER = 'Female' THEN 1 END) AS female_customers,
COUNT(*) AS total_customers,
(COUNT(CASE WHEN c.GENDER = 'Male' THEN 1 END) / COUNT(*)) * 100 AS male_percentage,
(COUNT(CASE WHEN c.GENDER = 'Female' THEN 1 END) / COUNT(*)) * 100 AS female_percentage
FROM
MOVIESTREAM.CUSTOMER c
CUSTOMER表のGENDER列から男性='Male'、女性='Female'として人数のカウントと割合のパーセンテージを抽出できました。条件が適切に設定されています。
では類似の検索として、顧客の婚姻状況を独身または既婚で検索しようとするとどうなるかを見ていきます。
「顧客の婚姻状況の割合」
-
出力
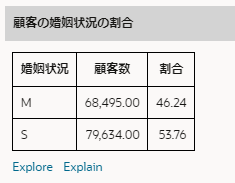
-
SQL
SELECT
MARITAL_STATUS AS "婚姻状況",
COUNT(*) AS "顧客数",
ROUND(COUNT(*) * 100 / (SELECT COUNT(*) FROM MOVIESTREAM.CUSTOMER), 2) AS "割合"
FROM
MOVIESTREAM.CUSTOMER
GROUP BY
MARITAL_STATUS
婚姻状況についてCUSTOMER表のMARITAL_STATUSから値別に集計、割合を出しています。MARITAL_STATUS列の値に関わらずデータを取得できるSQLになっています。
それでは性別と同様に独身、既婚という聞き方をするとどうなるかを見てみます。
「顧客のうち独身者と既婚者の割合」
-
出力

-
SQL
SELECT
COUNT(CASE WHEN MARITAL_STATUS = 'Single' THEN 1 END) AS single_count,
COUNT(CASE WHEN MARITAL_STATUS = 'Married' THEN 1 END) AS married_count,
COUNT(*) AS total_count,
ROUND(COUNT(CASE WHEN MARITAL_STATUS = 'Single' THEN 1 END) / COUNT(*) * 100, 2) AS single_percentage,
ROUND(COUNT(CASE WHEN MARITAL_STATUS = 'Married' THEN 1 END) / COUNT(*) * 100, 2) AS married_percentage
FROM MOVIESTREAM.CUSTOMER
婚姻状況を独身='Single'、既婚を'Married'に変換してSQLを実行していますが、実際に格納されているデータは独身='S'、既婚='M'なのでデータの抽出ができません。
属性値の変換がうまくいっていないため、こちらも列にコメント情報を追加します。
comment on column customer.marital_status is '婚姻状況を格納します。既婚者は"M"独身者は"S"です'
コメントを追記後に再実行すると、属性値が制御され、SQLの内容が変わります。
-
出力

-
SQL
SELECT
COUNT(CASE WHEN c.MARITAL_STATUS = 'M' THEN 1 END) AS married_count,
COUNT(CASE WHEN c.MARITAL_STATUS = 'S' THEN 1 END) AS single_count,
COUNT(*) AS total_count,
ROUND(COUNT(CASE WHEN c.MARITAL_STATUS = 'M' THEN 1 END) / COUNT(*) * 100, 2) AS married_percentage,
ROUND(COUNT(CASE WHEN c.MARITAL_STATUS = 'S' THEN 1 END) / COUNT(*) * 100, 2) AS single_percentage
FROM MOVIESTREAM.CUSTOMER c
上記動作から、Select AIで属性を含む適切なSQLを作成するためには、特定の値を指定せずに質問をする、もしくは列コメントに事前に格納されている値と意味について格納することが必要になると考えられます。
とはいえ、属性については格納されている値の表記のブレで適切なデータが取れない可能性もあるので、まずは広く情報をとり、結果を受け取ったユーザー側で、条件を絞り込むなどの工夫が必要になると考えられます。
■まとめ
Select AIではデータの抽出や集計などのSQLを簡単に作成、結果を得ることができますが、固有名詞や属性を条件に使った絞り込みでは、生成AI側での変換もありうまくデータが取れないケースも確認できました。
有効活用いただくために、データ提供者側でのメタデータの整備、ユーザー側での使い方、聞き方は整備いただく必要があると考えます。